
The marketing narrative around AI in case law research is a masterclass in oversimplification. It sells a magic box that digests a query and spits out the perfect precedent. The reality is a brute-force statistical operation running on vectorized text, an approach with predictable failure points that vendors conveniently omit from their demos. For any technical professional tasked with implementing these systems, the first job is to separate the mathematical reality from the sales pitch.
This is not artificial intelligence in the sense of cognition. It is high-speed pattern matching. The core technology is almost always semantic search, which hinges on converting text into numerical representations called embeddings. Every document, every paragraph, every sentence is forced through a model and becomes a vector in a high-dimensional space. A user’s query undergoes the same process. The system then calculates the mathematical distance between the query vector and the document vectors, returning the closest neighbors. The ‘relevance’ is just proximity in a statistical model.
It’s faster than keyword searching. No one disputes that. But it introduces an entire new class of errors rooted in the abstraction process itself.
Deconstructing the Vectorization Pipeline
The entire system’s integrity rests on the quality of the vectorization pipeline. This pipeline has two critical components: the chunking strategy and the embedding model. A failure in either one poisons the entire dataset, often in ways that are not immediately obvious. The result is a system that feels powerful but returns subtly wrong or incomplete results that can misdirect an entire legal strategy.
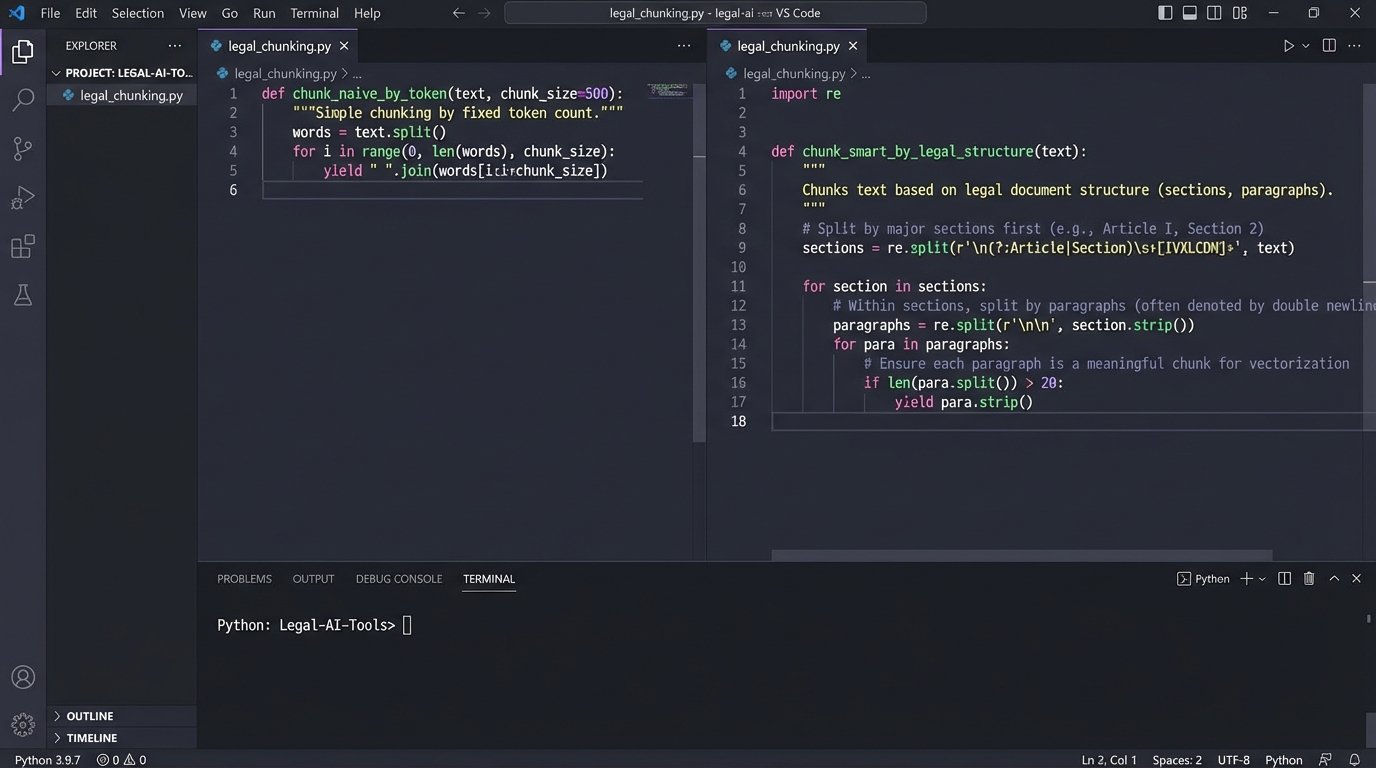
Chunking is the first point of failure. Before a document can be vectorized, it must be broken into smaller pieces. A naive approach just splits the text every 500 tokens. This is cheap, fast, and completely wrong for legal text. A key premise of a judge’s argument might be split across two chunks, severing the logical connection. The resulting vectors will represent fragments of a thought, not the complete thought itself. This makes finding the complete argument through a search query a matter of luck.
A more defensible strategy requires legally-aware chunking. This means parsing the document structure to identify logical boundaries: paragraphs, numbered lists, sections, or even specific legal constructs like a multi-part test. It’s about preserving the semantic integrity of the source material before it ever touches a machine learning model. Building this logic is not a standard feature in most off-the-shelf vectorization libraries. It requires custom engineering.
The Problem with Opaque Embedding Models
The embedding model is the engine that converts text chunks into vectors. Most commercial platforms use their own proprietary models, which presents an immediate data governance problem. These models are black boxes. We cannot inspect their training data, which likely includes a massive, unfiltered scrape of the public internet alongside their private legal datasets. This introduces a risk of the model inheriting biases or “knowledge” from non-legal sources that can skew vector representations in unpredictable ways.
For example, a model trained heavily on news articles might associate a term like “conspiracy” with different semantic neighbors than a model trained purely on judicial opinions. When you search for precedents related to conspiracy, the general-purpose model might surface irrelevant cases because its understanding of the term is polluted by non-legal contexts. Without control over the model or at least transparency into its training data, you are trusting the vendor’s data hygiene completely.
This is where the idea of using open-source, domain-specific models becomes attractive. Models fine-tuned on legal corpora (like Legal-BERT) often produce more accurate vector representations for case law because their “worldview” is restricted to the language of the law. The cost is the internal engineering resources needed to deploy and manage these models. It’s a direct choice between vendor dependency and infrastructure overhead.
Retrieval-Augmented Generation: A Footgun Pointed at Your Firm
The next layer of technology bolted onto semantic search is Retrieval-Augmented Generation, or RAG. The system first retrieves a set of relevant text chunks using vector search. Then, it feeds those chunks into a Large Language Model (LLM) with a prompt like, “Summarize the following text to answer the user’s question.” This produces the clean, conversational answer that looks so impressive in demos.
This process is also a massive source of error. The LLM has no actual understanding of the law. It is a text-generation engine that assembles a plausible-sounding summary from the fragments it was given. The most dangerous failure mode here is not the widely discussed “hallucination” of fake cases. It’s the silent, subtle misrepresentation of real ones. The model might summarize a dissenting opinion as if it were the holding, or conflate arguments from two separate cases into a single, incorrect summary.
The only mitigation is aggressive data provenance. Every single statement in a generated summary must be directly and unambiguously linked back to the specific chunk of source text it came from. The user interface must make it trivial to click a sentence and see the original passage from the original case. If a tool cannot provide this level of citation transparency, it is an unacceptable malpractice risk. No amount of convenience is worth the danger of filing a brief based on a machine’s confident misreading of the law.
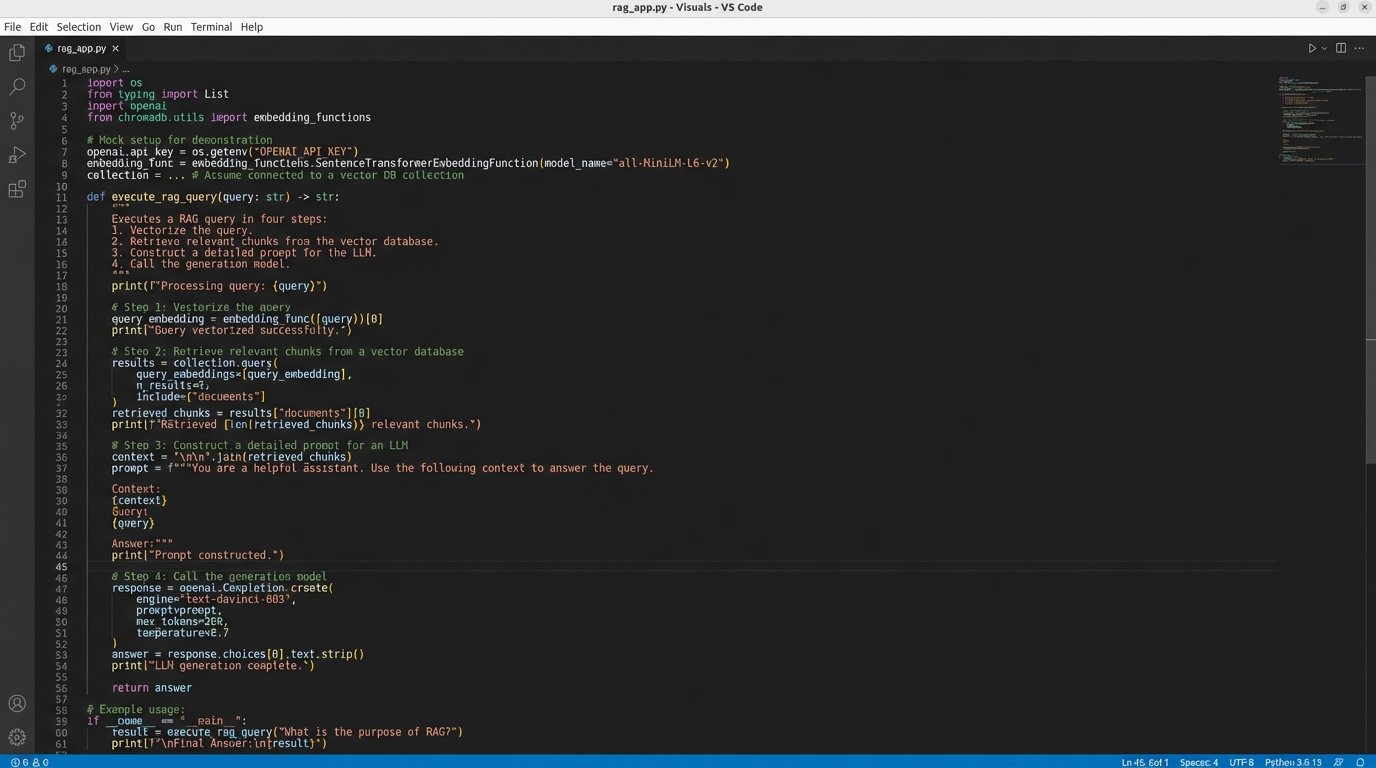
Here is a simplified Python representation of a RAG query flow. Notice how the final output is entirely dependent on the quality of the `retrieved_chunks`. If those chunks are flawed, the LLM will simply generate a coherent-sounding summary of flawed information.
from vector_db_client import VectorDB
from llm_client import LargeLanguageModel
def execute_rag_query(query_text: str):
# Step 1: Vectorize the user's query
query_vector = embed_text(query_text)
# Step 2: Retrieve relevant chunks from the vector database
# This is the most critical failure point.
retrieved_chunks = VectorDB.search(vector=query_vector, top_k=5)
# Step 3: Construct a prompt for the LLM
prompt = f"""
Context from case law:
---
{"\n---\n".join(chunk.text for chunk in retrieved_chunks)}
---
User's question: {query_text}
Based only on the provided context, answer the user's question.
Cite the source for each point.
"""
# Step 4: Generate the answer
# The LLM's output quality is capped by the retrieved context.
response = LargeLanguageModel.generate(prompt)
# The final step (not shown) must be to parse this response
# and link it back to the source documents for verification.
return response
The code is simple. The underlying process is fragile.
Argument Mining: The Actual Next Step
The current generation of AI tools is stuck on document retrieval. The true objective for a lawyer is not finding a document, but finding an argument. This is where the field of argument mining comes in. Instead of treating a judicial opinion as a simple bag of words or vectors, argument mining uses more sophisticated NLP models to parse the logical structure of the text itself.
These models can be trained to identify and classify components of an argument: the central claim, the premises supporting it, the evidence cited, and the type of reasoning used. This allows for a far more powerful type of querying. Instead of searching for cases that mention “breach of fiduciary duty,” you could search for “cases where the court rejected a ‘business judgment rule’ defense in a breach of fiduciary duty claim.”
This shifts the search from topics to tactics. It helps an attorney understand *how* arguments were successfully constructed or defeated in the past. This is a level of analysis that gets much closer to the actual cognitive work of a lawyer. The challenge is that argument mining is computationally expensive and requires highly specialized models. It is not something you can just switch on in a generic vector database. It requires a dedicated processing pipeline to parse and tag the documents before they are even indexed.
This is where in-house legal engineering teams can create a real advantage. By building a custom pipeline that first uses argument mining to tag case law and then indexes those tagged components, they can build a search system that answers questions about legal strategy, not just legal topics. This is the difference between a library and a strategic advisor.
The Messy Reality of Integration
None of these systems exist in a vacuum. They must be integrated into the firm’s existing technology stack, which usually means bridging them with a legacy Case Management System. The APIs for these systems are often an afterthought, built years ago with no concept of modern data pipelines. Trying to extract the thousands of documents needed to populate a vector database can feel like shoving a firehose through a needle. You will contend with strict rate limits, inconsistent data formats, and cryptic error messages.
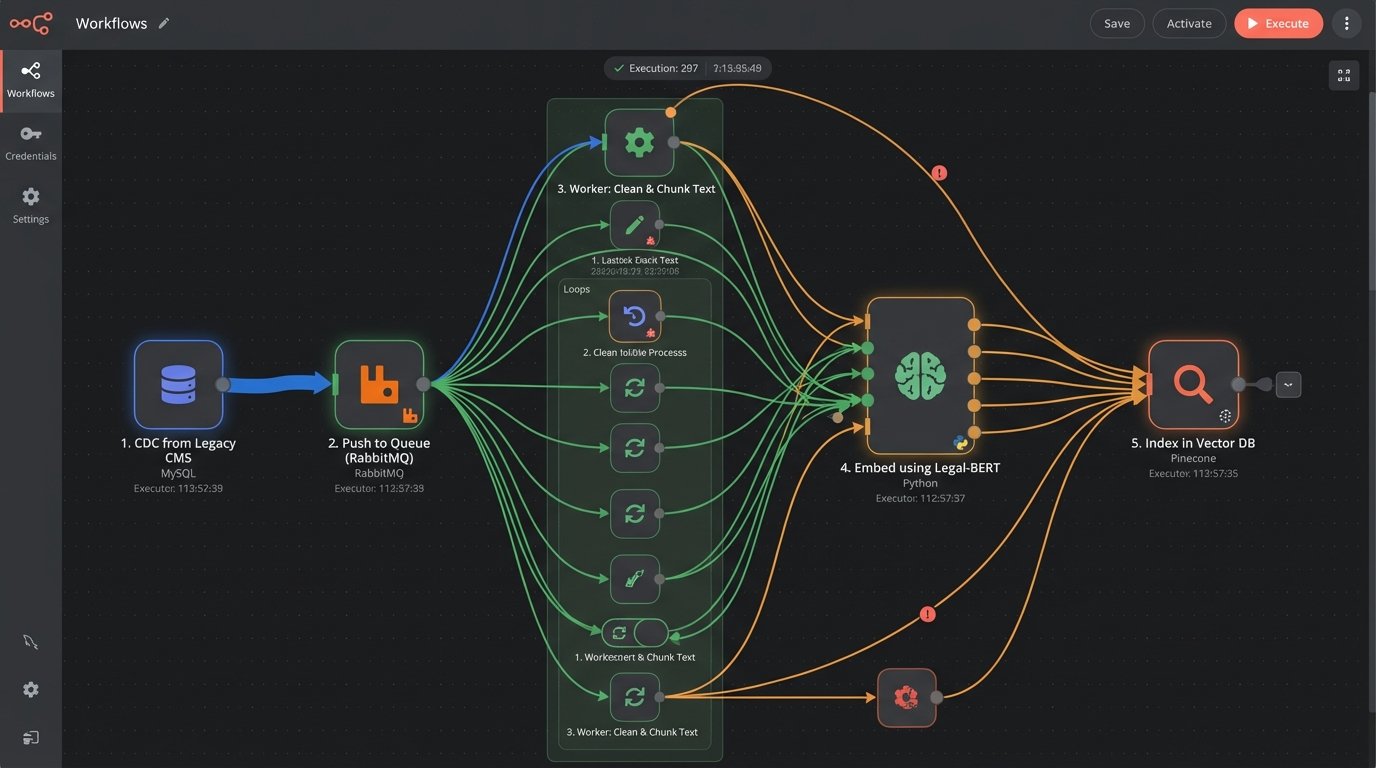
The data flow is a significant engineering challenge. A typical workflow involves setting up a change data capture (CDC) process to monitor the CMS for new documents. These documents are then pushed into a queue, picked up by a worker process for cleaning and chunking, passed to an embedding model, and finally written to the vector database. The search interface then needs to be embedded back into the CMS, often via an iFrame, so that lawyers can access it without disrupting their workflow.
This is a project that requires skills in data engineering, cloud infrastructure, and API integration. It’s a far cry from the “plug-and-play” solution often advertised. Any firm looking to get serious about this technology needs to plan for the cost and complexity of the integration work, not just the license fee for the shiny new AI tool.
The future of legal research is not a chatbot that does the work for you. It is a set of powerful but unforgiving tools that amplify the abilities of an expert. These tools require expert operators who understand their limitations. The assumption that you can just buy an AI and fire your associates is naive. The reality is you need to hire engineers to make the AI function without committing malpractice.