
The marketing around automated case law research promises a world where an algorithm surfaces the perfect precedent on demand. This narrative conveniently ignores the brittle infrastructure it is built on. The core problem has never been a lack of search boxes. The actual bottleneck is data latency and the fractured, inconsistent nature of legal data sources. An AI is only as good as the data it ingests, and most legal databases are stale by the time the query is run.
The Architectural Lie of Static Databases
Most commercial legal research platforms operate on a batch-update model. They ingest and index court filings on a periodic schedule, sometimes daily, often weekly. This means the case law you are searching is a snapshot, a photograph of a reality that has already changed. For fast-moving litigation, relying on a database that is 24 hours old is an unacceptable risk. The critical filing from a related case that landed last night is invisible.
This isn’t a failure of search algorithms. It is a fundamental data engineering problem. The solution is not a better natural language processing model. It is a shift from batch processing to a continuous ingestion architecture. This requires building a network of scrapers, API monitors, and event-driven triggers that watch court dockets and other sources in near real-time. When a new document is filed, a process kicks off immediately to parse, index, and make it searchable.
Building this kind of system is a resource drain. It requires constant maintenance to deal with changes in court websites, broken API endpoints, and the sheer volume of unstructured data. Most vendors opt for the cheaper, more stable batch method and hide the latency behind a slick user interface.
From Batch Dumps to Live Streams
A continuous ingestion pipeline treats new case law as an event stream, not a file to be downloaded. Think of it as a firehose of raw data that must be filtered, structured, and routed on the fly. We build listeners that poll PACER, state-level e-filing systems, and even administrative tribunals. When a new entry is detected, an event is published to a message queue like RabbitMQ or Kafka.
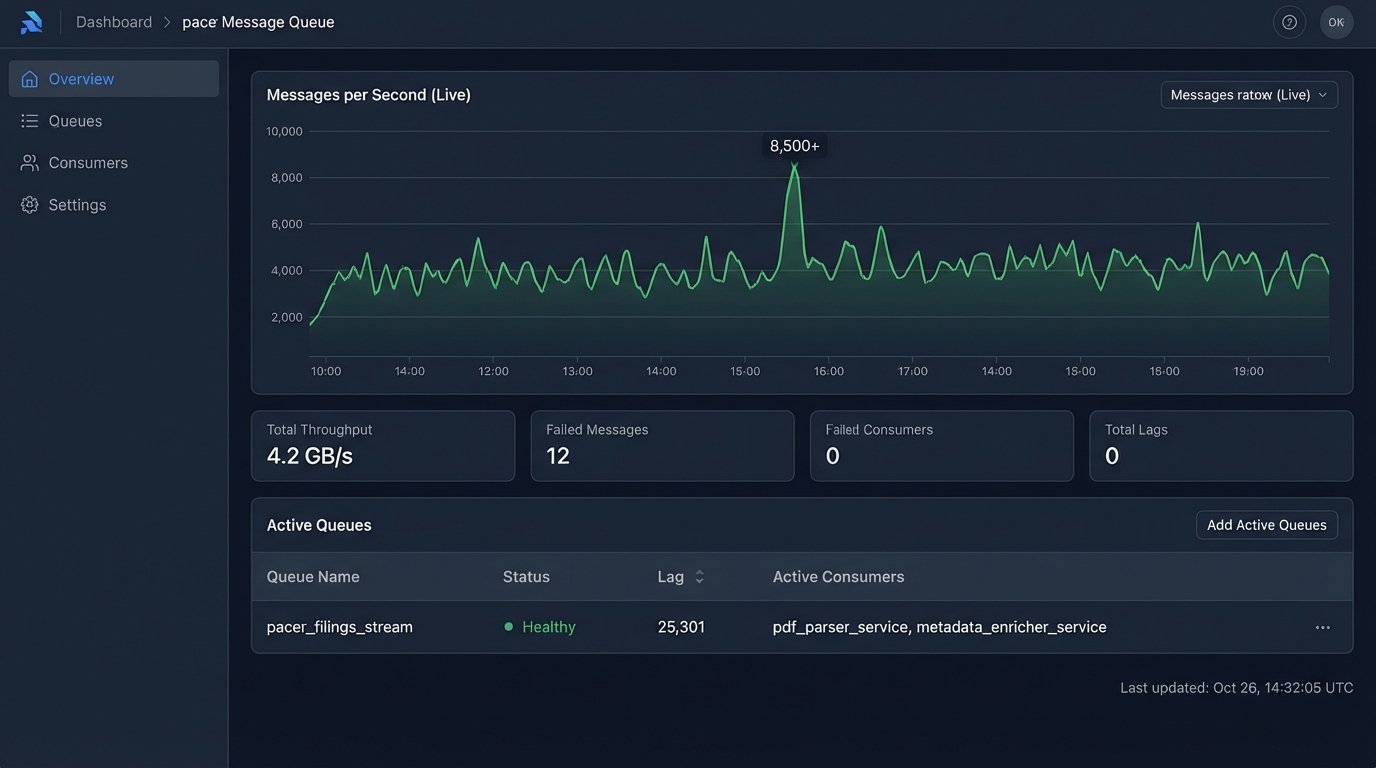
Downstream services then consume these events. One service might strip the text from a PDF, another enriches it with metadata, and a third calculates vector embeddings for semantic search. This distributed architecture is more complex to build but is massively more responsive than a monolithic, batch-oriented system. It changes the research paradigm from querying a historical archive to querying a live reflection of the legal landscape.
The difference is stark. An associate can be alerted to a new, relevant appellate decision minutes after it is published, not hours or days later. This is not about finding obscure case law from 1982 faster. It is about gaining an information advantage in active litigation today.
Deconstructing AI-Powered Relevance
Vendors love to talk about their proprietary “AI relevance engine.” This is usually a marketing wrapper around standard machine learning techniques, most commonly vector search. The process involves converting documents and search queries into numerical representations, called embeddings, in a high-dimensional space. Relevance is then just a mathematical calculation of the distance between the query vector and the document vectors.
There is no magic here. The quality of the results depends entirely on the model used to generate the embeddings and the quality of the text it was trained on. A model trained on a generic corpus of web text will struggle with the specific terminology and structure of legal documents. This is the garbage-in, garbage-out principle in action. A poorly configured vector search can easily surface documents that are semantically adjacent but legally irrelevant, creating more noise for the attorney to sift through.
The Computational Cost of Context
Generating these embeddings and running similarity searches at scale is computationally expensive. It requires significant GPU resources, which translates directly to cost. This is the part of the AI equation that is rarely discussed in sales pitches. The real wallet-drainer isn’t the software license. It is the underlying compute consumption required to keep the index fresh and the queries fast.
Furthermore, these models are probabilistic. They do not “understand” legal concepts. They identify statistical patterns in text. This makes them susceptible to error and hallucination. An AI might rank a dissenting opinion highly because it uses similar language to the controlling precedent, completely missing the legal context. Blindly trusting an AI’s relevance score without a clear method for validation is professional malpractice waiting to happen.
Here is a simplified example of what a query to a vector database API might look like. Notice it is just a data structure. It is a technical tool, not a thinking machine.
{
"query": {
"vector": [0.12, 0.45, -0.23, ..., 0.89],
"top_k": 10,
"filter": {
"jurisdiction": "9th Cir.",
"date_filed": {
"gte": "2023-01-01"
}
}
},
"include_metadata": true
}
This request asks the database to find the 10 closest document vectors to the input query vector, but only within the 9th Circuit and filed after the start of 2023. The real work is in generating that query vector and building a system that can reliably apply those filters.
The API is the Product, Not the Web Portal
The true value of an automated research platform for any serious legal ops team is not its graphical user interface. A web portal is a data silo. It forces attorneys to switch context, leaving their primary work environment, the case management system (CMS) or document management system (DMS), to run a search in a separate browser tab.
The real asset is the Application Programming Interface (API). A well-documented API allows us to bypass the vendor’s interface entirely and inject research intelligence directly into our existing workflows. We can pull data out of the research platform and push it into the systems where our lawyers actually work. Trying to sync these systems without a solid API is like trying to change a tire on a moving car. It is messy and bound to fail.
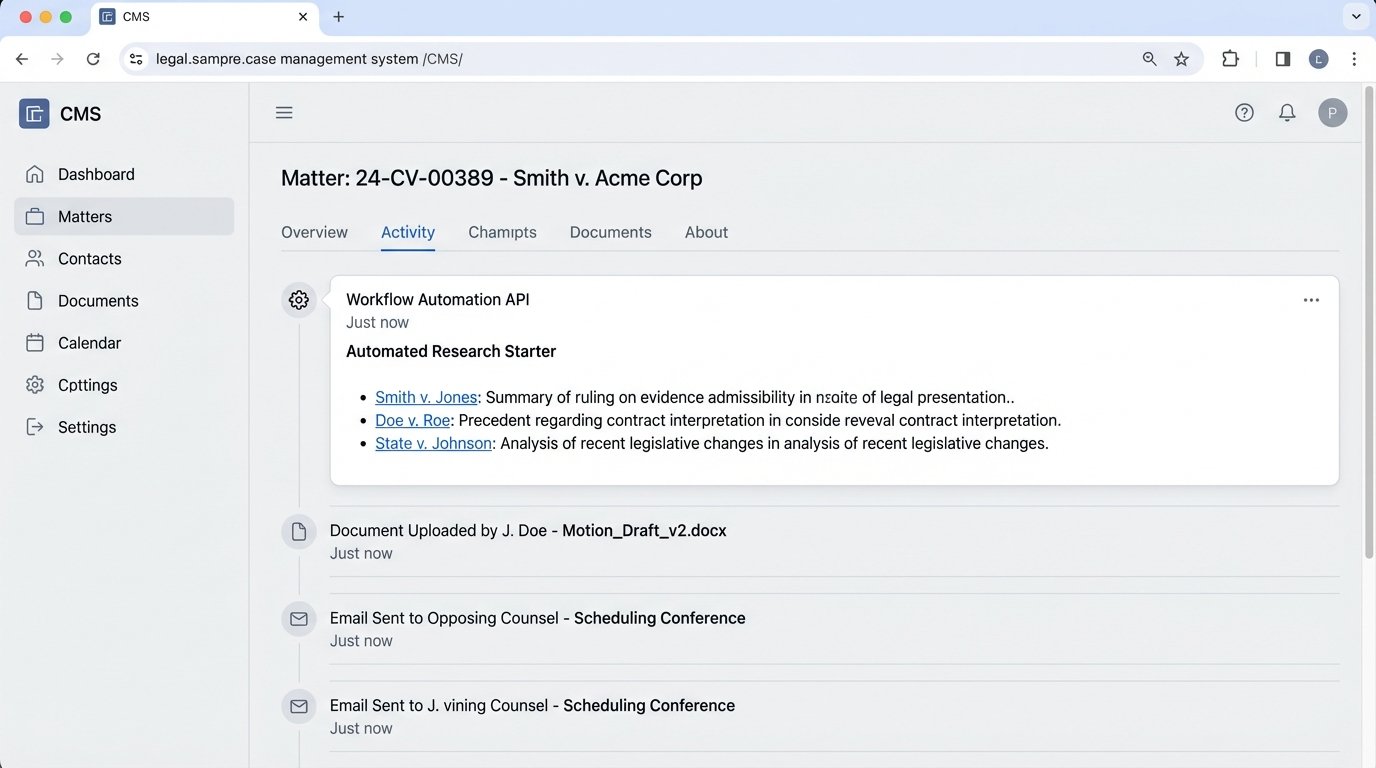
An Integrated Research Workflow
Consider a practical, automated workflow. A new complaint is saved to the firm’s DMS. A file-watcher service detects the new document and triggers a cloud function. This function uses optical character recognition (OCR) if needed, then parses the document text, identifying key legal claims, cited statutes, and named parties.
The script then constructs a series of queries to the research platform’s API based on this extracted information. It searches for recent opinions related to the specific causes of action in that jurisdiction. The results, including case summaries and links to the full text, are packaged into a JSON object. Finally, another API call pushes this JSON object as a “Research Starter” note directly into the matter file within the firm’s CMS.
The attorney working on the case does not need to log into a separate research tool. The initial, relevant case law appears in their workspace automatically, minutes after the complaint is filed. This is not about replacing the lawyer. It is about front-loading the research process and eliminating the manual drudgery of initial queries.
Building Guardrails for Automated Systems
An automated system that cannot be audited is a liability. Relying on a black-box AI to rank legal precedent is an abdication of professional responsibility. Every automated workflow must have built-in checkpoints for human review and validation. We do not trust, we verify.
The output from these systems should include confidence scores and explainability data. Why did the model rank this case as 95% relevant? Which passages in the text most heavily influenced that score? This data allows a human reviewer to quickly assess the quality of the AI’s output. A result with a low confidence score or questionable justification should be flagged for manual inspection.
The Human-in-the-Loop Queue
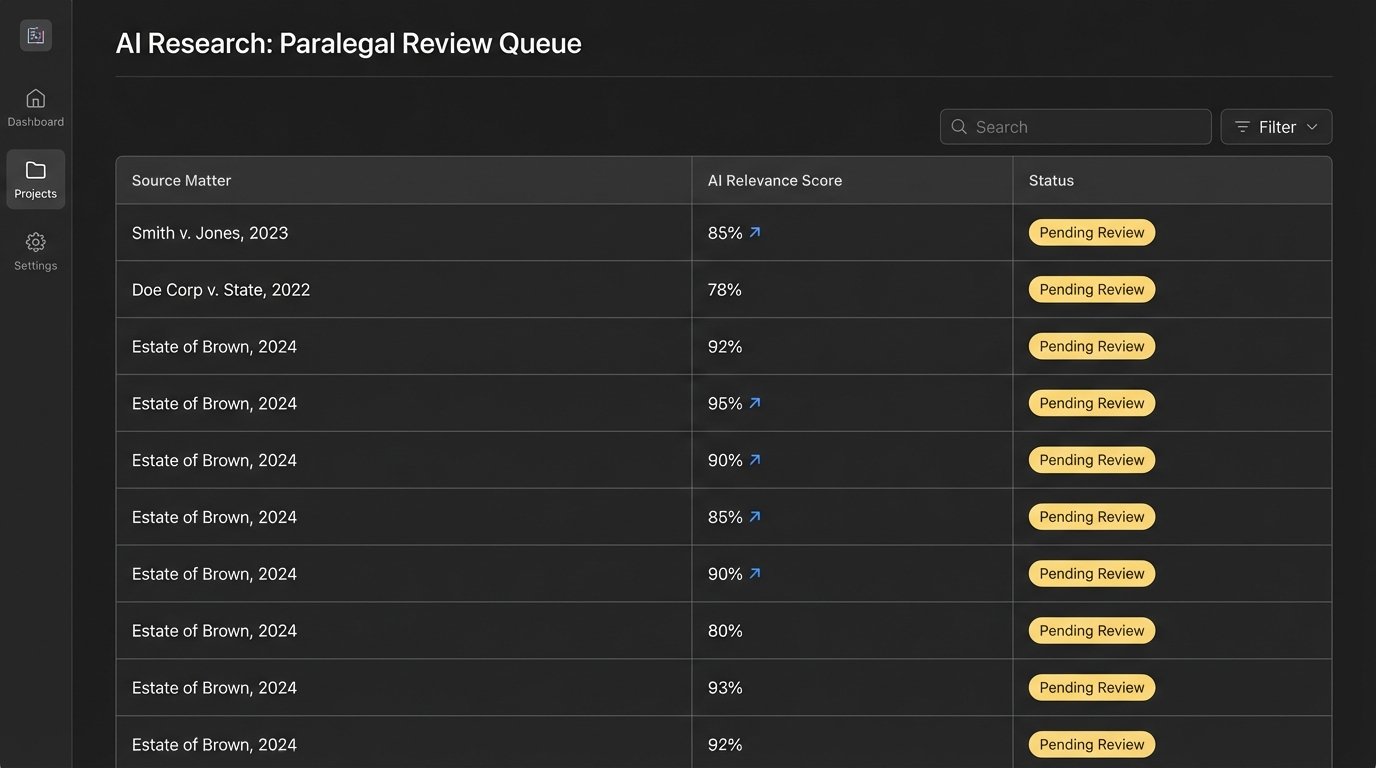
A robust implementation involves creating a human-in-the-loop validation queue. Instead of pushing all API results directly to the CMS, the system applies a confidence threshold. For example, a Python script could logic-check the result before routing it.
def route_research_result(result):
confidence_score = result.get("relevance_score")
cms_api_client = CmsApiClient()
if confidence_score > 0.90:
# High confidence, push directly to the matter file
cms_api_client.post_note_to_matter(result)
elif 0.70 <= confidence_score <= 0.90:
# Medium confidence, push to a paralegal review queue
cms_api_client.post_to_review_queue(result, "paralegal_team")
else:
# Low confidence, log and discard
log_low_confidence_result(result)
This approach creates a tiered system. High-confidence results provide immediate value with low risk. Medium-confidence results are routed to a junior associate or a paralegal team for a quick check. This ensures that a human eye reviews ambiguous results before they reach the senior attorney, preventing noise and catching potential errors. This is not a failure of automation. It is a sign of a mature, production-ready system that acknowledges the technology’s limits.
The ultimate goal is not a fully autonomous legal robot. It is a hybrid system where machines handle the high-volume, repetitive tasks of data collection and initial filtering, freeing up legal professionals to focus on strategy, analysis, and argumentation. The power is not in the algorithm itself, but in the thoughtful construction of the pipelines that feed it and the workflows that consume its output.