
The marketing around AI in case law research is a masterclass in repackaging old problems. We are told that large language models can “read” and “understand” jurisprudence, delivering perfect precedents on demand. This narrative conveniently ignores the garbage-in, garbage-out principle that governs all data systems. The core challenge is not slapping a GPT-4 API endpoint onto a Westlaw subscription. The real engineering work is in building a data pipeline that can sanitize, structure, and vectorize decades of horribly formatted legal documents before a language model ever sees them.
Most off-the-shelf AI research tools are black boxes. They sell a slick user interface but obscure their data sources, their text-chunking strategy, and their embedding models. This creates an unacceptable level of operational risk. When a junior associate relies on a summary from one of these tools, they are implicitly trusting a proprietary, un-auditable process. That trust is misplaced.
The Brittle Nature of Keyword-Based Systems
For years, legal research has been dominated by Boolean logic and keyword matching. This approach requires the lawyer to predict the exact terminology a judge might have used. A search for “vehicular liability” might miss a key ruling that uses the term “automobile responsibility.” The system is rigid, literal, and completely ignorant of conceptual context. It functions more like a `grep` command than an intelligent retrieval mechanism.
The promise of AI-driven research is to fix this with semantic search. Instead of matching keywords, the system matches the meaning behind the query. This is accomplished by converting both the query and the source documents into numerical representations, or vectors, in a high-dimensional space. The system then finds the documents whose vectors are closest to the query vector. This is powerful, but it’s only as good as the data you feed it.
Legal documents are a data quality nightmare. Case law scraped from court websites is riddled with OCR errors from scanned PDFs, inconsistent citation formats, and useless header and footer text. Trying to force this unstructured, dirty text through a fixed-size chunker is like shoving a firehose of documents through a series of identical, pinhole-sized needles. You shred the context and create a vector representation of noise.
Step One: The Ingestion and Sanitation Gauntlet
Building a reliable system starts with an aggressive pre-processing and data sanitation pipeline. This is the unglamorous, 90% of the work that vendors never talk about. The goal is to take a raw document, typically a PDF or DOCX file, and strip it down to clean, analyzable text. This involves multiple stages, from basic text extraction to more complex structural analysis.
A typical pipeline might look like this:
- Text Extraction: Using a library like `PyMuPDF` to pull raw text and metadata from PDF files. This initial pass is often messy, mixing body content with page numbers, headers, and footnotes.
- Junk Removal: Applying a series of regular expressions to remove common artifacts like “Page X of Y,” court watermarks, and other boilerplate text that adds no legal value.
- Structural Parsing: Identifying the core components of the document, such as the caption, headnotes, opinion, and dissent. This is not a trivial task and often requires custom logic for each court or jurisdiction, as there is no universal standard.
- Citation Normalization: Finding all legal citations and converting them into a consistent format. This is critical for building a knowledge graph or allowing for citation-based queries later.
Failure at this stage guarantees failure downstream. A vector database filled with poorly processed text will return irrelevant results, and the LLM will generate incoherent summaries based on fragmented inputs.
Deconstructing the AI Research Architecture
Once you have a process for generating clean text, you can begin architecting the core AI system. It consists of three primary components: the embedding model, the vector database, and the language model that sits on top for synthesis. Each component presents its own set of choices and potential failure points.
Embedding Models and The Vectorization Process
An embedding model is a neural network that has been trained to convert a string of text into a dense vector of floating-point numbers. This vector captures the semantic essence of the text. For example, the phrases “the company fired the employee” and “the worker was terminated” would have very similar vectors, even though they share few keywords.
Choosing an embedding model is a critical decision. You can use a commercial, closed-source model like OpenAI’s `text-embedding-3-large` or an open-source alternative like those found on Hugging Face. Commercial models are often more powerful and require less setup, but they create a dependency and can become expensive at scale. Open-source models provide more control but require the infrastructure to host and manage them.
The process, often executed in a serverless function, is straightforward: take a clean chunk of text, send it to the embedding model’s API, and receive a vector in return. This vector, along with the original text and its metadata (case name, date, jurisdiction), is then stored in a vector database.
Here is a basic Python function demonstrating the concept of cleaning and preparing text before it would be sent to an embedding model. This is a highly simplified example.
import re
def clean_legal_text(raw_text: str) -> str:
# Remove common PDF headers/footers with page numbers
text = re.sub(r'Page\s+\d+\s+of\s+\d+', '', raw_text, flags=re.IGNORECASE)
# Normalize line breaks and whitespace
text = re.sub(r'\s*\n\s*', ' ', text) # Replace newlines with spaces
text = re.sub(r'\s{2,}', ' ', text).strip() # Collapse multiple spaces
# A simple example of removing a hypothetical court watermark
text = text.replace('--- OFFICIAL COURT DOCUMENT ---', '')
return text
# Example Usage:
document_page_content = """
Page 1 of 25
--- OFFICIAL COURT DOCUMENT ---
IN THE SUPREME COURT OF THE STATE OF FICTION
Case No. 12345
The primary issue is one of vehicular liability.
"""
clean_content = clean_legal_text(document_page_content)
# clean_content would now be:
# "IN THE SUPREME COURT OF THE STATE OF FICTION Case No. 12345 The primary issue is one of vehicular liability."
This code block only scratches the surface. A production-grade system would have far more sophisticated rules for handling different document layouts and formats.
Vector Databases: The New Index
A vector database is a specialized database designed for one purpose: finding the nearest neighbors to a given query vector at high speed. When a user enters a natural language query, that query is first converted into a vector using the same embedding model. The vector database then uses an algorithm like HNSW (Hierarchical Navigable Small World) to efficiently search through millions or even billions of stored document vectors to find the most similar ones.
Popular options include managed services like Pinecone or open-source solutions like Weaviate, Milvus, or Chroma that you can self-host. The choice depends on budget, scalability needs, and the team’s DevOps capabilities. A managed service is faster to set up but is a wallet-drainer over time. Self-hosting provides ultimate control but demands significant engineering overhead for maintenance, scaling, and backups.
The Fallacy of Pure Vector Search
Relying solely on vector similarity is a rookie mistake. While it excels at finding conceptually related documents, it is blind to critical metadata. A query about contract law in California might surface a perfectly relevant case from New York because the factual patterns are semantically similar. For a lawyer, this result is not just irrelevant; it’s dangerously misleading.
The only robust solution is a hybrid search architecture. This approach combines the semantic matching of vector search with the precise filtering of traditional metadata search. The user’s query is executed in two stages. First, a filter is applied to the database to narrow the search space to documents that match the required metadata, such as jurisdiction, date range, or presiding judge. Second, the vector search is performed only within that pre-filtered set of documents.
This gives the user the best of both worlds: the conceptual power of semantic search and the logical control of metadata filtering. It prevents jurisdictional bleed and allows for highly specific, targeted research questions that pure vector search cannot handle. Implementing this requires a vector database that supports rich metadata filtering alongside its vector index.
A query to such a system might look like this in pseudo-code:
results = vector_db.search(
query_vector=embedded_query,
top_k=10,
filter={
"jurisdiction": "Ninth Circuit",
"year": { "$gte": 2020 }
}
)
This query instructs the database to first find all documents from the Ninth Circuit from 2020 or later, and only then perform the semantic search for the top 10 most relevant results within that subset.
The Final Layer: LLMs for Synthesis, Not Search
The large language model should be the final piece of the puzzle, not the first. Its job is not to find information but to synthesize the information that the hybrid search system has already retrieved. Once the system has identified the top 5 or 10 most relevant case documents, their clean text chunks are fed into an LLM like GPT-4 or Claude with a carefully constructed prompt.
This prompt instructs the model to perform a specific task, such as:
- “Summarize the key holding from the following court opinion.”
- “Identify the primary legal test articulated in these excerpts.”
- “Based on the provided cases, extract all arguments related to breach of fiduciary duty.”
This is called Retrieval-Augmented Generation, or RAG. It dramatically reduces the risk of the LLM “hallucinating” or making up facts because it is forced to base its answer only on the source material provided in the prompt. The LLM is not searching the internet; it is working within a closed, curated, and highly relevant context that we have engineered.
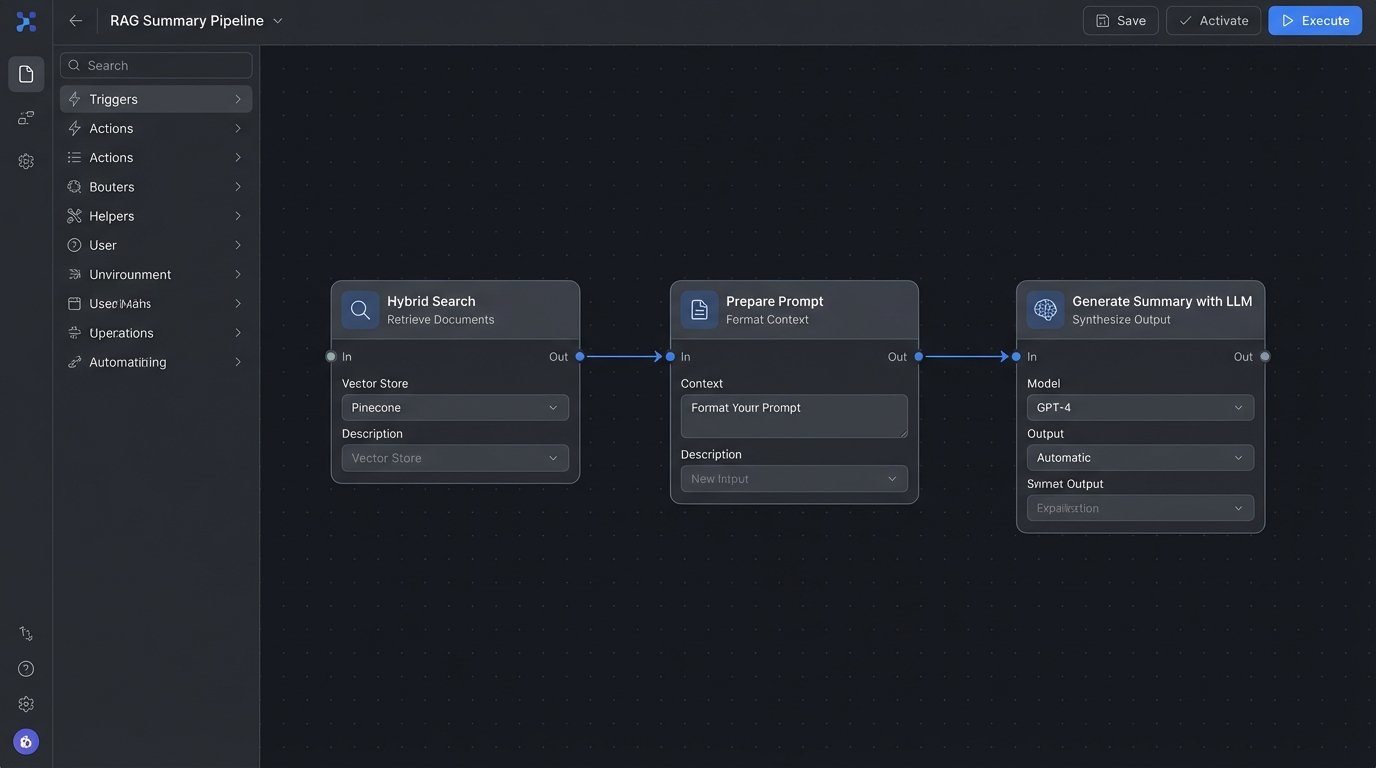
The output is not a definitive legal opinion but a highly advanced starting point. It’s a first draft of a case summary or a list of potential arguments that an associate can then verify and refine. The value is not in replacing the lawyer, but in collapsing the time it takes to go from a research question to a well-supported initial analysis.
The off-the-shelf AI tools sell a simple dream, but legal reality is complex. Building a durable, reliable, and defensible AI research system requires owning the entire data pipeline. It requires a deep investment in data cleaning, a thoughtful hybrid search architecture, and a disciplined use of LLMs for synthesis, not open-ended search. Anything less is just a tech demo, not a professional tool.