
Most AI-powered legal research platforms are marketed as oracles. They are not. They are complex statistical models designed to predict the next word in a sequence, a function that makes them prone to fabricating case law with unshakable confidence. Effective use is not about asking better questions. It is about building a rigid, verifiable workflow that forces the model to ground its output in a verified data corpus, stripping away its ability to invent facts.
The core failure of adopting these tools is treating them like a search engine. A search engine indexes and retrieves. A large language model generates new content based on patterns. Injecting raw, unstructured queries into these systems is like pushing unstructured data into a relational database. The schema will reject it or, worse, produce garbage.
Grounding the Workflow: Before You Query
Initial setup dictates the quality of every subsequent output. Skipping a thorough analysis of the underlying model architecture and data sources is the most common point of failure. You must know what kind of engine you are working with and the fuel it runs on before you turn the key. Otherwise, you are just hoping for the best.
Selecting the Right Tool: RAG vs. Fine-Tuned Models
The primary distinction you need to care about is whether the tool uses Retrieval-Augmented Generation. RAG-based systems first retrieve relevant documents from a known, private database and then use a language model to synthesize an answer based *only* on those documents. This constrains the model and drastically reduces hallucinations. A general-purpose, fine-tuned model has simply been trained on a larger legal dataset, but it still generates answers from its internal weights and has no direct link to a verifiable source for any given query. It is a closed box.
For verifiable research, RAG is the only acceptable architecture. Fine-tuned models might be faster for generating contract clauses from a template, but for case law analysis, they are a liability. The cost model is also inverted. A RAG system’s expense is in maintaining and indexing the proprietary database, a massive engineering lift. A fine-tuned model’s expense is the initial, wallet-draining training process.
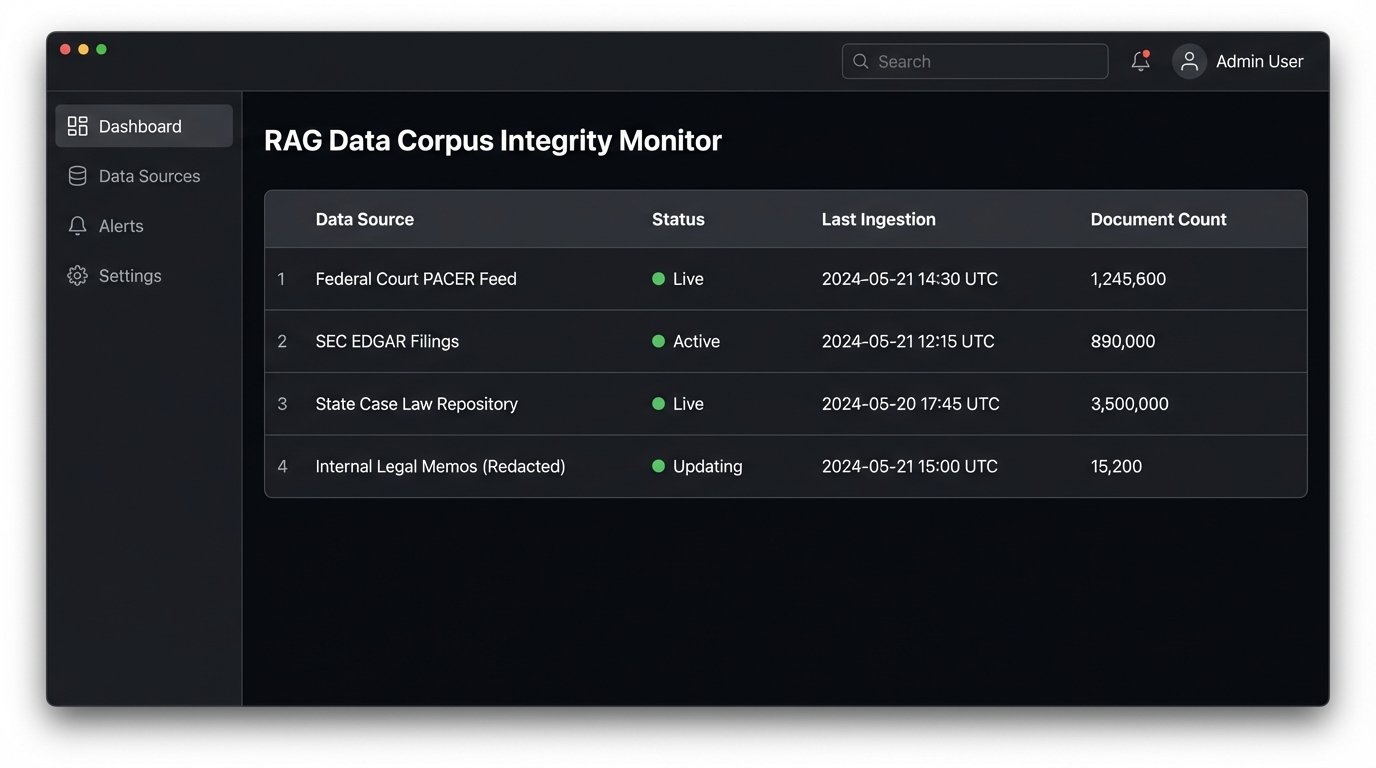
Data Corpus Integrity Check
A RAG system is worthless if its retrieval database is stale or incomplete. Before committing to any platform, you must demand documentation on their data ingestion pipeline. What are the specific sources? How frequently are they updated? Is the update process automated or does it rely on a human operator who might take a vacation? You need to know if you are searching against yesterday’s court filings or last quarter’s.
Ask for the edge cases. Does the corpus include unpublished opinions, administrative rulings, or secondary sources? Many providers will advertise a total document count, but that number is meaningless without a qualitative breakdown. A million irrelevant documents are worse than a hundred thousand relevant ones, as they just add noise to the retrieval step and poison the final output.
Query Formulation as a System Command
Once you have a vetted tool, you must abandon natural language. Chat-based interfaces are a convenient fiction. To get reliable, repeatable results, you must structure your queries with the precision of a database call. You are not conversing with a colleague. You are providing parameters to a function.
The Anatomy of a Non-Ambiguous Query
A strong query is not a sentence. It is a structured object containing key-value pairs that define the search space. You must explicitly define the jurisdiction, the relevant timeframe, the specific legal issue, and the core facts. This forces the retrieval part of the RAG system to pull a narrow, highly relevant set of documents before the language model even sees the prompt.
Consider the difference. A weak, natural-language query is: “What is the standard for summary judgment in California for a slip and fall case?” A structured query bypasses the model’s need to interpret your intent. It is a direct command.
Here is a simplified example of how to frame the query data, perhaps as a JSON object you would hypothetically send to an internal API endpoint that wraps the vendor’s tool:
{
"query_type": "case_law_analysis",
"jurisdiction": {
"court_type": "state",
"state": "CA",
"court_level": ["supreme", "appellate"]
},
"date_range": {
"start": "2018-01-01",
"end": "2023-12-31"
},
"legal_issue": {
"topic": "summary judgment",
"sub_topic": "standard of review",
"keywords": ["triable issue", "material fact", "burden of proof"]
},
"fact_pattern": {
"incident_type": "premises liability",
"specifics": ["slip and fall", "commercial property", "transitory substance", "constructive notice"]
},
"output_constraints": {
"format": "synthesis_with_citations",
"max_sources": 10,
"cite_style": "bluebook"
}
}
This structure leaves no room for ambiguity. It tells the system exactly what to find and how to present it. You have already performed the first layer of filtering before the AI begins its synthesis.
Iterative Refinement and Negative Constraints
Your first query is rarely your last. The goal of the initial structured query is to get a baseline set of results. The next step is to refine that set by adding negative constraints. If the initial results are cluttered with cases about employee injuries on commercial property, your follow-up query must explicitly exclude them.
An effective refinement would add a “constraints” object to the query structure: `”exclude_topics”: [“workers compensation”, “employer negligence”]`. This is far more effective than trying to phrase the same idea in natural language, like “but not cases about employees.” The system understands boolean logic better than prose. Each iteration should surgically remove noise from the result set.
Post-Generation Auditing: Trust Nothing
The AI’s output is not the answer. It is a research lead, a draft that must be rigorously audited for accuracy and logical consistency. Accepting the synthesized text without manually verifying every source is professional malpractice. The system is designed to produce convincing text, not correct legal analysis.
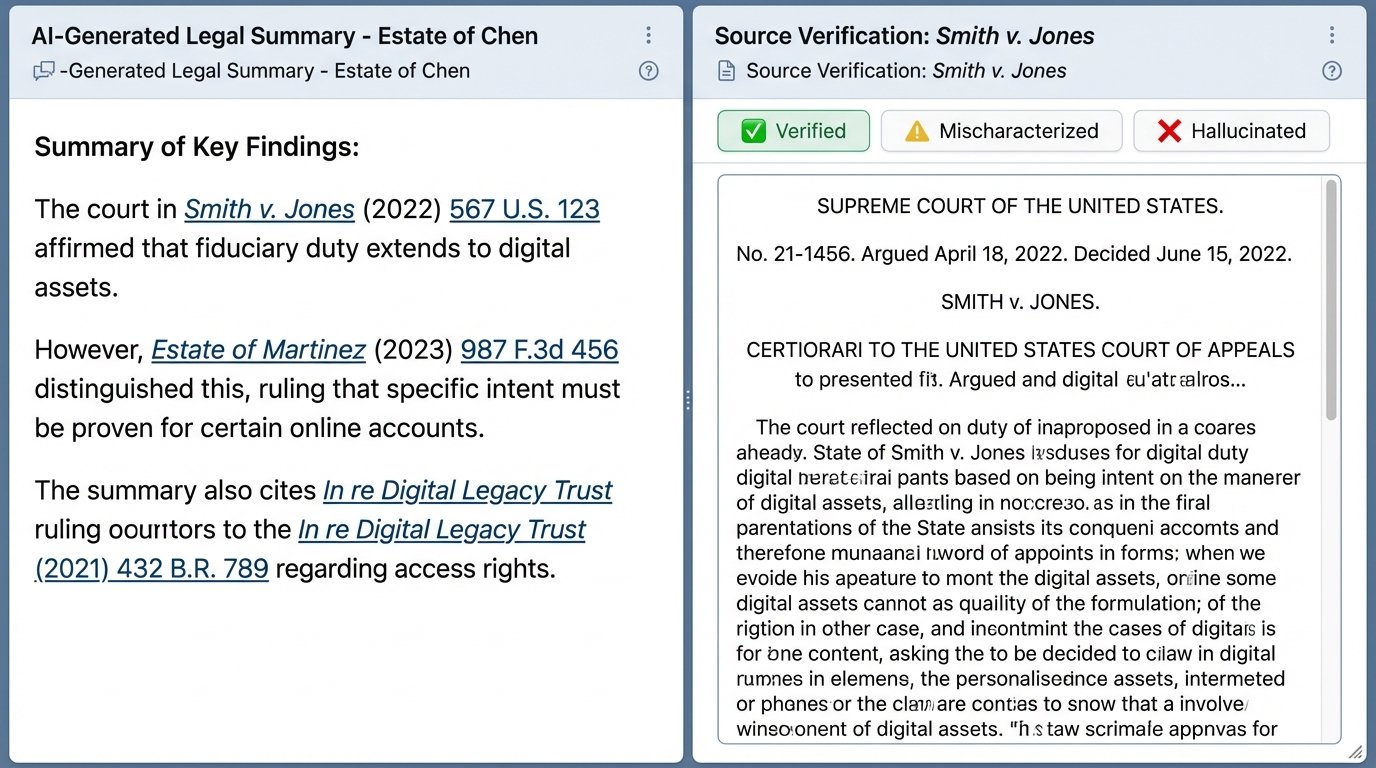
Citation Chasing and Source Verification
The only truly valuable part of an AI’s initial output is the list of citations it used. Your first action is to disregard the summary entirely and pull every single cited case from a trusted, traditional research platform like Westlaw or Lexis. Confirm that the case exists, the citation is correct, and the reporter and page numbers are accurate. Models are known to invent plausible but entirely fictional citations.
Once you confirm a case is real, you must read it. The most common error is not a hallucinated case, but a mischaracterized holding. The AI may cite a case for a proposition that it only mentions in passing dicta, or it may pull a quote from a dissenting opinion and present it as the majority rule. You have to check the source document yourself. There is no shortcut.
Logic-Checking the Synthesis
After verifying that all sources are real and correctly cited, you can return to the AI-generated summary. Now you must logic-check its reasoning. Does the synthesized text accurately reflect the legal principles from the cases it cited? Does it correctly identify the controlling precedent or does it give equal weight to a persuasive but non-binding opinion from another jurisdiction?
LLMs have no concept of the hierarchy of legal authority. They will happily synthesize a rule from a mix of Supreme Court holdings, district court orders, and law review articles, presenting them as a single, coherent doctrine. It is your job to deconstruct the AI’s logic and rebuild it according to the actual weight of each authority. The AI provides the bricks. You have to be the architect.
Workflow Integration without Disrupting Operations
A powerful research tool is useless if it exists on an island, disconnected from the firm’s central nervous system: its case management system. The final stage of implementation is building a bridge between the AI platform and existing workflows, ensuring data flows efficiently and a feedback mechanism exists to capture human corrections.
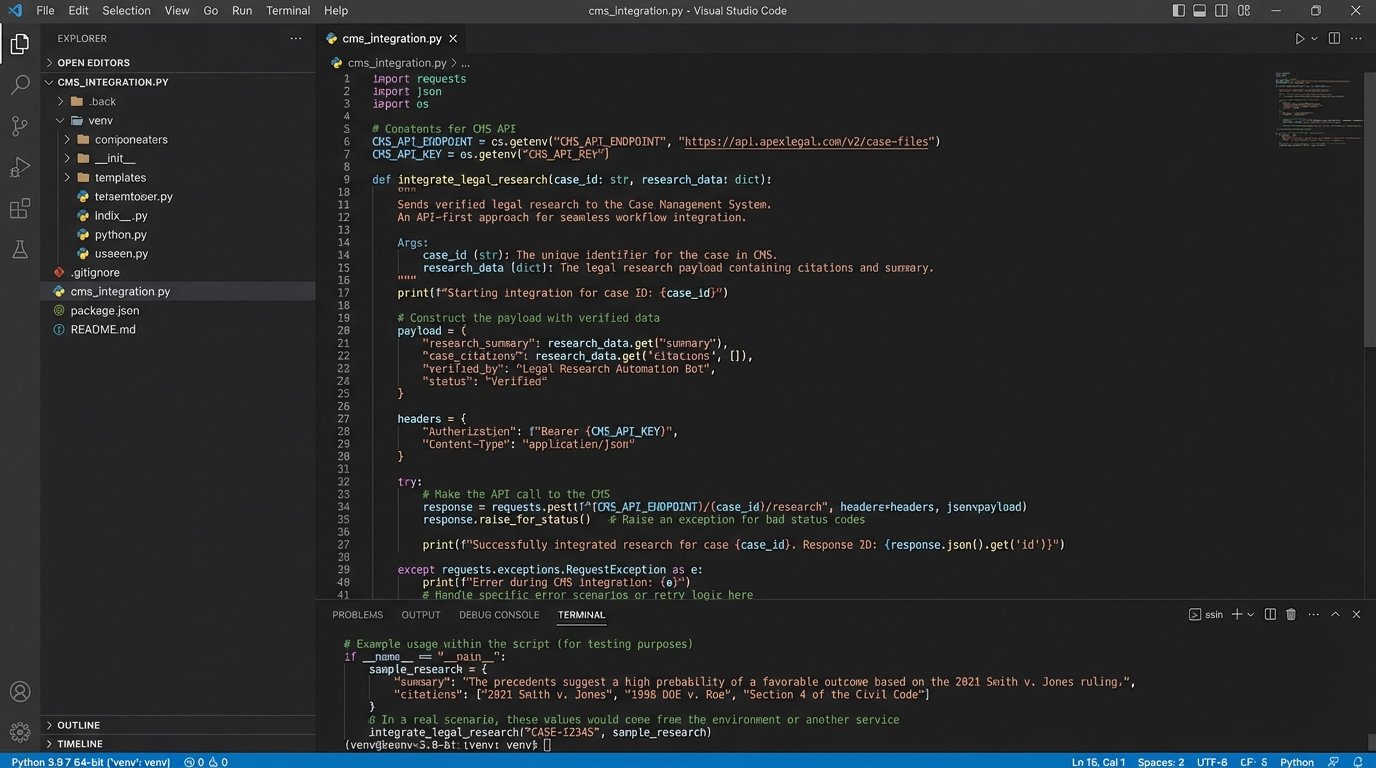
API-First Approach for Case Management Systems
The goal is to eliminate manual data entry. An associate should be able to run a query, validate the results, and, with a single click, push the verified research memo and associated cases into the correct matter file in the CMS. This requires an API-first integration strategy. You must treat the AI tool as just another data source to be called by your own internal systems.
Be prepared for a battle. Most legal tech vendors have poorly documented, sluggish, or non-existent APIs. The integration process often involves more reverse-engineering and support tickets than clean coding. Your selection of an AI tool should be weighted heavily by the quality of its API and its willingness to support deep integration projects.
Building a Feedback Loop
Integration is not a one-way street. You need to capture the corrections and validations made by your legal professionals and feed that data back into the system. When an attorney flags a hallucinated citation or a mischaracterized holding, that event needs to be logged in a structured way. This data is invaluable.
This feedback loop serves two purposes. In the short term, it can be used to build a repository of validated research snippets, saving other attorneys from repeating the same work. In the long term, this structured feedback data becomes a proprietary dataset you can use to fine-tune a future version of the model, training it specifically on your firm’s corrective patterns and analytical standards.
These tools are not autonomous legal minds. They are probabilistic text generators that can be forced into a logical framework. The value is not in the model’s intelligence, but in the rigid, human-driven validation process you build around it. Without that structure, you are not automating legal research. You are just generating plausible noise.