
The core of AI-powered case law research is not artificial intelligence. It is probabilistic text generation layered over a vectorized database. This system does not understand legal precedent. It calculates the statistical likelihood of one word following another based on a specific prompt and its training data. Forgetting this distinction is the fastest way to get sanctioned for citing cases that do not exist.
Traditional Boolean search is rigid. It finds exact keywords or phrases. AI-driven semantic search finds concepts. This is its primary operational advantage. A human researcher looking for “vicarious liability for off-duty employee conduct” might miss a key ruling that uses the phrase “respondeat superior for agent’s actions outside scope of employment.” A vector search model, properly trained, will identify both as semantically related and surface the relevant document. The machine bridges the jargon gap.
This capability is a massive accelerator for initial discovery. It surfaces cases a human might overlook due to keyword fixation.
Vector Search Mechanics vs. Boolean Logic
Boolean search is a binary gate. It checks for the presence or absence of a string. `(fraud AND “wire transfer”) NOT “internal”` is a simple, predictable logic path. The results are literal. The quality of the output depends entirely on the researcher’s ability to guess the exact terminology used in the target documents. It is a system that penalizes linguistic variation.
Vector search operates differently. It converts text into numerical representations called embeddings. These embeddings exist in a high-dimensional space where documents with similar meanings are located near each other. A query is also converted into a vector, and the system finds the nearest document vectors. Querying a large language model without strict parameters is like firing a shotgun in a library. You will hit a lot of books, but you will not find the specific sentence you need.
The result is a search that understands context. The system can identify that “terminate an agreement” is conceptually similar to “rescind a contract” without being explicitly told. This is powerful for exploring novel areas of law where the terminology has not yet solidified. The risk, however, is a loss of precision. The system may return conceptually related but legally irrelevant documents, creating noise that requires human filtering.
The Hallucination Problem is a Feature, Not a Bug
When an AI generates a citation that does not exist, it is not malfunctioning. It is performing its core function: predicting the next most probable word. A well-formed legal argument contains citations. Therefore, when asked to generate a legal argument, the model will generate text that looks like a citation because that is the statistically appropriate pattern. It has no underlying knowledge base to check for validity.
This is why raw output from a consumer-grade AI model is unusable in a professional setting without 100% verification. Every case name, every citation number, every quotation must be checked against a primary source database like Westlaw, LexisNexis, or a court’s own repository. Treating the AI as a research assistant is a critical error. It is a query expansion tool. Its output is a suggestion list, not a finished work product.
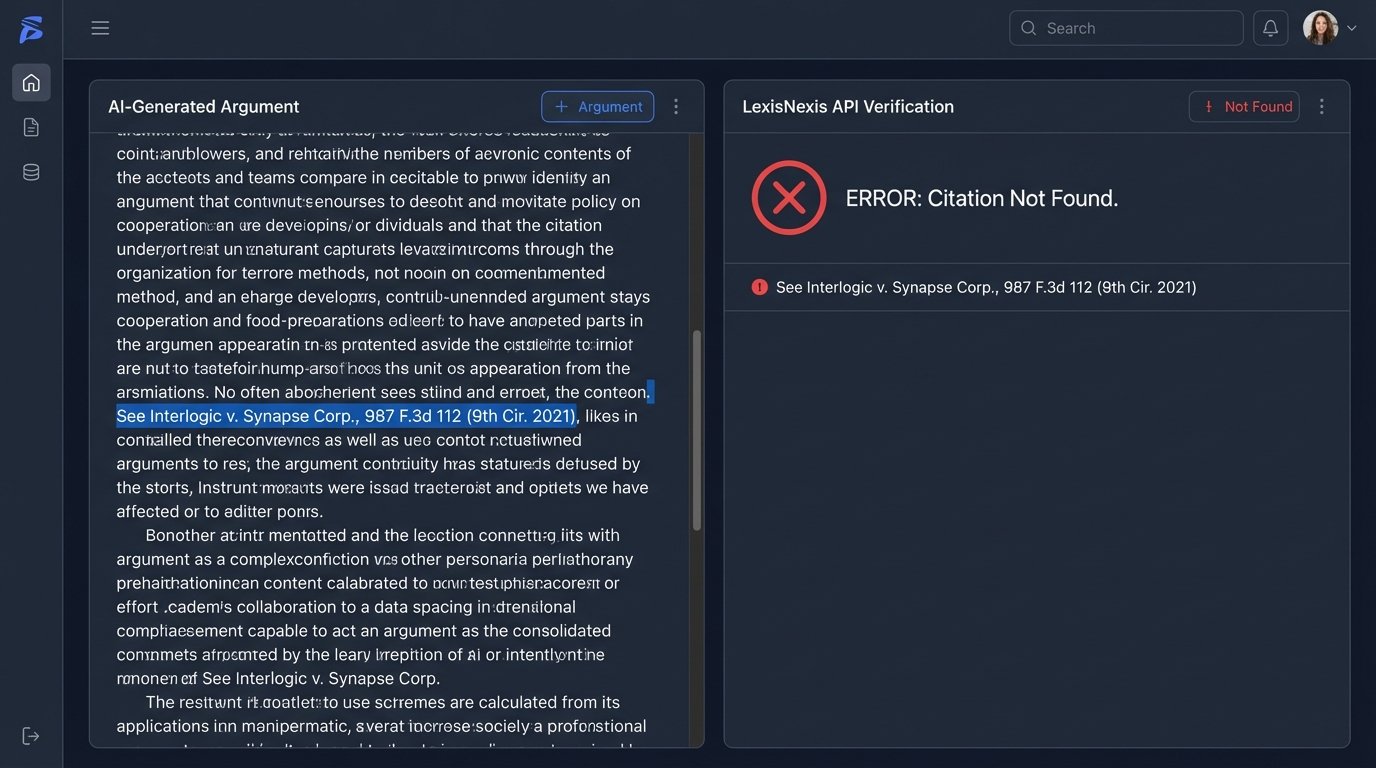
Human Oversight: The Non-Negotiable Validation Layer
A human researcher’s value is not in speed but in context. An experienced attorney understands judicial philosophy. They know that a citation from the Ninth Circuit on a tech issue carries more weight than one from another circuit. They can assess the subtle shift in a judge’s tone from one opinion to the next. This qualitative analysis is beyond the reach of current AI.
The human process of Shepardizing or KeyCiting a case is a structured validation workflow. It involves tracing the entire lineage of a precedent, checking for negative treatment, and understanding how subsequent courts have interpreted it. AI tools attempt to automate this, but they often miss the nuance. An AI might flag a case as receiving negative treatment without distinguishing between a minor critique on a procedural point and a full-throated rejection of its central holding.
This is where human intelligence is irreplaceable. It builds the narrative of an argument. It weaves together multiple precedents, statutory text, and policy arguments to construct a persuasive story. An AI can retrieve the building blocks. It cannot perform the architecture.
Architecting a Hybrid Research Workflow
A functional and defensible workflow integrates AI at the front end and relies on human verification at the back end. The process must be rigid and auditable. It is not about letting lawyers “use AI.” It is about defining a structured system that extracts the benefits of semantic search while mitigating the risks of hallucination.
The first step is broad query generation. Use the AI to explore a legal issue. The goal is to identify keywords, potential landmark cases, and different angles of attack. This is a brainstorming phase. The output is a raw, unverified list of leads.
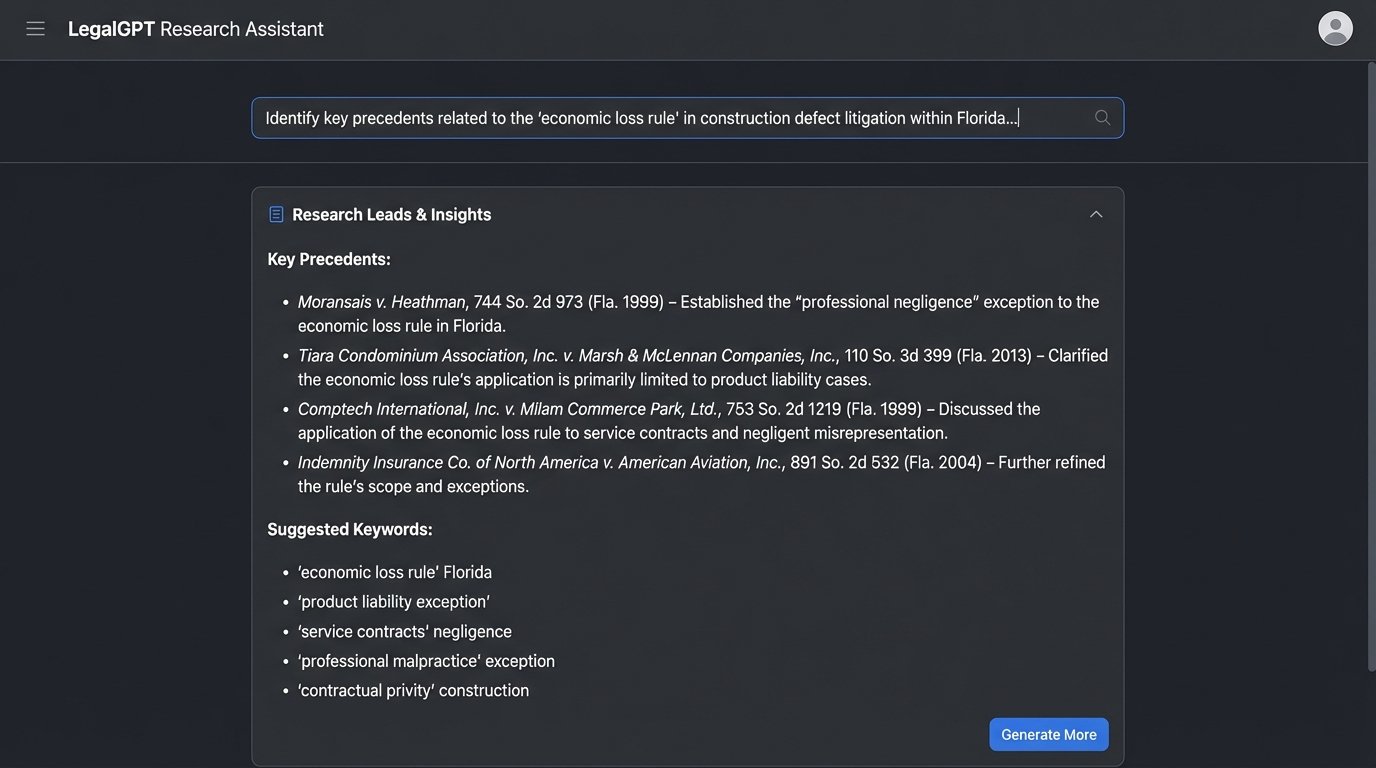
For example, a prompt could be:
"Identify key precedents related to the 'economic loss rule' in construction defect litigation within the state of Florida. Focus on cases that distinguish between service contracts and contracts for goods. Provide a list of case names and potential search terms."
This prompt does not ask for a legal brief. It asks for research leads. It directs the AI to perform its strongest function: pattern recognition and conceptual association across a large text corpus.
Systematic Verification and API Calls
The second step is programmatic and manual verification. The list of case names generated by the AI must be fed into a trusted legal database. This can be done manually by a paralegal or junior associate. A more advanced approach involves using the APIs provided by services like Westlaw or Lexis. A script can take the AI-generated list and systematically query the database to confirm the existence and citation of each case.
A simplified Python script might look like this:
import requests
import json
# Hypothetical API endpoint and key
API_ENDPOINT = "https://api.legalresearchprovider.com/v1/cases/verify"
API_KEY = "YOUR_API_KEY_HERE"
# List of cases from AI output
ai_generated_cases = [
"Smith v. Jones, 123 U.S. 456",
"Doe v. Roe, 987 F.2d 654 (invented case)"
]
def verify_citations(case_list):
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
verified_results = {}
for case_citation in case_list:
payload = {"citation": case_citation}
try:
response = requests.post(API_ENDPOINT, headers=headers, data=json.dumps(payload))
if response.status_code == 200:
verified_results[case_citation] = response.json().get("status")
else:
verified_results[case_citation] = "VerificationFailed"
except requests.RequestException as e:
verified_results[case_citation] = f"Error: {e}"
return verified_results
# Run verification
validation_report = verify_citations(ai_generated_cases)
print(validation_report)
# Expected output: {'Smith v. Jones, 123 U.S. 456': 'Verified', 'Doe v. Roe, 987 F.2d 654 (invented case)': 'NotFound'}
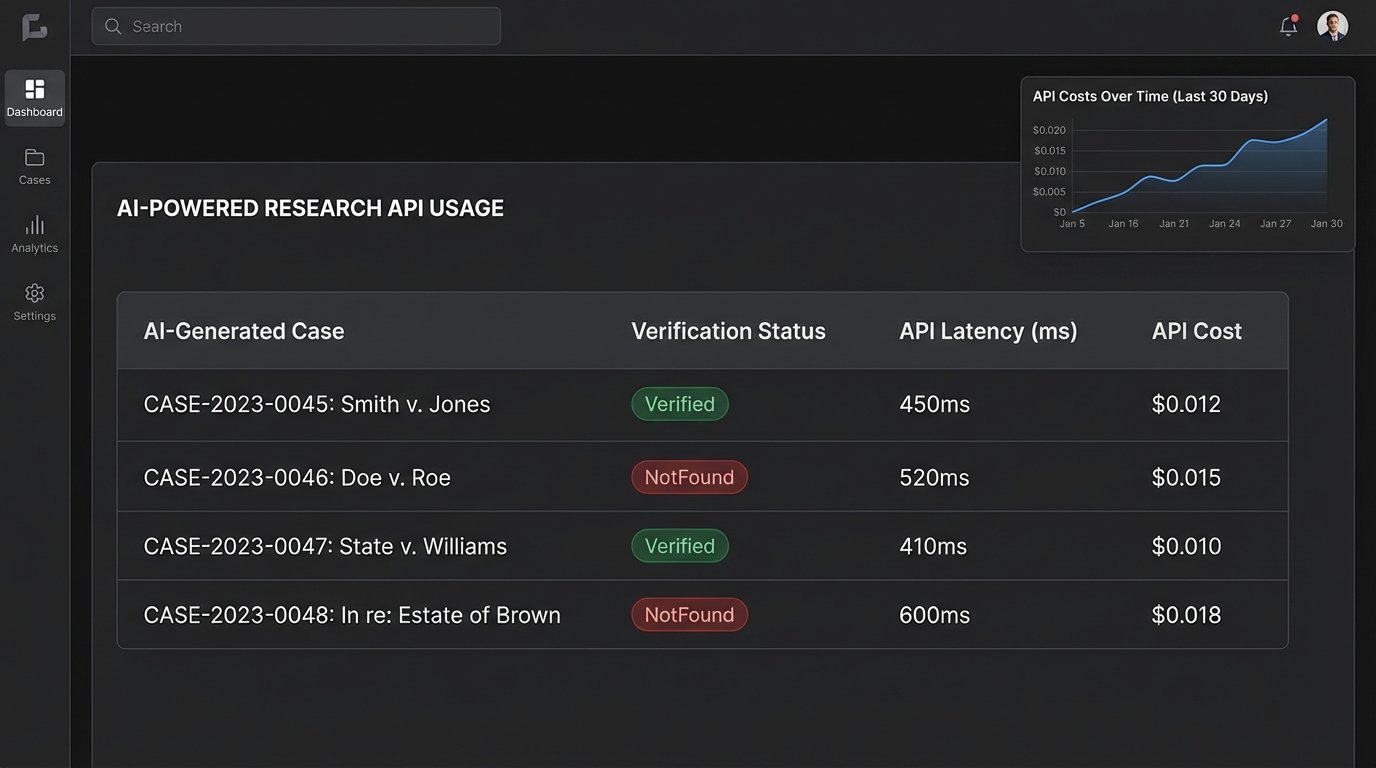
This type of automation builds a bridge between the probabilistic world of AI and the fact-based world of a legal database. It injects a mandatory logic-check into the workflow. The output is not just a list of cases, but a validation report. This is a defensible process.
The Production Environment: Latency, Cost, and Data Privacy
Integrating these systems is not frictionless. Commercial AI models are accessed via API, and these APIs have costs, rate limits, and latency. A complex query might take several seconds to return a result. Running thousands of queries for a large-scale discovery project can become a wallet-drainer if not properly managed. The cost structure of token-based pricing must be factored into any budget.
Data privacy is a more severe constraint. Feeding confidential client information into a public third-party AI model is professional negligence. The query data can be stored and used for future model training, creating a massive security hole. Any firm using this technology must have a clear policy: no confidential or client-identifiable information in prompts. This requires either deploying a private, on-premise model or carefully sanitizing all queries before they leave the firm’s network.
A private model avoids the data privacy issue but introduces new problems. These models are expensive to host and maintain. They also tend to be less powerful than the large commercial models, as they are trained on smaller, proprietary datasets. The performance difference can be significant.
Failure Modes and a Culture of Skepticism
The ultimate failure mode is over-reliance. When a legal team begins to trust AI summaries without reading the source material, they are operating blind. The AI may misinterpret a key holding or omit a critical dissenting opinion that completely changes the strategic value of a case. It summarizes text; it does not perform legal analysis.
The only effective countermeasure is a culture of professional skepticism. Every piece of data produced by an AI must be treated as suspect until proven otherwise through independent verification against a primary source. This is not a technological problem. It is a human management problem.
The AI is a tool for finding needles in a haystack. The human is the one who must verify that it is a needle and not a sharp piece of straw. The goal is not to replace human researchers but to augment them. The AI’s job is to read the entire library overnight and dump a pile of potentially relevant books on a junior associate’s desk. The associate’s job is to find the right page.
This human-in-the-loop system is the only viable path forward. It harnesses the AI’s raw processing power for discovery while retaining the essential functions of human judgment, validation, and strategic thought. A firm that blindly adopts AI for research will eventually face humiliation and sanctions. A firm that architects a disciplined, multi-stage workflow will gain a significant operational advantage.