
Statutory research is fundamentally a reactive process. An associate gets a task, queries a monolithic database, and pulls a point-in-time snapshot of a code section. The entire workflow is predicated on the assumption that the law is static between queries. This assumption is broken, and building a practice on top of it is like building on a sinkhole.
The databases we pay a fortune for are little more than well-indexed archives. They excel at retrieving what was, not flagging what will be. Their update cycles are opaque, their APIs are often creaky, and their value proposition is stuck in a pre-cloud era. The future is not a better search bar on top of this old model. It’s an event-driven architecture that treats legislative change as a real-time data stream to be processed, not a document to be periodically retrieved.
Deconstructing the Latency Problem
The delay between a bill’s passage and its reflection in a commercial legal database is a critical failure point. This latency isn’t just a matter of hours. It can be days. In that gap, advice is given and strategies are formed based on obsolete information. The process typically involves human editors cleaning, formatting, and annotating the statutory text before ingestion. This manual gating mechanism, intended to add value, introduces unacceptable risk.
We are still forcing lawyers to perform a human-driven `diff` command against legislative updates. They manually track bills, read summaries, and attempt to mentally map proposed changes onto their active caseload. This is an expensive, non-scalable, and error-prone workflow. The system relies on the perpetual availability of a lawyer’s attention, which is the most constrained resource in any firm.
Automating this means ditching the query model. Instead of asking “what is the text of Statute X,” the system must be built to react when “Statute X has been amended by Bill Y.” This requires a shift from search to surveillance.
The Architecture of Legislative Surveillance
Building a proactive monitoring system requires a different set of tools and a completely different mindset. It involves stitching together data ingestors, a normalization layer, an event bus, and a subscription service that can inject alerts into existing firm software. The goal is to pipe legislative events directly into the context of the work they affect.
First comes ingestion. This means hooking directly into the source feeds, which are almost never clean. Federal data from sources like the Congress.gov API is reasonably structured JSON. State-level data is a chaotic mess, ranging from barely usable XML feeds to websites that look like they were designed in 1998. You will spend an inordinate amount of time writing and maintaining scrapers and parsers for dozens of inconsistent formats.
Trying to normalize data from 50 different state legislature websites is like trying to build a single engine that runs on diesel, gasoline, and Diet Coke. It requires a lot of pre-processing.
Once you have the raw text of a proposed bill, the real work starts. The normalization layer must strip out procedural junk, identify the specific code sections being targeted for amendment, and parse the actual language of the proposed change. This is where tools like regular expressions and named entity recognition models from libraries like spaCy become critical. The output of this layer is a structured object, something like this:
{
"bill_id": "HB-1138",
"jurisdiction": "CA",
"status": "IN_COMMITTEE",
"sponsors": ["Jane Doe", "John Smith"],
"proposed_changes": [
{
"statute_code": "Cal. Civ. Proc. Code § 437c",
"action": "AMEND",
"change_type": "REPLACE_TEXT",
"old_text_substring": "A party may move for summary judgment",
"new_text_substring": "A party, after 60 days from the general appearance of an opposing party, may move for summary judgment"
}
]
}
This structured data is then published as an event to a message queue like RabbitMQ or Kafka. This decouples the ingestion process from the alerting process. Multiple downstream systems can then consume these events without directly coupling to the fragile scraping logic. The case management system, a document management system, or a dedicated risk dashboard can all subscribe to the same event stream.
From Monitoring to Prediction
Tracking enacted laws is useful, but it’s still reactive. The real leverage comes from using the data stream of pending legislation to predict potential impact on active cases. This is not about building a crystal ball. It is about building a system to flag high-relevance bills that warrant a human lawyer’s review. It is a system for automated issue spotting.
The technical core of this predictive layer is vectorization. We convert the text of our internal case documents (briefs, motions, client summaries) and the text of proposed bills into numerical representations, or embeddings. Using a sentence transformer model, we can map a paragraph of legal text to a high-dimensional vector. The geometric proximity of these vectors in vector space corresponds to their semantic similarity.
A simplified check for relevance then becomes a cosine similarity calculation between a case vector and a bill vector. A score close to 1.0 indicates high semantic overlap, while a score near 0 indicates they are unrelated. This bypasses the limitations of simple keyword matching, which would miss a bill that uses different terminology to address the same legal concept.
Building the Impact Score
Relevance alone is not enough. A highly relevant bill that has a zero percent chance of passing is just noise. The system must also factor in the probability of enactment. This requires a model that weighs factors like the bill’s current legislative stage (introduction vs. floor vote), sponsorship (is it a bipartisan bill from a committee chair?), and historical data on similar bills.
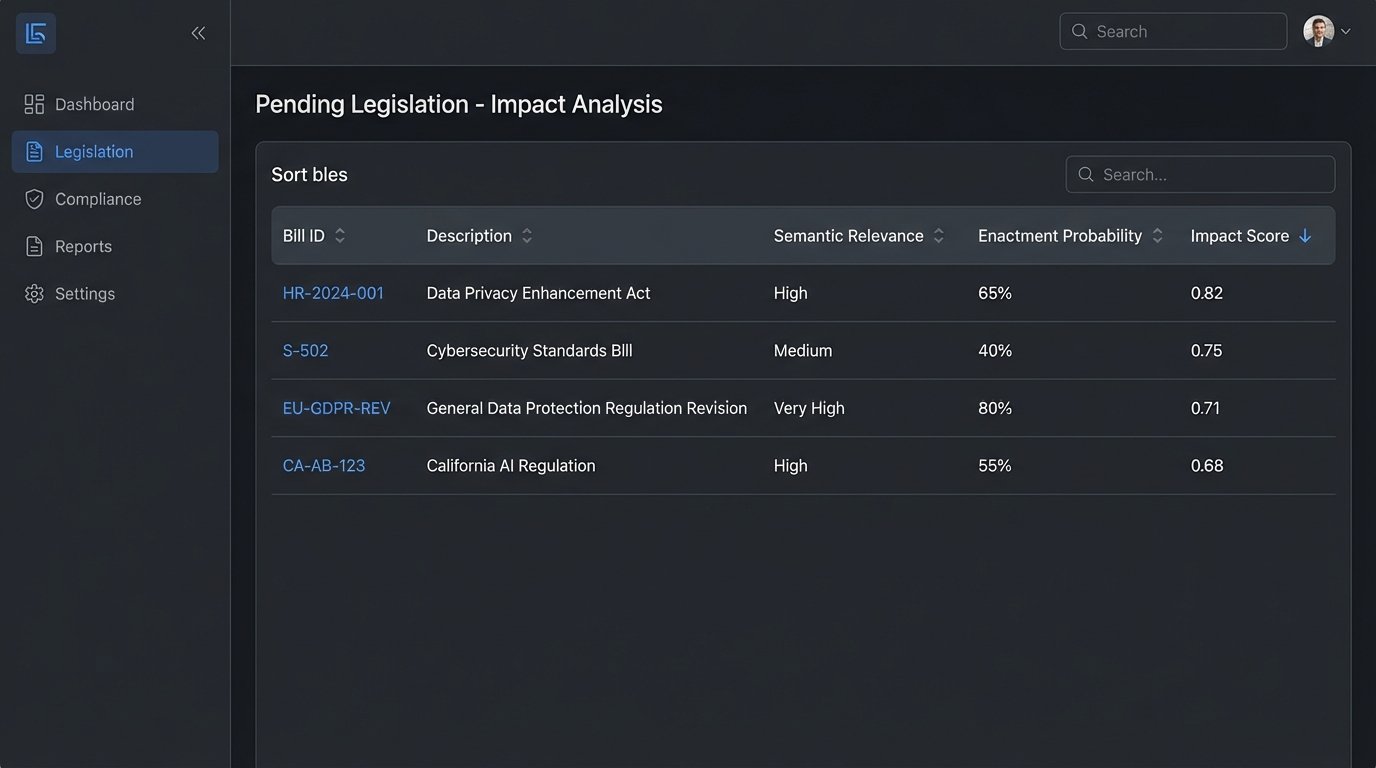
The impact score is a function of both relevance and probability.
Impact Score = (Semantic Relevance Score) x (Enactment Probability Weight)
A dashboard can then present a lawyer with a ranked list of pending bills that are most likely to affect their specific case. Instead of the lawyer hunting for information, the information is pushed to them, prioritized by a machine-calculated risk score. This logic-checks the relevance before consuming an attorney’s time.
Implementation: Tools, Costs, and Headaches
This is not a weekend project. Standing up an architecture like this is a serious engineering effort with significant operational costs.
Data Sources: You can use commercial aggregators like LegiScan for a cleaner API feed, but it’s a wallet-drainer. Rolling your own scraping infrastructure with Python frameworks like Scrapy is cheaper upfront but saddles you with a massive long-term maintenance burden as websites change their layouts without warning.
Vector Database: Do not attempt to run vector similarity searches at scale in a traditional relational database like PostgreSQL. It will choke. The workload is purpose-built for a vector database like Pinecone, Weaviate, or ChromaDB, which uses specialized indexing algorithms like HNSW to perform approximate nearest neighbor searches efficiently.
Compute and NLP: The NLP models for parsing and vectorization require significant GPU resources, especially during the initial indexing of your firm’s document repository. This is a cloud workload. Expect a hefty AWS or GCP bill for both processing and storage of the vector embeddings.
The Final Hurdle: CMS Integration
The most painful part of the entire project will be integrating it with your firm’s case management system. Most legacy legal tech platforms have APIs that are, charitably, an afterthought. You will fight with sluggish endpoints, absurd rate limits, and documentation that was clearly written five years ago and never updated.
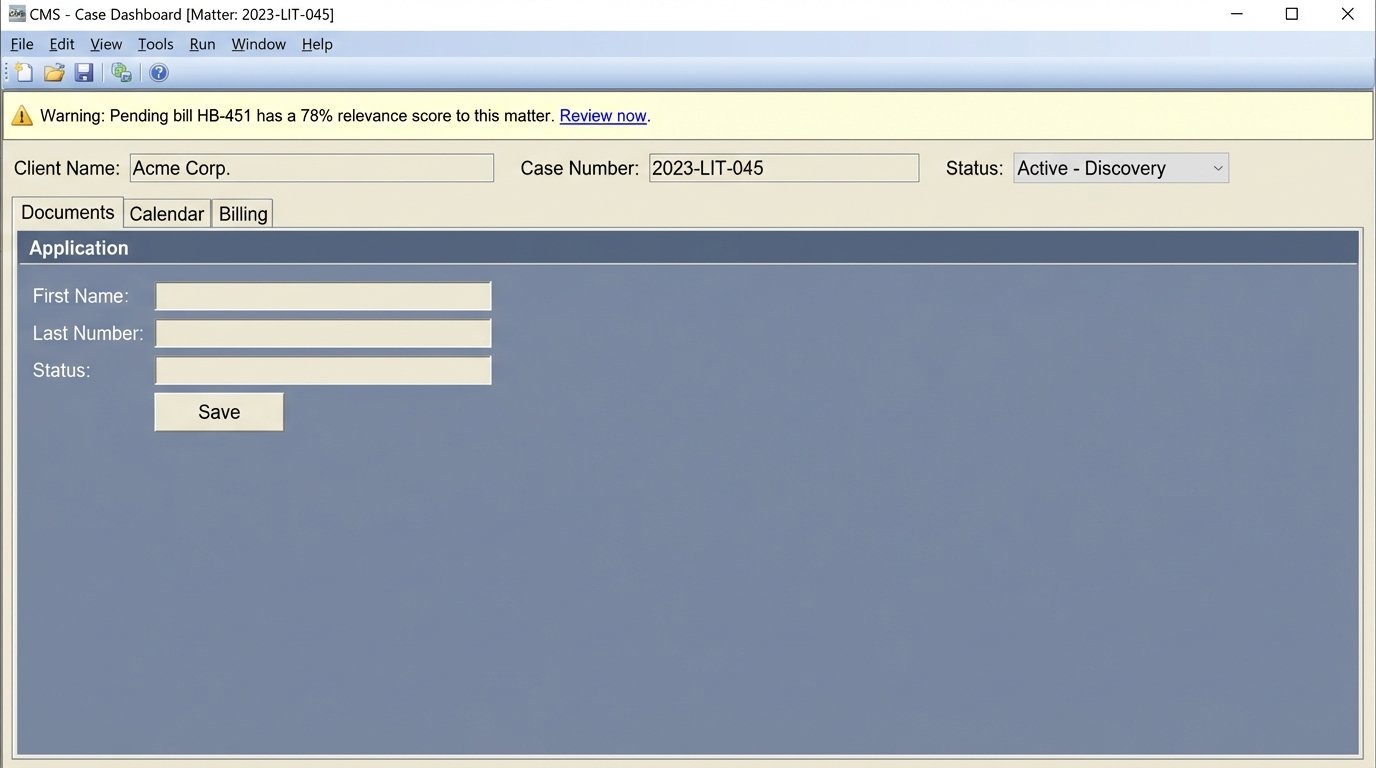
The goal is to inject a contextual alert directly into the user interface for a specific matter. For example, a small, non-intrusive banner on the case dashboard that reads: “Warning: Pending bill HB-451 has a 78% relevance score to this matter.” This requires forcing data into a system that was never designed to receive it. It is often a brittle, ugly process of reverse-engineering and custom middleware.
The future of statutory research is not about finding laws faster. It is about building systems that alert us to their change before we even think to look. The technology to do this exists today. It is not a research problem. It is an engineering and integration problem. Building this is expensive and difficult, but it is less expensive than advising a client based on a law that no longer exists.