
Manual statutory research is a known failure point. The process relies on the flawed assumption that a human can consistently identify, track, and interpret legislative changes across dozens of jurisdictions without error. This assumption collapses under the weight of modern regulatory volume and the chaotic frequency of amendments. An automated system doesn’t just reduce attorney hours; it erects a defense against malpractice rooted in outdated legal code.
The core problem is not incompetence, but scale. A single associate cannot be expected to manually monitor the Federal Register, 50 state legislative websites, and countless municipal code repositories for changes relevant to a dozen active matters. The result is a dependency on third-party platforms that are often slow to update and lack the specificity required for niche practice areas. Building an internal, automated system bypasses this dependency, shifting control back to the firm.
Deconstructing the Manual Process Failure
Human researchers operate with inherent biases and physical limitations. They search for expected keywords, potentially missing novel phrasing in new amendments. They get fatigued. Their attention drifts. An automated script suffers from none of these weaknesses. It executes its logic identically every time, whether it’s processing the first statute or the ten-thousandth.
Consider the risk of a missed sunset provision or a subtle change in a single definition buried within a 500-page bill. For a human, finding this is a matter of luck and extreme diligence. For a well-constructed script, it’s a deterministic outcome of a text comparison algorithm. The system flags the change, logs the metadata, and alerts the responsible parties without fail. This isn’t about speed; it’s about verifiable completeness.
Architecture of a Statutory Monitoring Engine
The foundation of any automated research system is a robust data ingestion pipeline. This pipeline has three primary components: the scraper, the parser, and the data normalizer. Each stage presents unique engineering challenges that separate a functional prototype from a production-ready tool.
The initial step involves building web scrapers targeted at specific government websites. These are notoriously inconsistent sources. Some provide clean APIs or XML feeds, but most offer nothing but poorly structured HTML or, worse, scanned PDF documents. We primarily use Python with libraries like Scrapy for crawler management and BeautifulSoup for HTML tree navigation. The scrapers are brittle by nature; a minor website redesign can break them, demanding constant monitoring and maintenance.
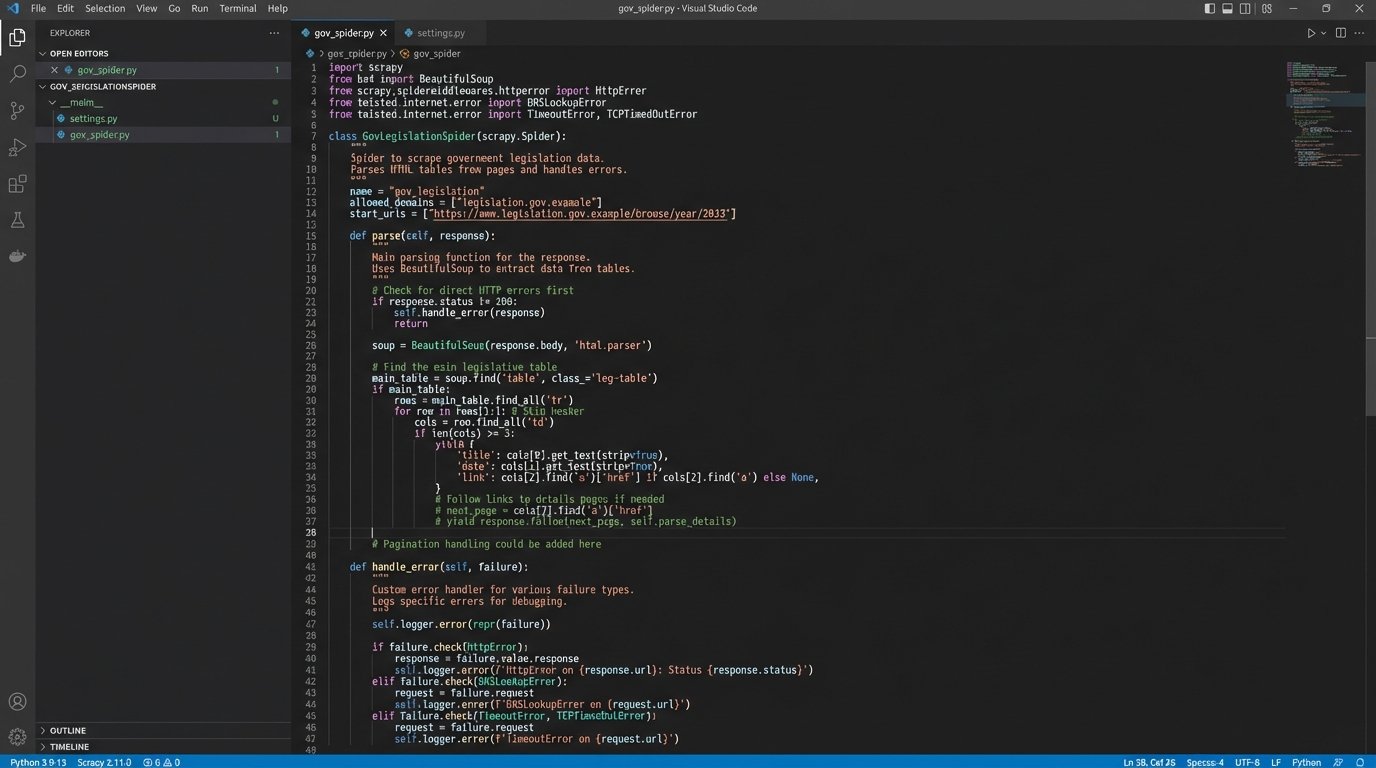
You have to build the scrapers defensively. They must handle connection timeouts, HTTP errors, and unexpected content types. Logic-checking for a “last updated” date on the source page is critical to avoid re-processing unchanged content, saving both bandwidth and compute cycles. This isn’t a “set it and forget it” component; it requires a dedicated maintenance schedule.
Parsing Unstructured Legislative Text
Once the raw HTML or text is acquired, the parser’s job is to extract structured data from it. This is the most complex part of the process. The goal is to identify and isolate key elements: the statute or regulation number, section titles, the body text, effective dates, and amendment history. Regular expressions are the primary tool here, used to locate and capture citation patterns.
For example, to extract a U.S. Code citation, you might use a regex pattern that looks for a title number, the abbreviation “U.S.C.”, and a section number.
import re
text = "Pursuant to 18 U.S.C. § 922(g)(1), it is unlawful for certain persons..."
pattern = r'(\d+)\s+U\.S\.C\.\s+§\s+([\w\(\)]+)'
match = re.search(pattern, text)
if match:
title = match.group(1)
section = match.group(2)
print(f"Found Citation: Title {title}, Section {section}")
This code block demonstrates a simple extraction. A production system requires dozens of such patterns to handle variations across federal, state, and local codes. The real headache comes from PDFs, which often require an Optical Character Recognition (OCR) layer like Tesseract. OCR introduces its own error rate, turning “§ 1001” into “S 1001” or “8 1001”, which requires another layer of validation and cleanup logic to fix.
Database Schema and Version Control
The parsed data cannot be simply dumped into a text file. It must be structured and stored in a database to be useful. A relational database like PostgreSQL is a solid choice for this. The schema needs to accommodate not just the text of the law, but its history. A simplified table structure might look like this:
- Statutes: `statute_id`, `jurisdiction`, `code_title`, `citation_slug`
- Versions: `version_id`, `statute_id`, `section_text`, `effective_date`, `scraped_at`, `source_url`
This structure allows you to store every historical version of a statute that the system has ever scraped. An attorney can then query the system not just for the current law, but for the text of a specific section as it existed on a particular date. This is impossible with traditional research tools and is invaluable for litigation involving past events. The trade-off is storage cost. This historical data accumulates quickly, demanding significant database capacity and query optimization to keep searches fast.
Building this system is less like constructing a pristine digital library and more like trying to engineer a water purification plant at the mouth of a chaotic, muddy river. The raw input is dirty and unpredictable, and your job is to force it through a series of filters and checks until you get something clean and reliable on the other side. The maintenance never stops because the river never stops flowing.
Developing a Usable Query and Alerting System
A database full of legislative text is useless without an interface for attorneys to query it. A simple internal web application with a search interface is the minimum requirement. The real value, however, comes from moving beyond basic keyword search to more advanced query types.
Temporal queries are a direct benefit of the versioned database schema. A user should be able to input a citation and a date to retrieve the exact text of the law on that day. Relational queries are another powerful feature, allowing a user to find all statutes that reference another specific statute. This helps map the impact of a legislative change across the entire legal code.
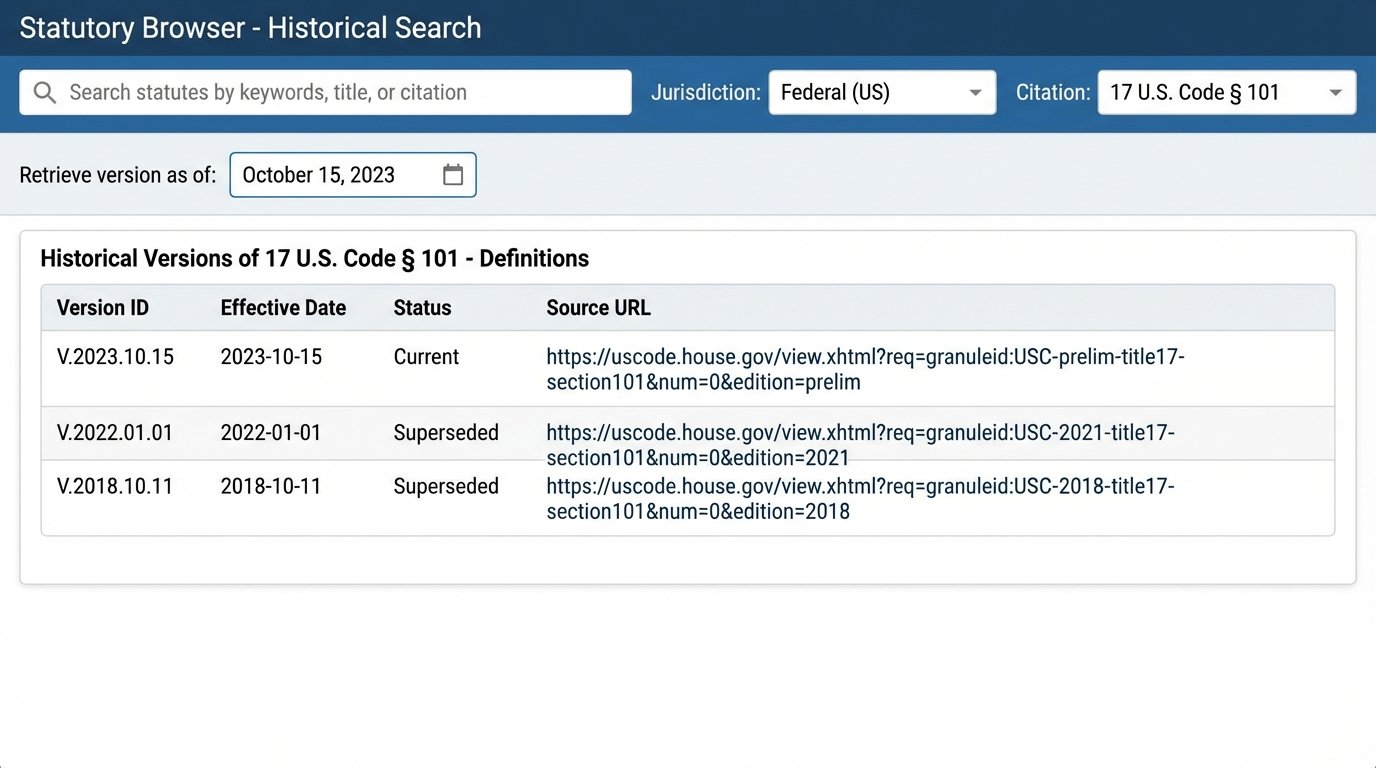
The most impactful component is the alerting subsystem. This flips the research model from a passive “pull” to an active “push.” A scheduled job runs daily or weekly, re-scraping all targeted sources. It then performs a diff, a text comparison, between the newly scraped content and the most recent version stored in the database for each statute.
If any changes are detected, the system automatically generates an alert. This alert can be an email, a Slack message, or an entry in a practice management system. The alert should contain a link to the source, a summary of the change (e.g., “Section 2 text modified,” “Section 5 repealed”), and a side-by-side comparison of the old and new text. This mechanism all but eliminates the risk of an attorney citing a law that was amended last week.
The Operational Realities and Hidden Work
An automated system is not a magic box. It is a complex piece of infrastructure that requires specialized upkeep. The primary vulnerability is source rot. When a government agency redesigns its website, the scrapers targeting that site will fail. This requires an engineer to diagnose the failure, rewrite the scraper logic to accommodate the new site structure, and redeploy it. This is not an occasional problem; it is a constant, recurring maintenance task.
Data validation is another critical but labor-intensive process. How do you know the scraper didn’t miss a section or that the parser didn’t mangle a definition? You need to build secondary checks. This can include running record counts, validating citation formats, and having a human perform periodic spot-checks to compare the database content against the original source. Without this quality control loop, you risk propagating errors throughout the firm.
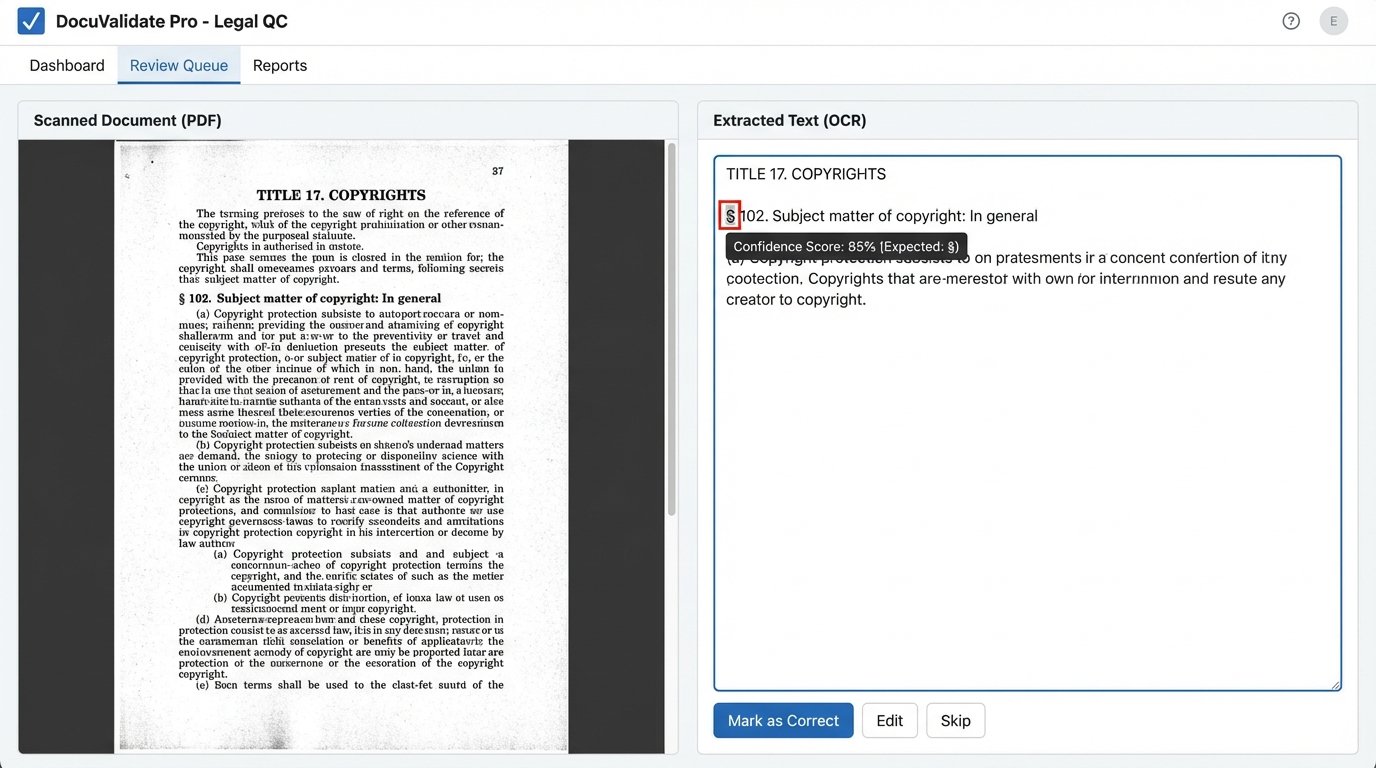
The most difficult sources are those that only publish in scanned PDF formats. These documents are fundamentally hostile to automation. OCR is an imperfect technology, and the output frequently contains errors that need to be corrected manually. For these sources, the system functions more as a notification tool that flags a new document for human review, rather than a fully automated ingestion pipeline. It’s a wallet-drainer to try and achieve 100% accuracy on poor-quality sources, so you have to engineer for an 80% solution and a clear workflow for human intervention on the rest.
Implementing this type of automation is a strategic decision. It replaces unpredictable, high-risk manual labor with a predictable, lower-risk combination of system performance and scheduled engineering maintenance. It gives the firm a proprietary intelligence asset that directly impacts case strategy and risk management. The system itself becomes a weapon, allowing legal teams to operate with a degree of certainty that firms relying on manual research can never match.