
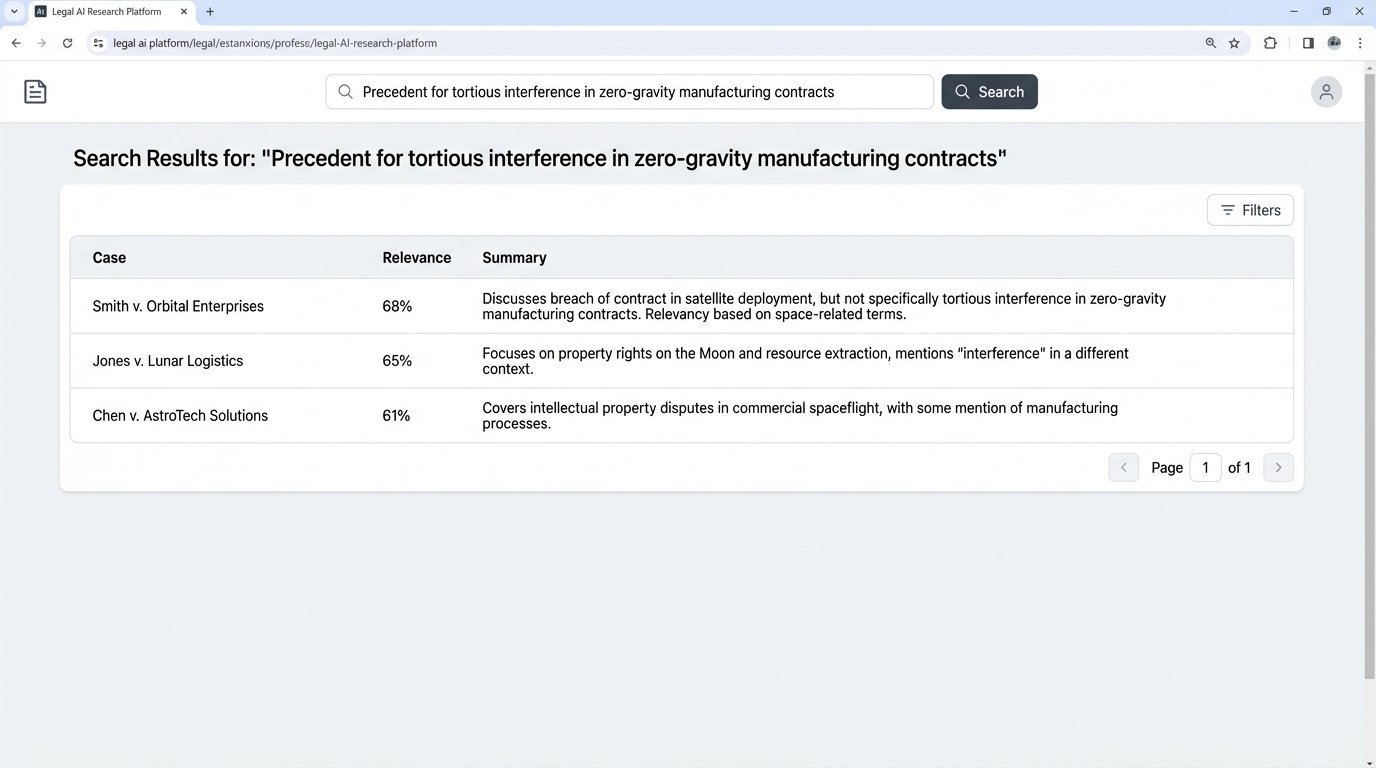
The core function of most legal AI research platforms is not legal reasoning. It is vector search. A query is converted into a numerical representation and fired against a pre-indexed database of case law to find documents with similar numerical patterns. The system is not understanding precedent; it is performing high-speed statistical matching based on term proximity and frequency.
This is a brute-force data retrieval mechanism, not a cognitive partner. Expecting it to craft a novel legal argument is a fundamental misunderstanding of the technology stack. The real conversation is not about replacing attorneys but about defining the correct operational boundaries for these query engines.
The Mechanics of Machine-Driven Research
When an attorney types a query into a so-called AI research tool, the backend process is predictable. The natural language input is passed to an embedding model, which strips it of nuance and converts it into a high-dimensional vector. This vector, a long list of numbers, represents the query’s position in a conceptual space. The system then executes a similarity search, typically using a cosine similarity algorithm, against its vast, pre-computed vector database of legal documents.
The documents returned are simply those whose vectors are mathematically closest to the query vector. It’s a geometric calculation. A Retrieval-Augmented Generation (RAG) layer might then take the top results, inject them into a prompt for a Large Language Model (LLM), and generate a human-readable summary. This architecture gives the illusion of comprehension, but it is a mechanical process of retrieval followed by summarization. The LLM has no inherent knowledge of the law; it only has the context it was fed seconds before generating the text.
This entire process is like trying to assemble a complex engine using only a magnet. You can drag a lot of metal parts into a pile, and some of them will be the right ones, but the magnet has no concept of a piston, a crankshaft, or how they must connect. It just pulls things that look like other things.
Hallucinations are not a bug in this system; they are a direct consequence of its design. LLMs are engineered to produce plausible sequences of text based on probabilistic patterns. If the retrieved context is weak or ambiguous, the model will fill the gaps with statistically likely, yet factually incorrect, information. It will invent case citations that look real because it has learned the pattern of how a real citation is structured. It is not lying; it is just completing a pattern without a validation layer.
The Analog Protocol for Jurisprudence
Human legal research does not follow a linear query-and-response path. It is an iterative, branching process of hypothesis and refutation. An associate begins not with a keyword search, but with a theory of the case. The initial research is designed to either validate or invalidate that primary theory. The results dictate the next branch of inquiry, which may diverge entirely from the original path.
This method values negative space. Discovering the complete absence of case law supporting a certain position is a powerful piece of information. It informs strategy, signaling that a novel argument must be constructed or that a particular line of reasoning is a dead end. An AI cannot confidently report a null result. Its architecture is biased towards finding a match, however tenuous. It will return the “least wrong” answer from its database, polluting the research pool with low-relevance documents that a human would have discarded in seconds.
Senior attorneys synthesize information from disparate domains. They might connect a precedent from contract law to a burgeoning issue in data privacy, recognizing an analogous principle that an algorithm, confined to its training data, could never see. This is the application of mental models, not keyword matching. It involves understanding judicial intent, the subtext of a ruling, and the political or commercial pressures that shaped a decision. These are data points that do not exist in the text of the opinion itself and are therefore invisible to any model that can only parse text.
The human protocol is built to reduce a wide universe of information down to a single, defensible point. The AI protocol is built to expand a single query into a list of probable, but unverified, documents.
Systemic Failure Points in Automated Lookups
The operational risk of relying on AI for substantive legal research comes down to data integrity and the model’s inherent lack of context. These are not problems that can be solved with a bigger model or more training data. They are architectural limitations.
Corpus Contamination and Outdated Precedents
The vector databases that power these tools are immense, but they are not clean. Ingesting millions of court documents means pulling in overruled cases, amended statutes, and lower court decisions that were later overturned. A well-designed system might attempt to flag these, but the process is imperfect. An LLM, tasked with summarizing retrieved documents, has no mechanism to cross-reference a case’s current validity. It will present an overruled precedent with the same confident tone as a landmark Supreme Court ruling.
This creates a minefield for the unsuspecting associate. The AI can produce a perfectly structured, well-written summary based on bad law. Unless every single source is manually verified, the risk of embedding a fatal flaw into a brief is unacceptably high.
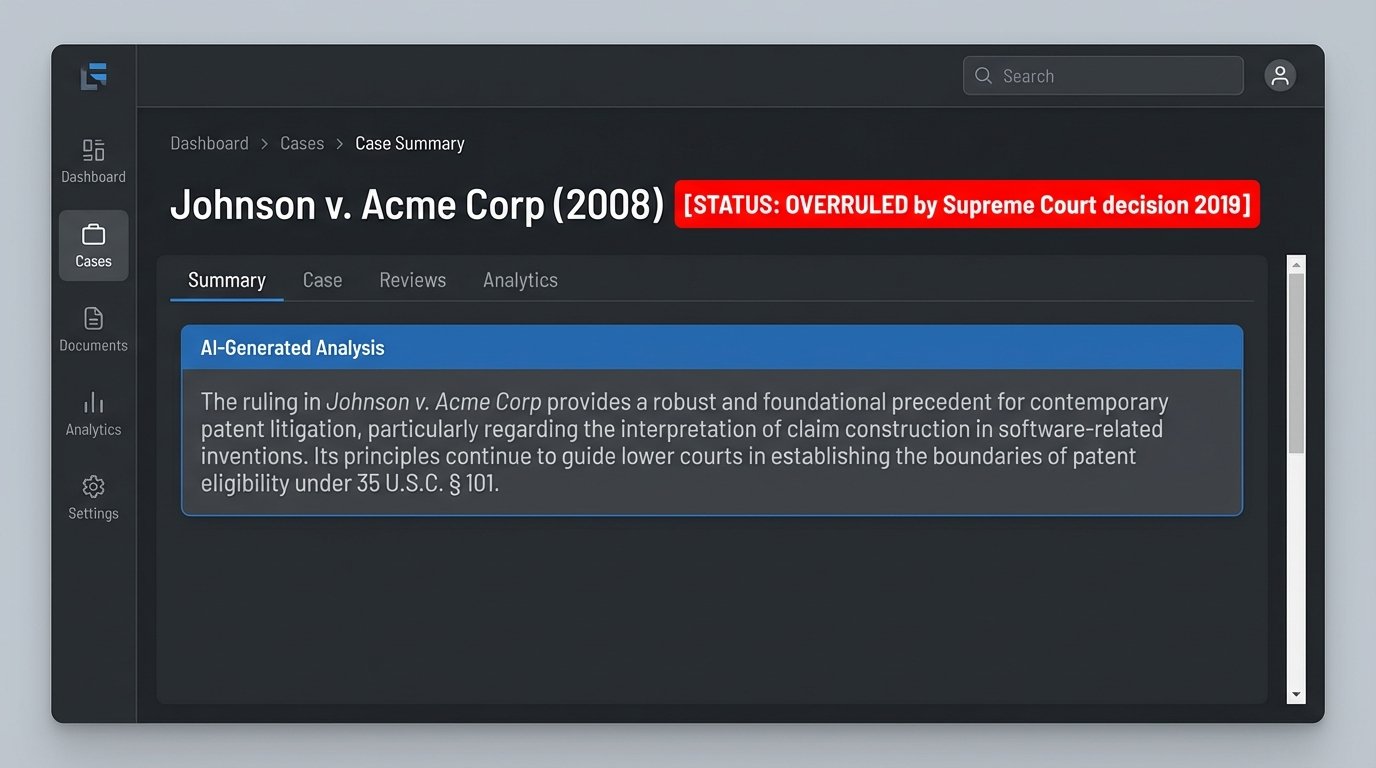
The problem is compounded by the speed of legislation. A statute that was valid when the model’s training data was last updated may have been amended or repealed. Real-time validation against legislative databases is computationally expensive and not a standard feature in many commercial offerings. The user is operating with a time-delayed, potentially corrupted dataset.
The Nuance Blind Spot
Legal strategy often hinges on understanding the unwritten rules of a jurisdiction. Is a particular circuit known for being hostile to certain types of motions? Does a specific judge have a well-documented preference for arguments grounded in textualism over legislative intent? This meta-knowledge is critical for effective advocacy. It is gathered through experience, industry chatter, and careful reading between the lines of dozens of rulings.
An AI has access to none of this. It cannot detect a judge’s sarcasm in a footnote or recognize the strategic importance of a carefully worded concurrence. It processes all text with equal weight. For an algorithm, the furious dissent from a respected judge holds the same data value as boilerplate procedural text. This context-blindness makes it incapable of advising on strategy. It can retrieve facts, but it cannot provide wisdom.
The Black Box and Malpractice
When an attorney submits a brief, they are professionally liable for its contents. If that brief contains a fabricated case citation generated by an LLM, the fault lies with the attorney, not the software vendor. The terms of service for every major AI platform make this explicitly clear. You cannot cross-examine an algorithm to understand its reasoning.
This “black box” problem presents a direct malpractice risk. The inability to audit the AI’s “thought process” means you are accepting its output on faith. For non-critical tasks like summarizing a deposition, this risk may be acceptable. For the core legal argument that a multi-million dollar case rests on, it is an irresponsible gamble.
Forcing a Functional Integration
A blanket rejection of this technology is as foolish as its blind adoption. The correct approach is to dismantle the “AI research” concept into its component functions and deploy them at appropriate stages of the legal workflow. We force the technology into a subordinate role as a high-speed data-gathering tool, controlled by human legal strategists.
This hybrid architecture treats the AI not as a thinker, but as a tireless, infinitely fast paralegal with poor judgment. The workflow is structured to exploit its strengths while quarantining its weaknesses.
- Step 1: Broad-Spectrum Canvassing. An associate uses an AI tool to perform the initial, wide-net research. The goal is not to find the answer, but to rapidly identify the entire universe of potentially relevant case law, statutes, and secondary sources for a given legal issue. The prompts are designed to be broad, and the output is treated as a raw, unverified data dump. This replaces days of manual searching with a few hours of query refinement.
- Step 2: Human-Driven Pruning and Analysis. The attorney takes the AI-generated list and begins the real legal work. They cull irrelevant results, identify the controlling precedents, and read the key cases in full. The AI’s output is the starting block, not the finish line. It is during this stage that the core legal argument is formed, based on the attorney’s expertise and interpretation.
- Step 3: Targeted Fact-Finding and Citation. Once the argument is structured, the AI can be used for highly specific, closed-ended questions. For example, “Find all cases in the Ninth Circuit from the last five years that cite Marbury v. Madison on the topic of judicial review.” This is a lookup task, not a reasoning task, and plays to the strengths of vector search.
- Step 4: Mechanical Validation. Finally, specialized AI tools, not broad LLMs, are used for rote tasks. A citation checker can validate Bluebook formatting. A document analysis tool can check for inconsistent definitions or terms within a brief. These tasks are mechanical and have a low tolerance for error, making them suitable for automation.
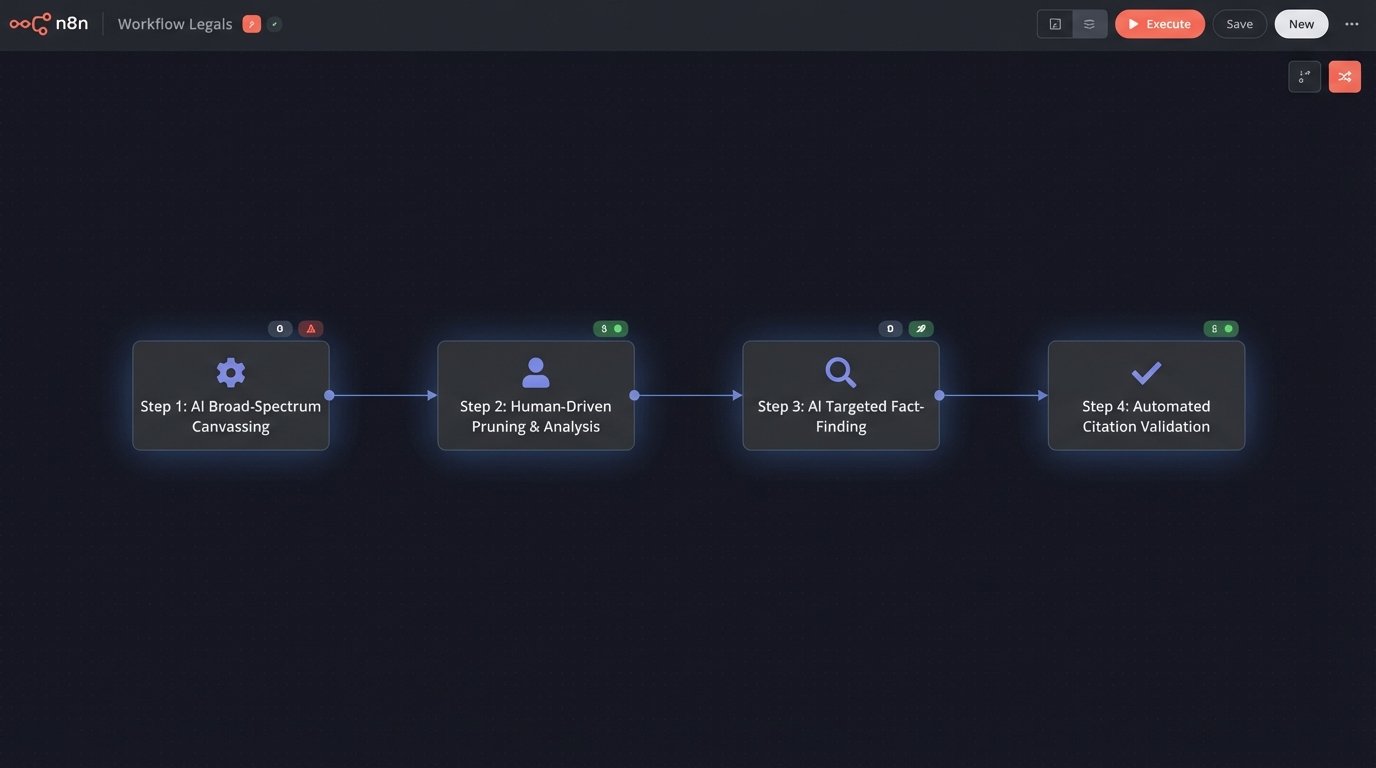
This segregated workflow maintains attorney oversight at all critical decision points. It leverages machine speed for data retrieval while reserving cognitive and strategic work for the human expert.
The Stack That Does not Burn You
Choosing the right tools requires looking past the marketing copy and examining the architecture. A general-purpose LLM, accessed via API, is a powerful text generator but a terrible legal researcher. Its knowledge is broad but shallow, and its data sources are often opaque. You are piping raw power into your workflow with few safety controls.
Domain-specific platforms, built by legal tech companies, are often a better choice. They typically use models fine-tuned on curated legal corpora and build their systems around RAG to ground the output in specific, verifiable sources. The critical feature to demand is source-linking. Any assertion the AI makes must be directly linked to the specific sentence in the source document it came from. Without that, you are working with an untrustworthy system.
The goal is not to buy a magic box that “does research.” The goal is to build a process that uses specific tools to accelerate discrete steps. It is about augmenting the capabilities of your legal team, not attempting to replace their judgment. The associate who learns how to force these tools to do the tedious 80% of data collection will be far more valuable than the one who still does it manually. Their time is freed up to focus on the strategic work that clients actually pay for.