
Manual statutory research is a known point of failure. The process relies on an attorney’s recall and keyword guessing, executed against data sources that are often poorly indexed and minutes out of date. We pretend this is rigorous, but it is a high-stakes gamble with a client’s outcome, disguised as due diligence.
The Brittle Foundation of Manual Lookups
The core problem is not the lawyer, it is the medium. Legal publishers built digital libraries as static repositories, not dynamic data sources. They bolted on a search function and called it innovation. This forces attorneys to pull information from a system that was never designed for real-time, context-aware queries. The architecture is fundamentally flawed for modern legal work.
This legacy model creates three immediate bottlenecks. First is latency. A bill passes, gets signed into law, and the official state legislative website updates. The third-party legal research platforms might not reflect this change for hours or even days. An attorney researching during that gap is operating on invalid data. Second is scope. Defining the correct jurisdictional and topical keywords is an art, not a science. A slightly different search query can return a completely different set of statutes, and there is no logic-check to flag the omission. Third is the sheer volume of text. No human can parse a thousand pages of regulatory code for subtle cross-references and amendments under billable pressure without error.
We accept this as the cost of doing business. It is not.
Gutting the Old Process: An Automation Framework
Building a statutory automation engine is about treating legal text as structured data, not as a digital book. The goal is to ingest, parse, and index statutes so they can be queried programmatically based on the factual parameters of a legal matter. This bypasses the fragile human-in-the-loop search process entirely.
The architecture is not trivial, but it follows a logical path. We are building a data pipeline specifically for statutory and regulatory content. It starts with ingestion and ends with a targeted alert hitting a lawyer’s dashboard. Every step introduces its own set of technical hurdles.
Step 1: Ingestion and Source Management
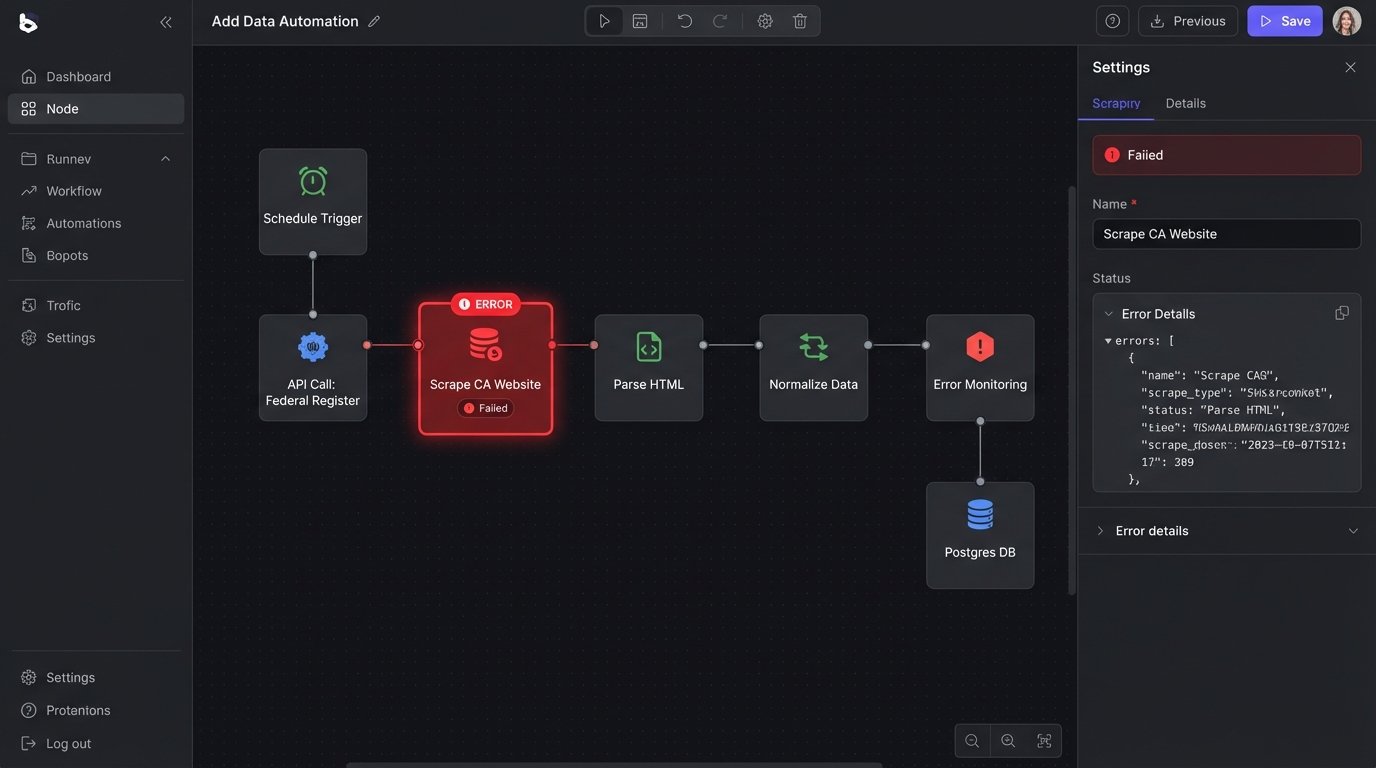
The first task is to get the raw text. You have two paths, both paved with problems. The first is scraping public sources like state legislature websites, the Federal Register, and municipal code libraries. This approach is cheap in terms of licensing but creates a massive maintenance burden. Websites change their HTML structure without warning, breaking your parsers. You will spend more time fixing scrapers than you will on improving the core logic.
The alternative is paying for API access from data aggregators. This is the wallet-drainer option. These services provide cleaner, semi-structured data but at a significant cost per call or via an enterprise subscription that makes CIOs nervous. You gain reliability but sacrifice control and budget. The data is often delivered in XML or JSON, which requires less pre-processing but still needs to be normalized against your internal data model.
A hybrid approach is often the most practical. Use APIs for federal and key state jurisdictions where accuracy is paramount. Deploy targeted scrapers for less-critical municipal or administrative codes. This requires a robust monitoring system to scream bloody murder the second a scraper fails.
Step 2: Parsing and Structuring Unruly Text
Once you have the raw text, the real work begins. Statutory language is a mess of nested sections, subsections, definitions, and exceptions. You need to convert this block of text into a structured object that a machine can understand. This is where most off-the-shelf NLP models fall apart. They were not trained on the peculiar syntax of legal writing.
Regular expressions are your first line of attack. You write patterns to identify and extract citations, section numbers, and effective dates. This is a brute-force method, but it is fast and effective for well-defined formats like the U.S. Code or the Code of Federal Regulations.
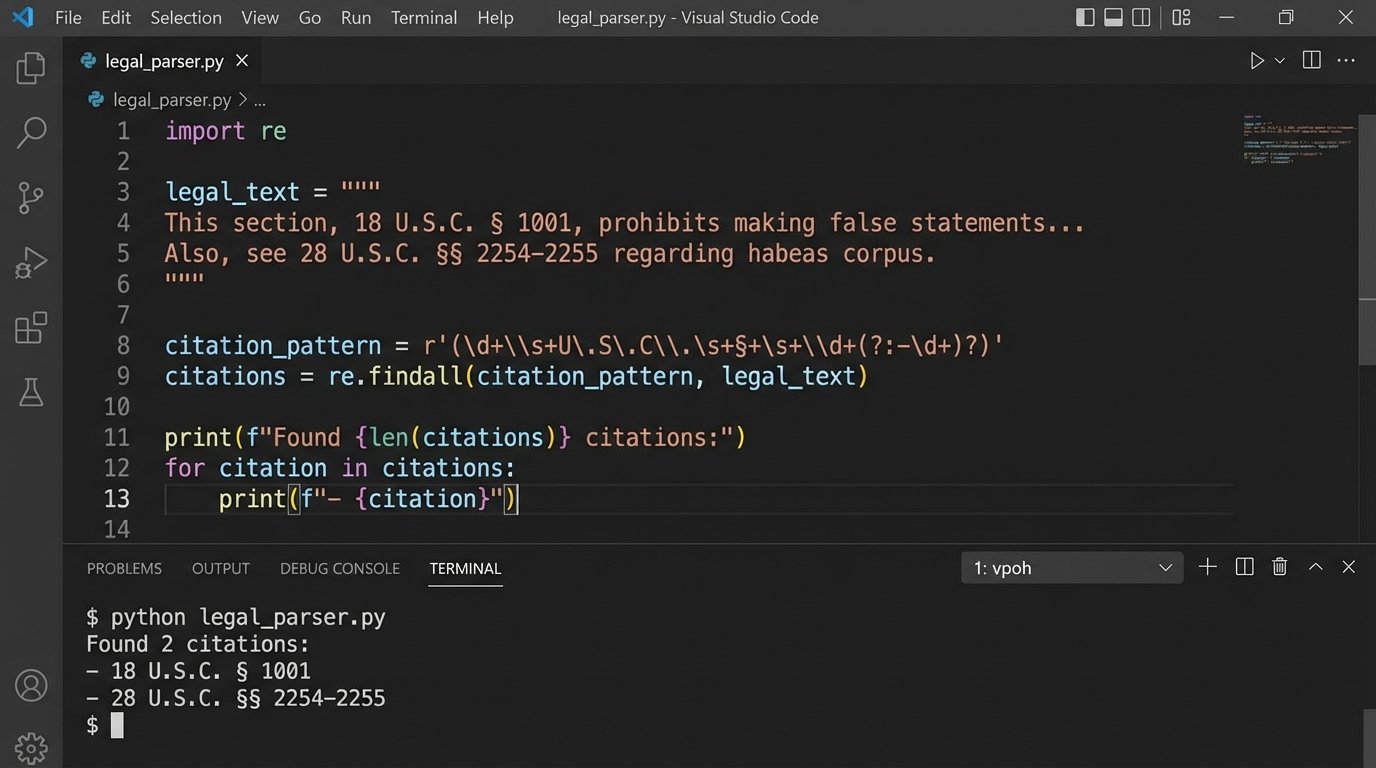
Here is a basic Python example using `re` to pull out U.S. Code citations. It is simple, but it demonstrates the principle of forcing structure onto chaos.
import re
statutory_text = """
As per 42 U.S.C. § 1983, any person who...
The definition of a security is found in 15 U.S.C. § 78c.
Further regulations are detailed in 26 U.S.C. § 501(c)(3).
"""
# Regex to find citations in the format: [Title] U.S.C. § [Section]
usc_pattern = re.compile(r'(\d+)\s+U\.S\.C\.\s+§\s+([\w\(\)]+)')
citations = usc_pattern.findall(statutory_text)
# The output will be a list of tuples: [('42', '1983'), ('15', '78c'), ('26', '501(c)(3)')]
print("Extracted U.S. Code Citations:")
for title, section in citations:
print(f"Title: {title}, Section: {section}")
Regex gets you about 70% of the way there. For the remaining 30%, you need more advanced NLP. This means training custom Named Entity Recognition (NER) models using libraries like spaCy or NLTK. You feed the model thousands of examples of annotated legal text to teach it how to identify concepts like “governing law,” “liability clause,” or “statute of limitations.” This is a significant investment in data science resources.
The entire parsing process is like rebuilding a car engine from a bucket of unlabeled parts. You have all the pieces, but the instructions are missing, and you must infer the relationships between them by identifying patterns and structures. It is tedious, error-prone, but absolutely necessary.
Step 3: Building the Relevance and Alerting Engine
With a database of structured statutes, you can stop searching and start matching. The system ingests the core facts of a new matter: jurisdiction, area of law (e.g., “employment,” “real estate”), and key entities involved. The engine then queries the structured data to find directly applicable statutes. This is not a keyword search. It is a query against indexed fields like `jurisdiction`, `effective_date`, and custom tags generated by your NLP models.
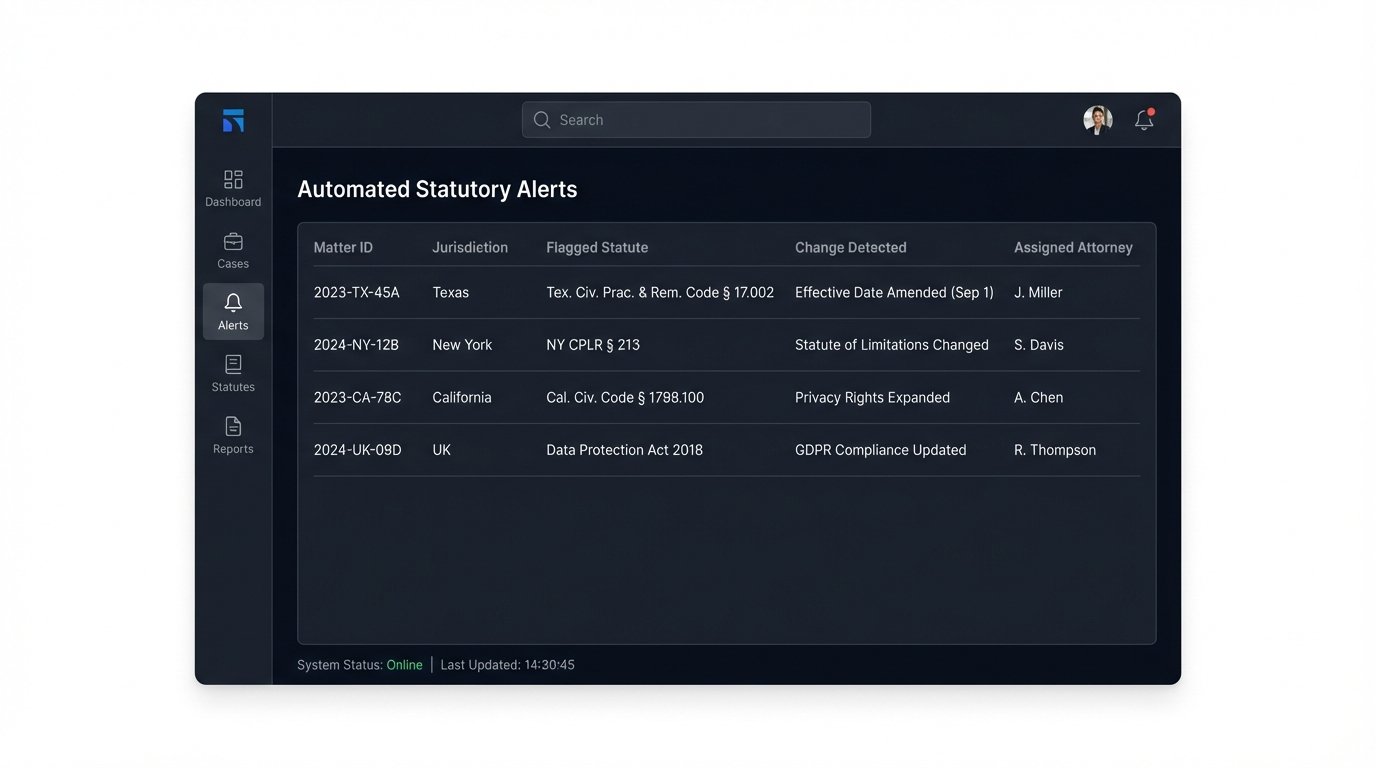
The real power comes from monitoring changes. The ingestion pipeline runs continuously or on a schedule. When it pulls in a new version of a statute, it performs a diff operation against the stored version. If a change is detected, it triggers a notification. This is not just a simple text comparison. A sophisticated diff algorithm can identify what changed: was a single word altered, a subsection deleted, or a new cross-reference added? The system then checks which legal matters are linked to that statute and pushes a highly specific alert to the responsible attorney.
The alert might read: “Warning: California Civil Code § 1714.2 was amended. Section (b) regarding liability for emergency care has been modified. This may impact your matter XYZ.” This is infinitely more valuable than a generic newsletter about legislative updates.
The Inescapable Trade-Offs
This automated approach is not magic. It introduces its own set of complexities and requires a different kind of vigilance. Building and maintaining such a system is a constant balancing act.
Speed vs. Data Integrity
You can configure your ingestion pipeline to run every five minutes, giving you near real-time updates. However, this increases the load on your sources and your processing servers. It also raises the probability of ingesting a partially updated or malformed file during a website’s deployment cycle. A slower, hourly or nightly pull is safer and puts less stress on the infrastructure, but it reintroduces latency. You are trading seconds of delay for a lower risk of data corruption.
A faster pull rate forces you to build more resilient validation logic. Each piece of ingested data must pass a series of checks before it overwrites the existing record. Is the text properly formed? Are the expected sections present? Does the metadata make sense? This validation logic adds complexity to the pipeline.
Cost vs. Control
Relying on third-party data APIs is the fast-track to getting a system running. It offloads the entire mess of scraping and parsing to a vendor. The downside is that you are now completely dependent on their update schedule, their data schema, and their pricing model. When they decide to deprecate an endpoint or double their fees, you are stuck.
Building everything in-house gives you total control but is a massive resource sink. You need a dedicated team of engineers to build the scrapers, parsers, and monitoring tools. This team will be in a permanent war against website redesigns and anti-bot measures. The initial build is expensive, and the ongoing maintenance is a recurring operational cost that is hard to justify on a balance sheet.
Semantic Search vs. Explainability
Advanced systems move beyond structured queries and into the realm of semantic search. You can use models like BERT to convert both the statutes and the matter descriptions into vector embeddings. This allows the system to find conceptually related statutes even if they do not share any keywords. It can surface risks that a human would have missed.
The problem is that these models are black boxes. A vector search might flag a tangentially related environmental regulation for a real estate transaction. When the partner asks *why* that statute was flagged, the answer is a shrug and a reference to multi-dimensional vector space. The results can be brilliant but are often impossible to explain, which erodes trust with attorneys who are trained to demand logical, citable reasoning.
A deterministic, rule-based engine is easier to debug and its results are always explainable. It is also dumber. It will never find the “unknown unknowns.” The choice is between a system that is transparent but limited, or one that is powerful but opaque.
The End of Manual Scavenging
Implementing statutory automation is not about replacing attorneys. It is about augmenting them with a system that handles the mechanical, high-volume, low-cognition task of monitoring and initial identification. It frees up their time to focus on the much harder work of interpretation and strategy.
The transition requires a shift in mindset. Law firms must start thinking of their legal intelligence as a data problem, not a library problem. They must be willing to invest in the technical infrastructure and talent to build these systems. The firms that continue to rely on manual lookups and keyword guessing will be outmaneuvered by those who have weaponized data to see the entire field.