
Let’s gut the marketing narrative. AI-powered statutory research is not an intelligent entity interpreting law. It is a probabilistic text generator chained to a vector database of legislative text. The core engineering problem is not legal analysis, it is signal versus noise. Your primary job when using these tools is to act as a ruthless filter for statistically plausible nonsense, otherwise known as hallucinations.
Most platforms are fundamentally the same architecture. They ingest massive volumes of statutes, regulations, and sometimes case law, then convert this text into numerical representations called embeddings. When you submit a query, the system is not “understanding” your question. It is performing a mathematical similarity search to find vectors in its database that are closest to the vector of your query. The result is then fed to a Large Language Model (LLM) to generate a human-readable summary. This process is fast, but it is also fragile.
Failure to understand this mechanical process is the root cause of bad outputs and wasted hours. You are not collaborating with a junior associate. You are operating a complex text-matching machine.
Deconstructing the Source Corpus
The quality of an AI research tool is a direct function of the quality and freshness of its underlying data. Before committing to any platform, you must pressure the vendor for specifics on their data ingestion pipeline. A slick user interface can easily mask a stale or incomplete corpus of law. This is the first layer of due diligence.
Ask these direct questions:
- What is the update frequency for the United States Code?
- How do you ingest and process state-level statutes and session laws?
- What is your latency for newly enacted legislation?
- Are administrative codes and regulations included, and from which agencies?
- Can you provide a manifest of your data sources?
A vendor’s hesitation to answer these questions is a significant red flag. They are likely scraping public government websites, which are often poorly structured and updated erratically. A premium tool should have direct data feeds and a dedicated team to normalize and structure the incoming text. Without that, you are just paying for a prettier version of a public search engine.
The structure of the data also matters immensely. A system that simply ingests raw text as massive documents will perform poorly. A properly engineered system will chunk the statutes into logical sections, subsections, and clauses. This granularity allows the vector search to pinpoint highly specific and relevant passages instead of returning an entire chapter because a few keywords matched. This is the difference between a surgical tool and a blunt instrument.
Query Formulation: Bypassing Natural Language Traps
The temptation is to treat the search bar like a conversation. This is a mistake. Natural language queries are ambiguous and force the model to guess your intent. You need to structure your queries to be as precise as possible, injecting keywords and structural references that guide the search algorithm. You are not asking a question. You are constructing a filter.
Consider the task of finding regulations on data breach notifications for financial institutions in California. A naive query would be:
"What are the data breach notification requirements for banks in California?"
This query is poor because it uses colloquial terms like “banks”. The system might miss relevant statutes that use more formal terms like “financial institution” or “credit union”. A better, more structured query forces the system down a specific path:
"California Civil Code AND 'data breach' AND 'notification' AND 'financial institution' AND requirements within 72 hours"
This revised query uses boolean operators and specific terminology. It constrains the search space, reducing the probability of irrelevant results. You are essentially pre-filtering the documents before the LLM even begins to generate a summary. This reduces the processing load and, more importantly, limits the model’s “creative” freedom to hallucinate connections that do not exist.
Structuring API Calls for Automation
For any serious workflow integration, you will bypass the UI and hit the tool’s API directly. This provides programmatic control over the search parameters and allows you to pipe the output into other systems. Most legal tech APIs are an afterthought, so expect sparse documentation and unpredictable rate limits. The goal is to structure a request that is machine-readable and unambiguous.
Here is a basic Python example demonstrating a structured API call to a hypothetical legal research service. Notice how the parameters are broken out into distinct fields, removing the ambiguity of a single natural language string.
import requests
import json
api_key = "YOUR_API_KEY"
api_endpoint = "https://api.legalresearch.ai/v1/statutory-search"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
query_payload = {
"jurisdiction": "CA",
"corpus": "civil_code",
"must_contain": ["data breach", "notification", "financial institution"],
"timeframe_filter": {
"field": "notification_requirement_hours",
"operator": "less_than_or_equal",
"value": 72
},
"return_fields": ["citation", "text", "effective_date"]
}
response = requests.post(api_endpoint, headers=headers, data=json.dumps(query_payload))
if response.status_code == 200:
results = response.json()
for result in results.get('data', []):
print(f"Citation: {result['citation']}, Effective: {result['effective_date']}")
print(f"Text: {result['text'][:200]}...") # Print snippet
else:
print(f"Error: {response.status_code} - {response.text}")
This approach forces the backend system to perform a structured search against its metadata. It is far more reliable than sending a blob of text and hoping the Natural Language Processing (NLP) layer correctly parses your intent. You are dictating the search logic instead of suggesting it.
Validating AI Annotations and Summaries
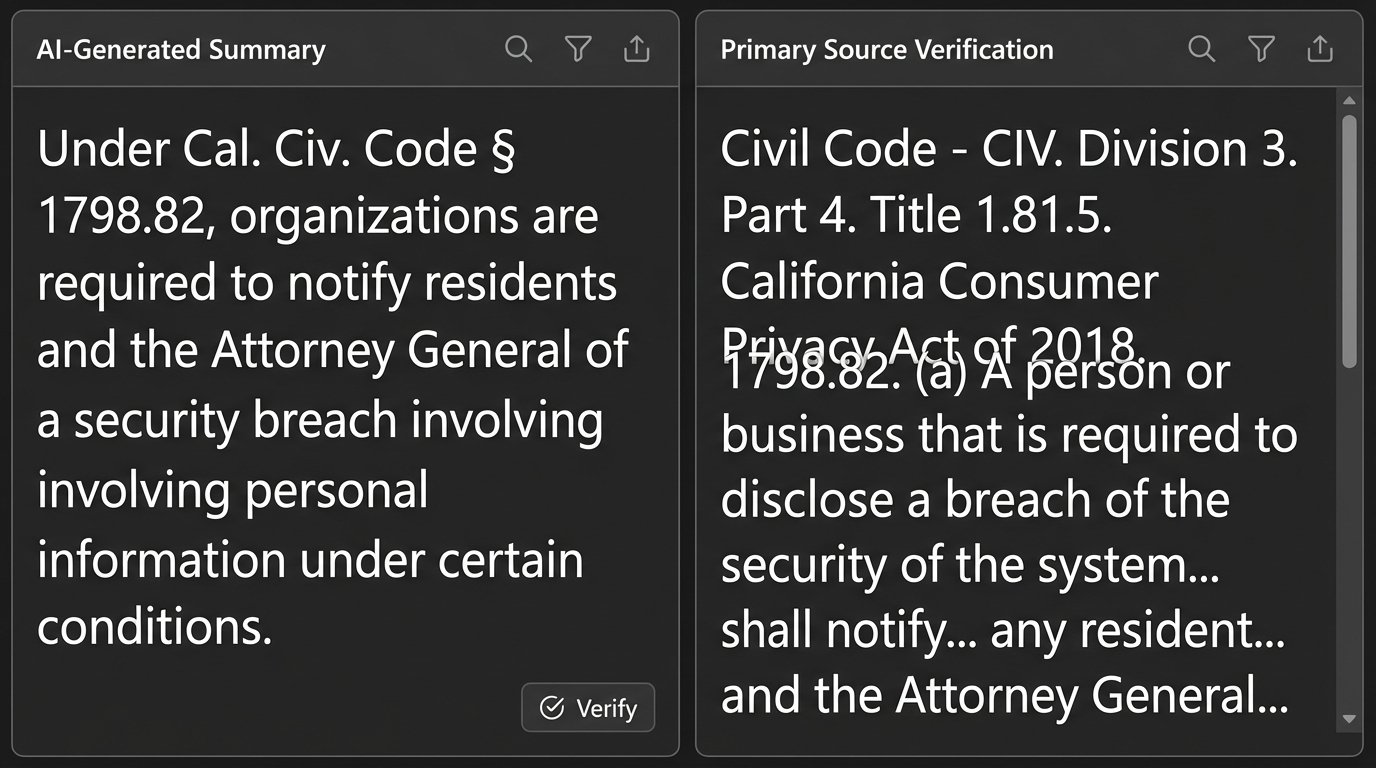
The text generated by an AI tool, whether it is a summary or a so-called “annotation,” is a synthetic product. It is a statistical reconstruction, not a direct quote. Every single output must be verified against the source text. There are no exceptions to this rule. Treating the AI’s summary as fact is professional malpractice waiting to happen.
Your validation workflow must be systematic:
- Isolate the Citations: The first step is to strip all the generated citations from the summary text. The AI is good at identifying potentially relevant statutes. This is its primary strength.
- Retrieve Primary Source: For each citation, pull the full text of the statute from a reliable, primary source. Do not use the snippet provided by the AI tool. Go to the official government source or a trusted platform like Westlaw or LexisNexis.
- Perform Direct Comparison: Read the AI’s summary paragraph next to the actual text of the statute. Does the summary accurately reflect the meaning, conditions, and exceptions outlined in the law? Look for subtle misinterpretations or omissions.
- Check for Hallucinated Crossovers: AI models often blend concepts from multiple statutes into a single, coherent-sounding paragraph that is legally incorrect. This is particularly dangerous. You must verify that every claim in a summary sentence is supported by the single statute it purports to analyze. It’s like trying to shove a firehose through a needle; the model will compress and merge distinct legal ideas to fit the output format, losing critical detail in the process.
This manual logic-check is non-negotiable. The current generation of AI is a powerful tool for discovery, not for analysis. It can find the needles in the haystack. Your job is to verify that they are actually needles and not just shiny pieces of straw.
Integrating AI Output into Case Management
Raw AI output has no place in a case management system (CMS) or a client-facing document. It is unprocessed data that must be refined. The goal of integration is not to copy-paste. It is to create a structured workflow where AI-discovered statutes become trackable research items within your existing system.
A functional workflow involves treating the AI output as a JSON object to be parsed and injected into specific fields in your CMS. The API response from the Python script above could be used to automatically create research tasks. For each valid statute found, the script could push a new task to your CMS with the citation, a link to the primary source, and a field for attorney notes.
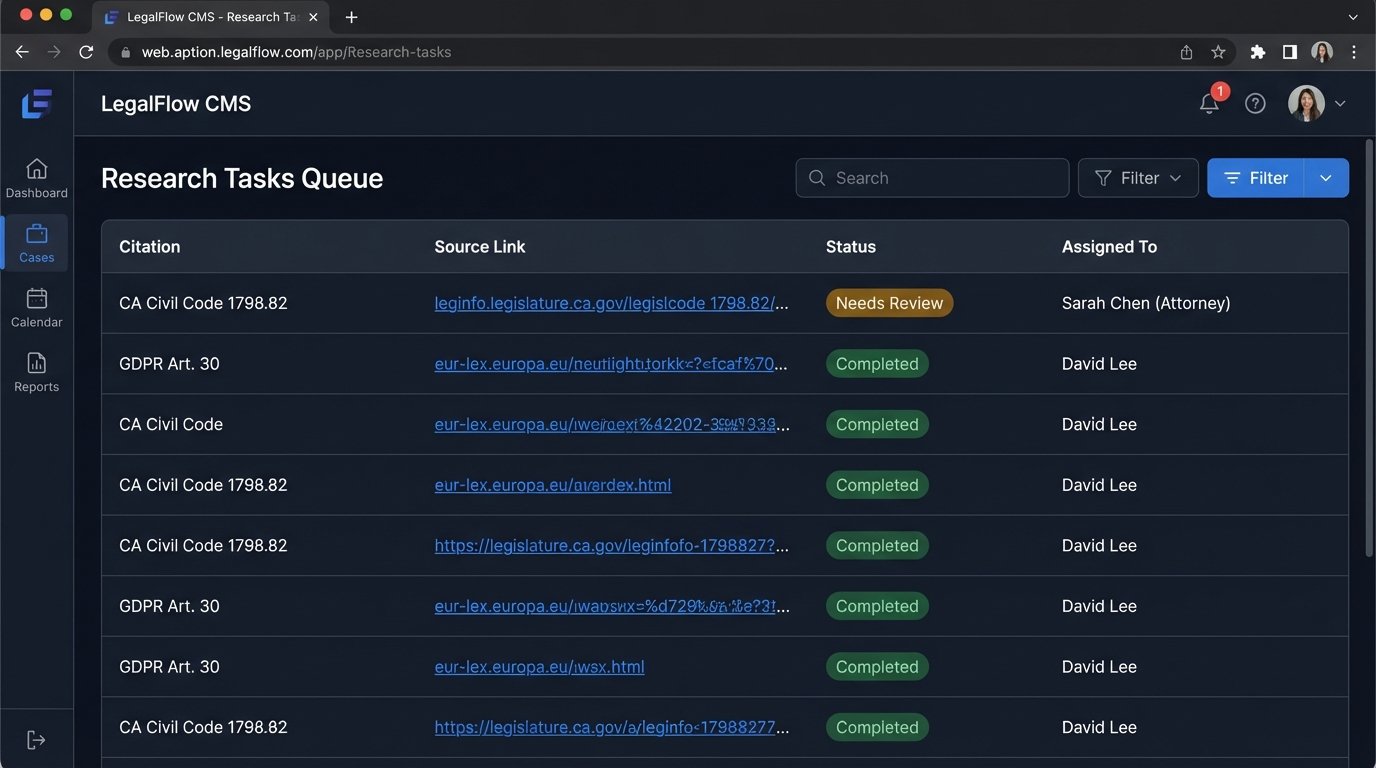
This bridges the gap between AI-driven discovery and human-driven analysis. The AI’s role ends once it delivers the list of potential statutes. From that point, your internal legal workflow takes over. The output from the AI tool becomes the starting point for human work, not the endpoint.
The API Reality Check
The biggest roadblock to effective integration is the state of most legal tech APIs. Many are poorly documented, lack granular controls, and have inconsistent performance. Before building any integration, you must pressure the vendor for their API documentation, service level agreements (SLAs), and a developer sandbox. If they cannot provide these, their tool is a closed system, a “walled garden,” suitable only for manual, one-off searches. It cannot be a foundational piece of an automated legal operations stack.
A mature API will allow you to not only pull data but also to provide feedback. A `POST /feedback` endpoint where you can flag incorrect summaries or hallucinated citations is a sign of a vendor that is serious about improving their model. A vendor without such a mechanism is not a partner. They are just a content provider.
Ultimately, these AI research tools are powerful but limited. They are query accelerators, not legal reasoners. They can surface statutory text with incredible speed, but they possess no actual understanding of the legal principles contained within that text. The human operator remains the most critical component in the chain, responsible for validation, interpretation, and strategic application. Do not let a slick interface convince you otherwise.