
Most AI research tools are marketed as magic wands. They are not. They are statistical models trained on a mountain of text, prone to invention and misinterpretation. Using them effectively means treating them less like an oracle and more like a junior associate who is fast, occasionally brilliant, and requires constant, rigorous supervision. The goal is not to replace the researcher but to force-multiply their ability to identify, validate, and apply relevant case law. Anything less is professional malpractice waiting to happen.
The core failure of most AI adoption in legal research is the lack of a defined protocol. Firms throw subscriptions at their teams and expect productivity gains. Instead, they get inconsistent results and junior lawyers citing cases that do not exist. A structured approach is not optional. It is the only way to get reliable output from these systems.
Prerequisites: System and Data Hygiene
Before you write a single query, you must get your house in order. Running sophisticated queries against a chaotic internal data environment is pointless. The primary prerequisite is a clean, indexed internal knowledge management system. If your firm’s historical work product is a mess of poorly named Word documents on a shared drive, the AI has no quality internal data to cross-reference. It will only learn from your disorganization.
A second, non-negotiable step is establishing a clear API strategy. Relying on the vendor’s user interface is a trap. It limits your ability to chain commands, automate validation, or integrate results into other systems like document automation or case management platforms. You need API access, and you need someone on your team who can read the documentation and write basic scripts to pull the data you need, not just the data the UI wants to show you. The native interface is for spot-checking, not for serious workflow.
Defining the Research Objective
An AI is not a mind reader. A vague prompt like “Find cases about breach of contract” will return a firehose of irrelevant information. The objective must be broken down into discrete legal questions. Instead of the broad query, a better approach is to structure a series of specific inquiries:
- What constitutes a material breach for software development contracts in the Ninth Circuit?
- Identify cases where force majeure was successfully invoked due to supply chain disruptions post-2020.
- Find precedents defining “reasonable commercial efforts” in asset purchase agreements.
Each query is a targeted strike. This forces the model to search a narrower vector space and reduces the probability of it inventing irrelevant connections. The work is in defining the questions, not in typing them into a search box. That is the fundamental shift.
Step 1: Engineering the Query
Effective querying is a function of specificity and structure. The most advanced tools now bypass simple keyword matching in favor of semantic search. This means the system attempts to understand the *intent* behind your query, not just the words themselves. It searches for conceptual relationships, which is powerful but also dangerous. The model’s interpretation of your concept might not align with established legal doctrine.
Your first query should be a broad natural language question to establish a baseline. For example: “What is the standard for piercing the corporate veil for a single-member LLC in Texas?” The initial results give you a sense of the model’s core understanding and biases. It will likely return the landmark cases and a few tangential ones. This is your starting point, not your answer.
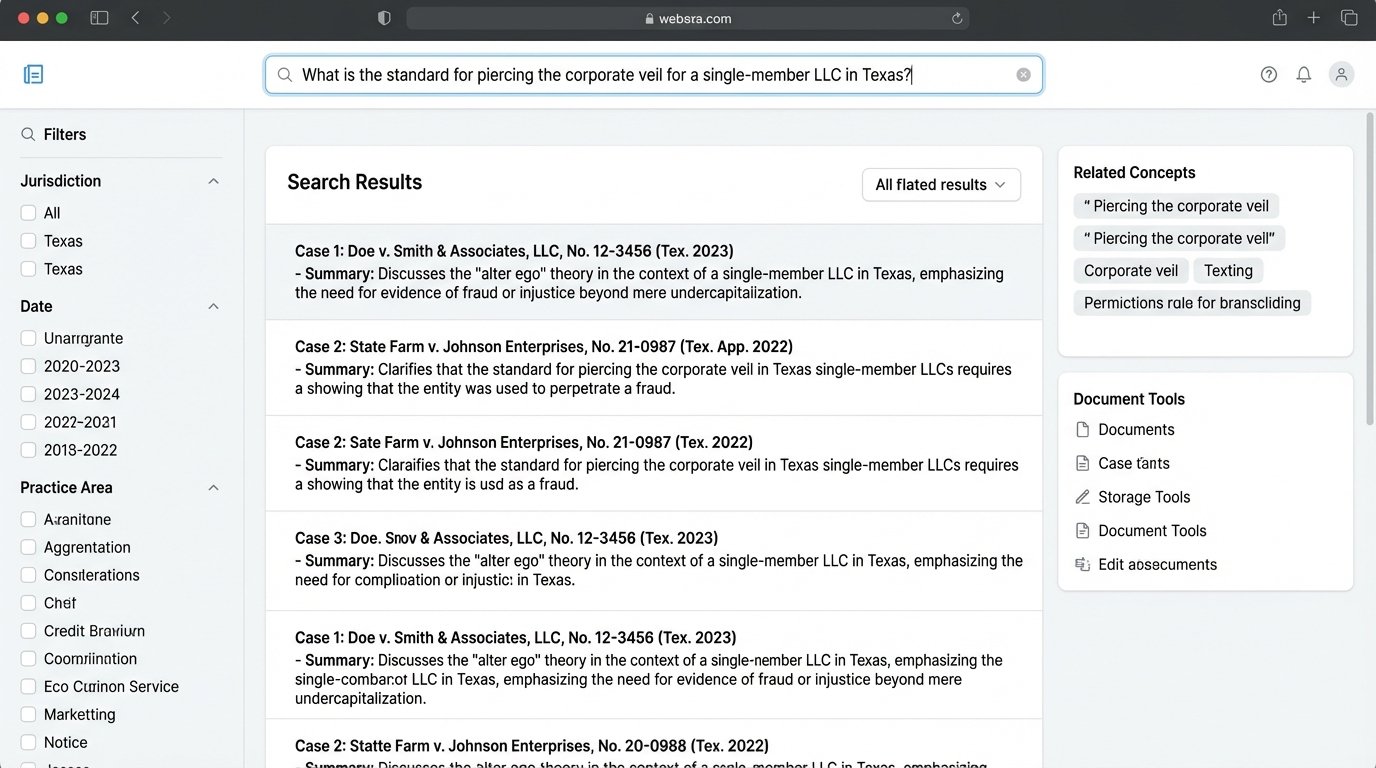
The next step is to refine this with Boolean operators and specific parameters. Even with natural language models, the old operators still work to narrow the field. You can inject constraints to force the model down a specific path.
Refining with Structured Inputs
A superior method is to use tools that allow structured queries, often via an API. Instead of a single text string, you construct a query object. This gives you granular control over the search parameters and forces the model to adhere to your logic. It is the difference between asking a question and giving a direct order.
Consider this simplified JSON structure for a hypothetical API call:
{
"queryText": "piercing the corporate veil",
"jurisdiction": "TX",
"court": ["Supreme Court of Texas", "Texas Court of Appeals"],
"dateRange": {
"start": "2015-01-01",
"end": "2023-12-31"
},
"exclude": {
"keywords": ["sole proprietorship", "partnership"]
},
"outcomeFilter": "plaintiff-favorable"
}
This approach transforms the query from a loose request into a set of precise instructions. It strips ambiguity from the process. You are telling the system exactly what to find and, just as important, what to ignore. The resulting dataset is smaller, more relevant, and significantly easier to validate.
Step 2: The Validation Gauntlet
The output from any AI research tool must be treated as presumptively false. Every case, every citation, and every summary requires independent verification. The speed of AI generation is its greatest strength and its most profound weakness. It can produce ten pages of plausible-sounding analysis in seconds, but one hallucinated citation can invalidate the entire work product and expose the firm to sanctions.
Validation is not a single action but a multi-stage process. The first stage is a simple existence check. Does the cited case actually exist? Does the citation number correspond to the correct case name and reporter? Automated tools can perform this initial scrub by cross-referencing against a reliable database like Westlaw, Lexis, or a court’s own docketing system. This catches the most flagrant fabrications.
Trying to inject AI-generated case summaries directly into a motion without this step is like piping raw sewage into the municipal water supply. The contamination is immediate, the damage is widespread, and the cleanup is brutally expensive.
Logic-Checking the AI’s Interpretation
The more subtle and dangerous error is misinterpretation. The AI might correctly identify a relevant case but completely misunderstand its holding or procedural posture. The summary it provides could be a distorted funhouse mirror reflection of the actual ruling. This requires human intervention.
The process is straightforward but tedious. Place the AI-generated summary side-by-side with the actual text of the opinion. The reviewer’s job is to logic-check the AI’s conclusions. Did the court actually say what the AI claims it said? Does the quoted language appear in the opinion, or is it a paraphrased invention? Is the context correct?
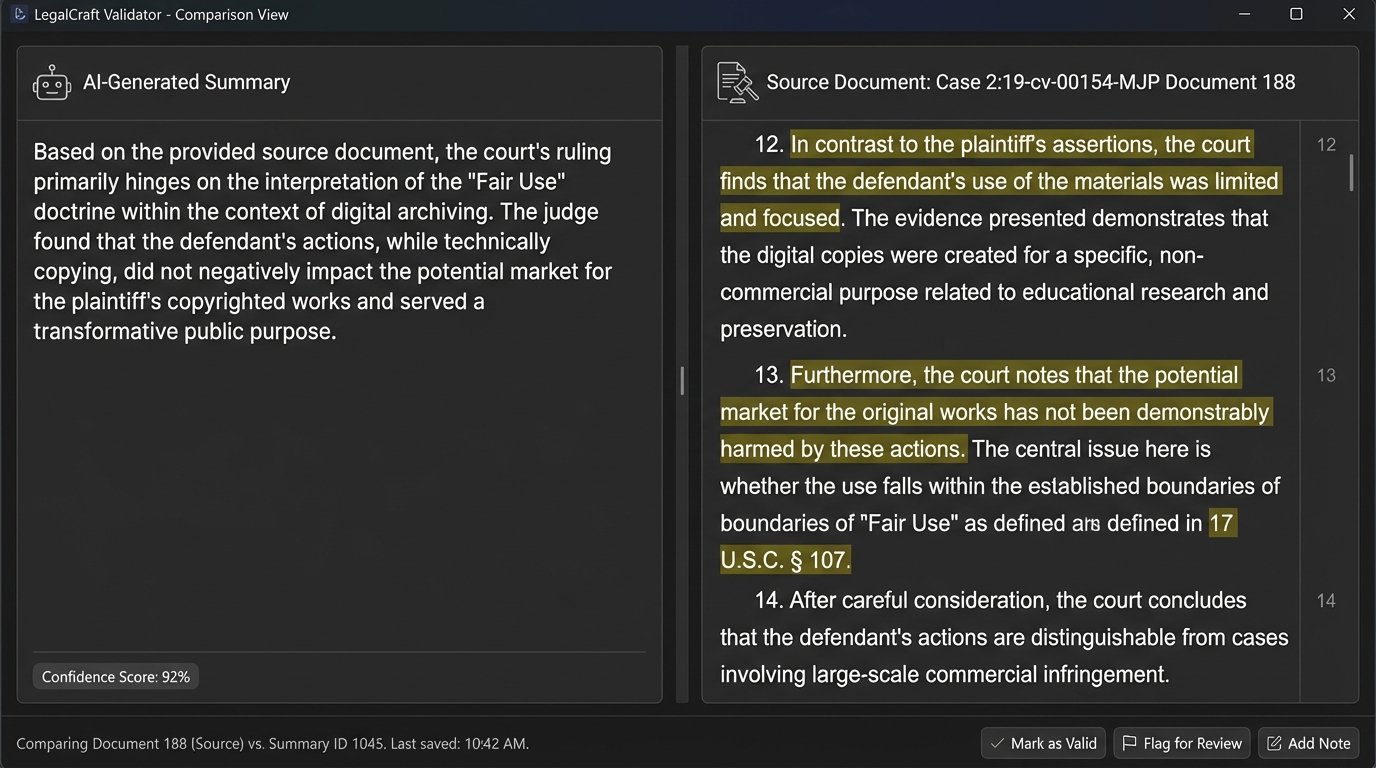
This is where firms often cut corners, and it is a fatal mistake. The time saved in generating the initial research is immediately lost if the output is unreliable. The goal is efficiency across the entire workflow, not just the initial search phase. There is a direct conflict between speed and data integrity here. You must choose integrity every time.
Step 3: Integrating Results into Legal Arguments
Once a set of cases has been validated, the next challenge is to integrate them into a coherent legal argument. An AI can give you the building blocks, but it cannot construct the building. It lacks the higher-order reasoning to understand narrative flow, persuasive writing, or the specific strategic goals of a brief.
The most effective method is to use the AI to generate annotated outlines. From your validated list of cases, you can prompt the AI with a command like: “Using the attached list of approved cases, create an outline for an argument that the defendant’s actions did not meet the standard of care. For each point in the outline, list the supporting cases and a one-sentence summary of their relevance.”
This output serves as a scaffold. It organizes the validated research into a logical structure that a lawyer can then build upon. The lawyer is responsible for weaving the narrative, adding the persuasive language, and ensuring the argument aligns with the overall case strategy. The AI acts as a paralegal, organizing the raw materials for the architect.
From Research to Document Assembly
The logical endpoint of this process is integration with document assembly tools. The structured data from your research phase, once validated, can be piped directly into a document template. For example, the case citations, summaries, and relevant quotations can populate a table of authorities or pre-populate sections of a brief.
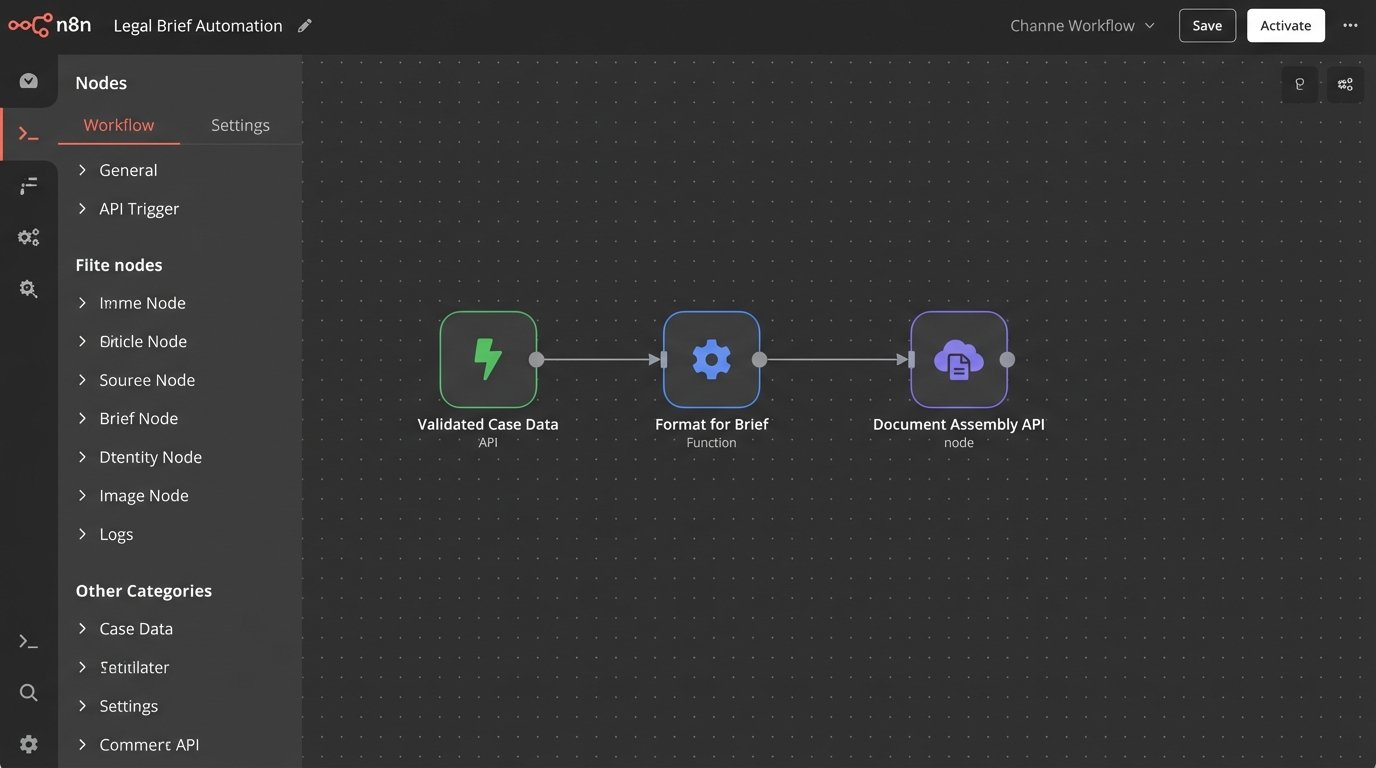
This requires an API-driven workflow. The research tool’s API sends the validated data to a middleware script. That script transforms the data into the format required by the document assembly platform’s API and injects it into the correct fields. This bypasses the need for manual copy-pasting, which is a major source of error. It closes the loop from initial query to final work product, creating a semi-automated, human-supervised assembly line.
Advanced Operations: Beyond the Search Box
The current generation of tools is just the beginning. The next frontier involves training smaller, specialized models on a firm’s own curated data. Using a technique called Retrieval-Augmented Generation (RAG), a system can be configured to base its answers primarily on a trusted, internal dataset, such as your firm’s historical briefs and memos. It uses the large public model for general language capabilities but is forced to pull its facts from your verified repository.
This dramatically reduces the risk of hallucination. The model is tethered to a ground truth that you control. Building such a system is not a trivial undertaking. It requires significant technical expertise in setting up vector databases and managing data pipelines. It is not a subscription service you can buy off the shelf. It is a piece of core infrastructure you have to build and maintain.
The payoff is a research assistant that understands your firm’s specific legal interpretations and past arguments. It stops being a generic tool and starts becoming a repository of institutional knowledge, one that can be queried in plain English. This is the real target, but it is a multi-year project, not a weekend install.