
The current conversation around AI in statutory research is fundamentally dishonest. It promotes a fiction of intelligent agents parsing legislative intent from digital ether. The reality is far less glamorous. Most platforms are just wrapping large language models around poorly structured, flat-text versions of statutes, creating a sophisticated but unreliable pattern-matching engine. The core engineering problem is not the AI model, it is the garbage data we force it to ingest.
Legislative code is not prose. It is a deeply nested logical structure built on hierarchy, definitions, exceptions, and cross-references. When you strip this structure and present it to an LLM as a monolithic block of text, you lose the very context that gives the law its meaning. Feeding a language model unstructured legislative text is like asking a master chef to cook a gourmet meal using a crate of unlabeled, dented cans. The chef is skilled, but the input is garbage. The result might look like food, but you wouldn’t bet your case on its integrity.
The Failure of Vector-Only Systems
Vector search is the technology powering most of these new tools. An embedding model converts chunks of text into numerical representations, or vectors. When you ask a question, your query is also converted into a vector, and the system finds the text chunks with the most mathematically similar vectors. This is powerful for identifying conceptual overlap, but it is blind to logical relationships. A section defining a term might be semantically close to a section that carves out an exception to that term. A vector-only system will present both with equal weight, completely missing the critical parent-child or exception-rule relationship.
This architectural flaw leads directly to the confident hallucinations we now see. The model finds text about “commercial vehicles” and “operating hours” and synthesizes a plausible-sounding but factually incorrect summary because it cannot differentiate between a general rule and a specific subsection that invalidates that rule under certain conditions. The system lacks a ground truth of the statute’s structure. It’s just guessing based on proximity and word choice.
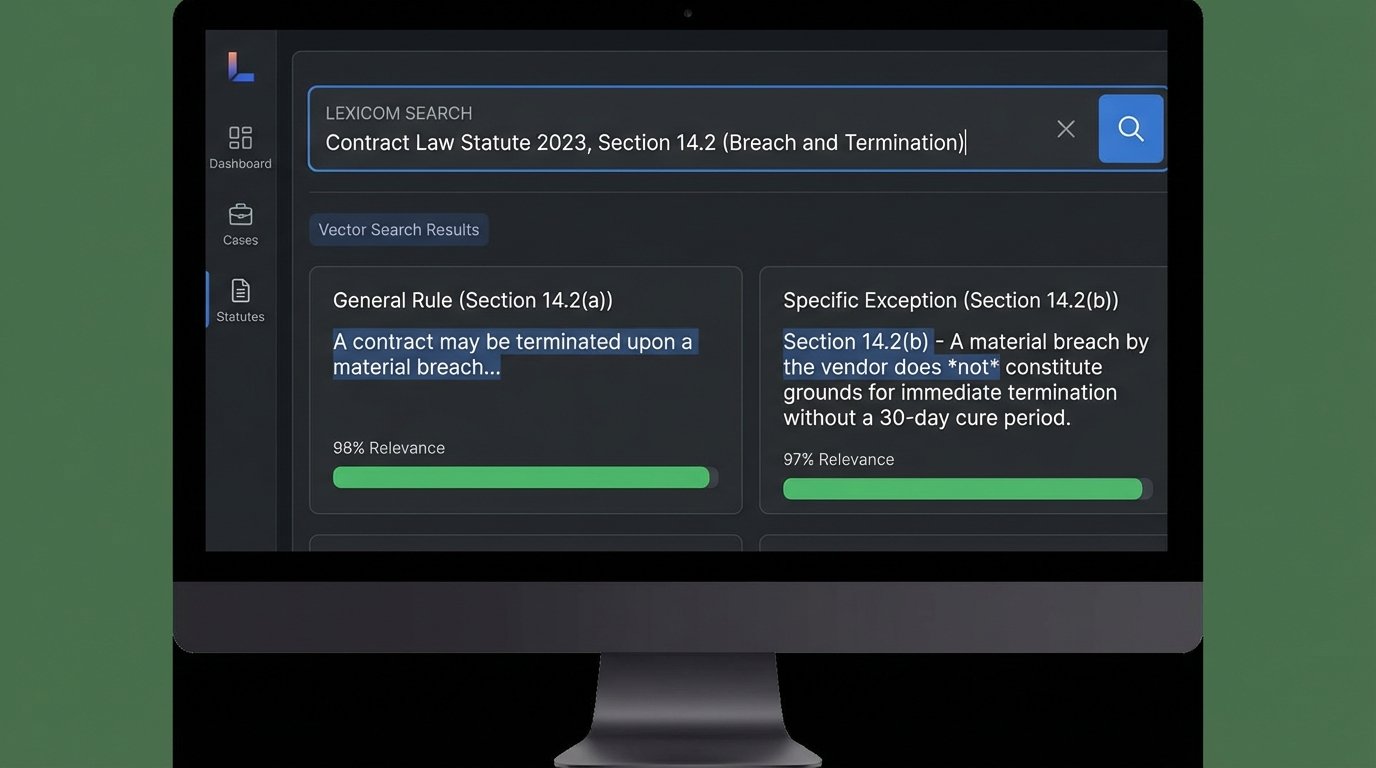
Building a Logical Skeleton First
A more durable solution requires that we stop treating statutes as documents and start treating them as data. The only way to enforce logical integrity is to model the legislative code as a knowledge graph before an LLM ever touches it. In this model, every statute, section, subsection, and defined term becomes a node. The relationships between them, such as “amends,” “repeals,” “cites,” or “is an exception to,” become the edges connecting these nodes.
Constructing this graph is the real work. It involves building sophisticated parsers to dissect raw legislative text from state and federal sources, identify the structural markers, and map the explicit and implicit connections. You cannot buy this off the shelf. It requires a dedicated data engineering effort to create and maintain these graphs as laws are amended, new court decisions are published, and regulations change. The upfront cost is significant, a wallet-drainer for firms expecting a cheap plugin.
The payoff is a system that can be queried with logical precision. Instead of asking a vague natural language question and hoping for the best, an attorney can query the graph directly. A query might look for all statutes that amend a specific section of the tax code, were passed after a certain date, and have been cited in appellate court decisions in a specific jurisdiction. The system returns a precise, filtered set of nodes. Only then is that highly relevant, contextually-rich data passed to a language model for summarization or analysis. This separates the logical retrieval from the linguistic generation, which massively reduces the surface area for hallucinations.
The Grimy Reality of Data Acquisition
Building this knowledge graph depends on access to the raw data, which is a significant technical barrier. Government websites are a patchwork of aging technologies. Some offer REST APIs that are poorly documented and aggressively rate-limited. Others provide massive, nightly XML or JSON dumps that require complex ETL (Extract, Transform, Load) pipelines to parse and normalize. Many smaller jurisdictions still offer nothing but HTML pages, forcing you to build and maintain brittle web scrapers.
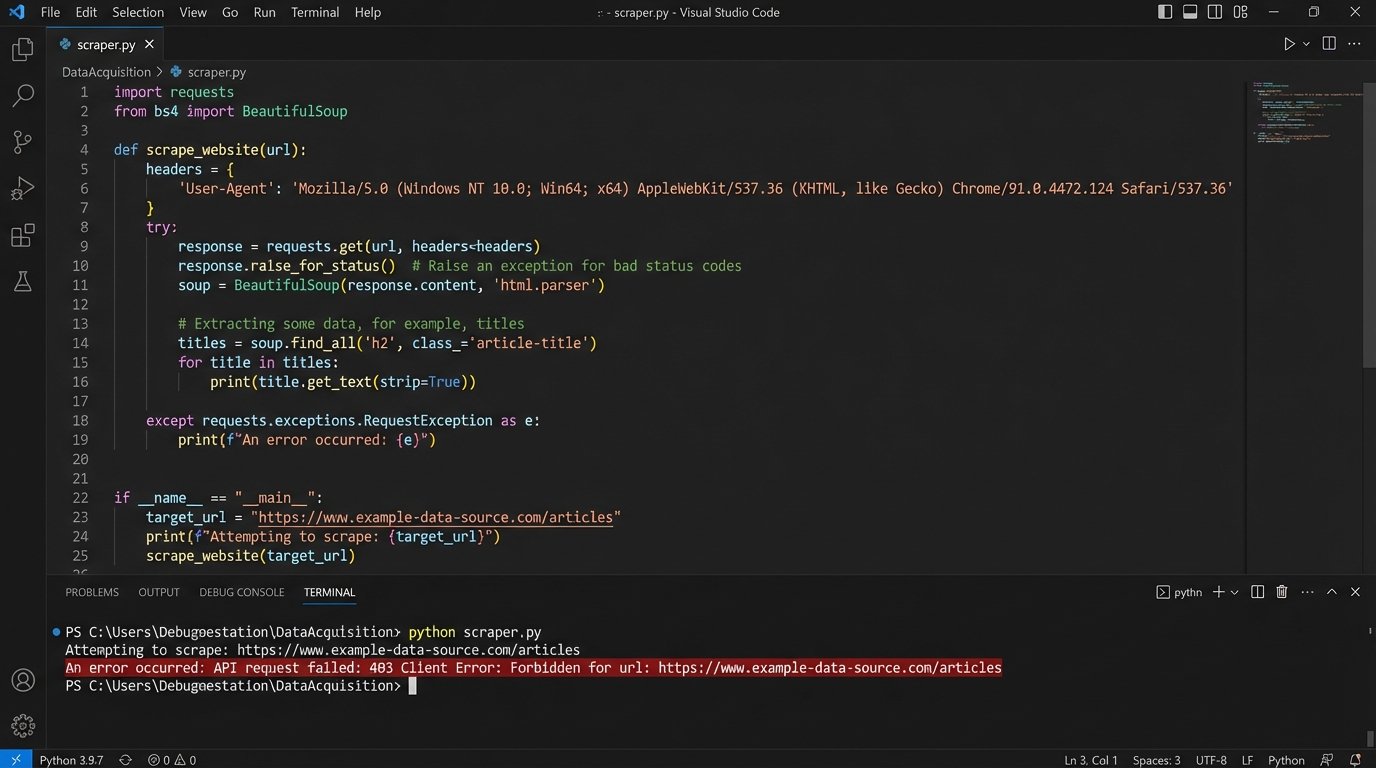
A simple scraper to pull down a single code section might look something like this in Python. Note the necessity of setting a user agent header just to avoid being blocked, and the reliance on a specific HTML element `id` that could be changed by a web developer at any time without notice, breaking the entire pipeline.
# THIS IS A SIMPLIFIED, HYPOTHETICAL EXAMPLE
import requests
from bs4 import BeautifulSoup
def fetch_statute_text(url):
headers = {'User-Agent': 'LegalResearchBot/1.0'}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status() # Will raise an HTTPError for bad responses
soup = BeautifulSoup(response.text, 'html.parser')
# Target a specific, often poorly documented, div
content = soup.find('div', id='main-content-statute')
if content:
# Force line breaks and strip whitespace for cleaner text
return content.get_text(separator='\n').strip()
return "Error: Could not find the specific content container."
except requests.exceptions.RequestException as e:
return f"API request failed: {e}"
# Example Usage
statute_url = "https://leginfo.example.gov/codes/hsc/11362.3"
text = fetch_statute_text(statute_url)
print(text)
This is the unglamorous, day-to-day work of legal automation. It involves error handling for network timeouts, logic to deal with changes in source formatting, and constant monitoring to ensure the data pipelines have not failed silently. Any firm that believes it can simply plug into a “legal AI” without confronting this data acquisition and structuring problem is being sold a fantasy.
Auditing the Black Box
A critical advantage of the knowledge graph architecture is auditability. When a vector-only system provides an answer, tracing its origin is difficult. It may have synthesized information from multiple text chunks, and the “weights” it assigned to each are opaque. It is a black box. This is unacceptable for legal work where every assertion must be backed by a specific citation.
The graph model provides a clear path for verification. Because the initial retrieval is a deterministic query against a structured database, the system can immediately return the exact nodes (statute sections, case citations) it used to inform the language model. The LLM’s role is reduced to summarizing a pre-verified, tightly-scoped set of information. This allows a human to instantly click through and validate the source of every claim, which is a non-negotiable requirement for any serious legal research tool.
Firms are forced to choose between two paths. They can adopt the fast, easy, but opaque vector-search tools that produce plausible but potentially indefensible results. Or they can invest in the slow, expensive, and technically demanding process of building a structured knowledge graph that provides auditable, logically sound answers. There is no middle ground. The former is a temporary productivity boost, the latter is a durable competitive advantage.
Beyond Statutes: Integrating Case Law and Regulations
The true power of a graph-based system emerges when you expand it beyond just statutory code. Case law represents the judicial interpretation of statutes. Regulations represent the executive branch’s implementation. In a flat-text world, these are separate silos of information. In a knowledge graph, they become interconnected data layers.
A new node representing a court decision can be linked to the specific statutory subsection it interprets with an “interprets” edge. A regulation from the Code of Federal Regulations can be linked to the public law that authorized its creation. This creates a multi-dimensional view of the law that is impossible to achieve with simple text search. This is shoving a firehose of context through a needle, forcing structure onto a chaotic universe of legal information.
The query potential becomes immense. An engineer could build a tool for attorneys to ask: “Show me all administrative regulations that implement Section 404 of the Clean Water Act, and then show me all federal court cases from the last 10 years that have cited those specific regulations.” A vector search engine would choke on such a precise, multi-step logical query. A knowledge graph is built for it. It would traverse the graph from the statute node to the connected regulation nodes, then filter those results based on their connections to case law nodes that meet the specified time and jurisdiction criteria.
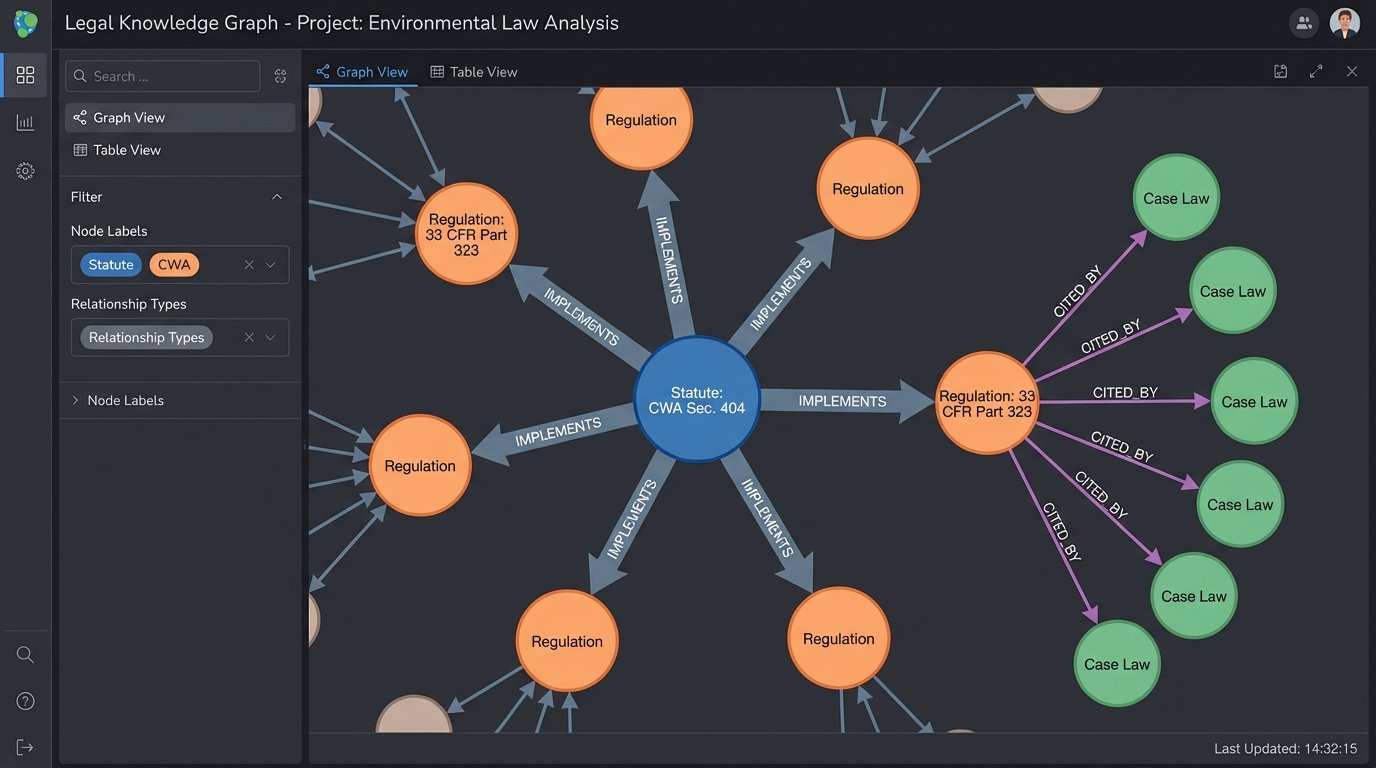
This is not a futuristic concept. The technology, primarily graph databases like Neo4j or Amazon Neptune, is mature. The barrier is the domain-specific expertise required to design the legal ontology (the formal naming and definition of the types, properties, and interrelationships of the nodes and edges) and the engineering discipline to build the data ingestion pipelines.
The future of AI in statutory research will not be defined by the cleverness of the language models. It will be defined by the quality of the underlying data architecture. Firms that continue to pour money into fancier front-end interfaces built on top of flat, unstructured text are building on sand. The real foundation is a well-structured, interconnected, and machine-readable graph of the law itself. That is the only path to building tools that are not just fast, but trustworthy.