
Statutory research is a brute-force activity. You are paid to read, cross-reference, and find the single sentence in a hundred-page bill that guts your client’s position. The standard tools for this are glorified keyword alerts. They match strings, dump a link in your inbox, and call it a day, leaving you to sift through a mountain of false positives. This is an inefficient allocation of expensive human capital.
The correct approach is to stop thinking about monitoring as keyword matching and start thinking of it as semantic filtering. An AI-driven system does not care if a bill contains the word “liability.” It cares if the bill substantively alters the definition or application of liability within a specific legal context. This guide details the architecture for building such a system, moving from dumb alerts to focused, analytical intelligence. We will bypass the marketing and get straight to the mechanics.
Prerequisites: The Data Ingestion Layer
You cannot analyze data you do not have. The first and most painful step is getting reliable, machine-readable access to legislative text. Your targets are state legislature websites, the Federal Register, and other government portals. Most are a tangled mess of archaic HTML, inconsistent document formats, and nonexistent APIs. Forget slick, well-documented endpoints; you are building a web scraper.
The primary tool for this is Python, using libraries like `requests` to fetch the web page and `BeautifulSoup` to parse the HTML. The goal is to script a process that navigates to the relevant bill tracking page, identifies links to new or amended legislation, and systematically extracts the raw text of the statutes. This process is fragile. A minor website redesign will break your scraper, requiring immediate maintenance. It is a constant, low-level operational tax you must be willing to pay.
Some services like LegiScan offer APIs that abstract away the scraping. This is a speed vs. cost decision. Using their API gets you structured data immediately but introduces a dependency and a recurring subscription fee. Building your own scraper costs developer time upfront and ongoing maintenance but gives you direct control over the data source. For initial prototyping, an API is faster. For a production system, direct scraping is often more resilient and cost-effective over time, assuming you have the technical resources to support it.
Building a Semantic Alerting Engine
Once you have a stream of legislative text, the real work begins. A traditional alert system would simply run a regex or keyword search over this text. We will inject a large language model (LLM) to perform a first-pass analysis. This logic-checks the relevance of a change before it ever hits an attorney’s screen.
The process is straightforward:
- Ingest Text: Your scraper or API feed provides the full text of a newly introduced or amended bill.
- Chunk the Data: LLMs have context window limits. You cannot feed a 300-page bill into the model in one go. The text must be broken into smaller, logical chunks. Splitting by section or paragraph is a common starting point.
- Generate Embeddings (Optional but Recommended): For very large documents, you can convert text chunks into vector embeddings. This allows you to perform a semantic search to find the most relevant chunks related to your area of interest (e.g., “tax implications for LLCs”) and only send those to the LLM for full analysis. This saves on processing time and API costs.
- Prompt the LLM: This is the critical step. You will craft a prompt that instructs the LLM to act as a specialized legal analyst. The prompt forces the model to summarize the change and evaluate its potential impact based on a specific legal context you provide.
A weak prompt gets you a weak analysis. A precise, context-rich prompt gets you actionable intelligence.
Sample Implementation in Python
This is a conceptual script. It assumes you have a function `get_bill_text(url)` that returns the raw text of a bill. Here, we use the OpenAI API, but this could be swapped for a local model or another provider.
import openai
import os
# Assume openai.api_key is set in your environment variables
def analyze_legislative_change(bill_text, legal_context):
"""
Uses an LLM to analyze a bill's text for a specific legal context.
"""
prompt = f"""
You are a senior paralegal specializing in {legal_context}.
Analyze the following legislative text.
1. Provide a concise, one-sentence summary of the core change.
2. Identify the specific statutes or regulations being amended.
3. Assess the potential impact on clients operating in the {legal_context} sector.
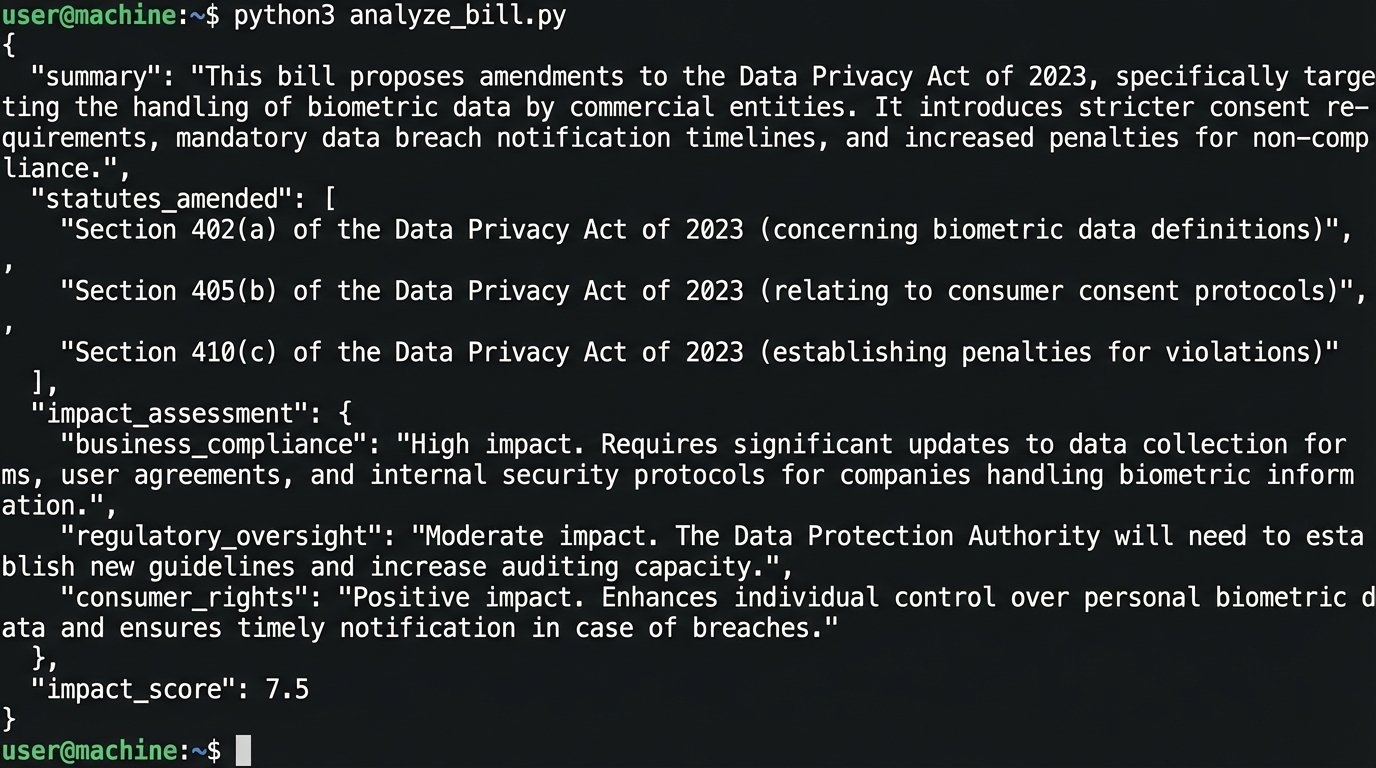
4. Assign an impact score from 1 (minor typo correction) to 5 (substantive policy shift).
5. Output the result as a JSON object with keys: 'summary', 'statutes_amended', 'impact_assessment', 'impact_score'.
Legislative Text:
---
{bill_text[:8000]} # Truncate to fit within context window for this example
---
"""
try:
response = openai.ChatCompletion.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": "You are a helpful legal analysis assistant."},
{"role": "user", "content": prompt}
],
response_format={"type": "json_object"}
)
analysis = response.choices[0].message.content
return analysis
except Exception as e:
# Proper error handling is non-negotiable in production
print(f"An error occurred: {e}")
return None
# Example Usage
bill_url = "http://legis.state.gov/bills/HB1234"
# bill_text = get_bill_text(bill_url) # Your scraping function
bill_text = "Text of a fictional bill that amends Section 25-A of the state commerce code to include digital assets under the definition of property..."
context = "corporate finance and digital assets"
# The output is a structured JSON string, not just a wall of text.
json_analysis = analyze_legislative_change(bill_text, context)
print(json_analysis)
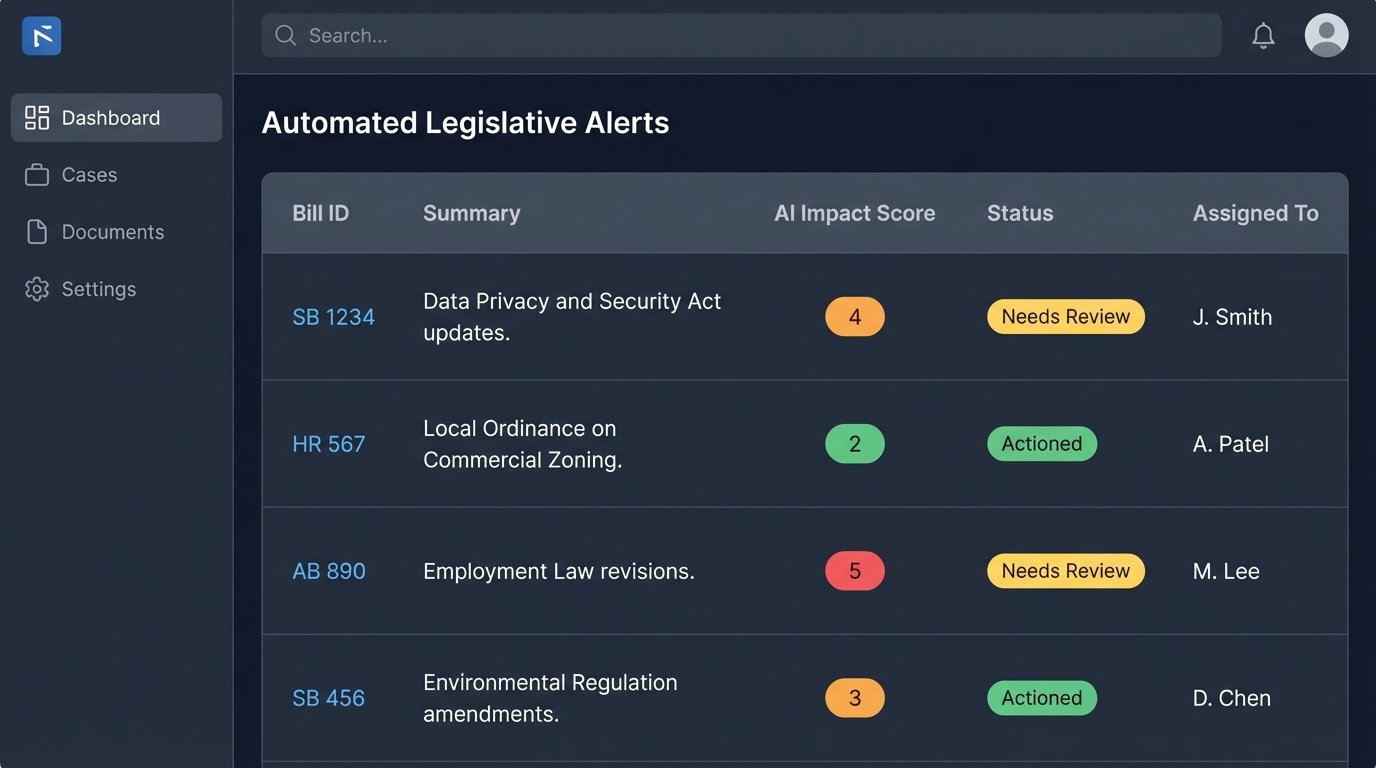
The output of this script is not an email alert. It is a structured JSON object. This data can then be routed based on rules. An `impact_score` of 5 could trigger an immediate Slack message to a specific practice group, while a score of 2 might just be logged in a case management system for weekly review. You are building a system to filter signal from noise, not just another notification pipeline.
AI for Interpretation, Not Just Monitoring
Alerting on changes is only half the problem. The other is interpreting dense, existing regulations. When a client asks how a specific part of the tax code applies to a convoluted transaction, the junior associate spends hours, sometimes days, manually reading and synthesizing the material. We can accelerate this initial research phase with a technique called Retrieval-Augmented Generation (RAG).
A RAG system prevents the LLM from “hallucinating” or making up answers. Instead of asking the model a question from its general knowledge, you force it to construct an answer using only a specific set of documents you provide. Think of it like treating the LLM as a freshly minted law clerk: you give it a specific library stack and a narrow question, you do not ask it to write the final brief from memory.
Building a basic RAG system for a statute involves these steps:
- Document Preparation: Obtain a clean, text-version of the statute or regulation in question (e.g., a specific title of the U.S. Code).
- Chunking: Break the document into small, semantically meaningful chunks. For a statute, splitting by subsection is effective. Each chunk is a self-contained piece of information.
- Vectorization: Use a sentence-transformer model to convert each text chunk into a numerical vector (an embedding). This vector represents the semantic meaning of the text.
- Indexing: Store these vectors and their corresponding text in a vector database. Tools like FAISS or ChromaDB are lightweight and effective for this.
With the index built, you can now query the regulation using natural language.
Querying the RAG System
When a lawyer asks a question, the query process reverses the indexing steps:
- The user’s question (“What are the safe harbor provisions for data breach notifications?”) is converted into a vector.
- The vector database performs a similarity search, finding the text chunks whose vectors are mathematically closest to the question’s vector. These are the most relevant sections of the statute.
- A new prompt is constructed. It includes the original question along with the retrieved text chunks as context.
- This combined prompt is sent to the LLM, with an instruction like: “Answer the following user question based *only* on the provided context.”
The LLM’s response is therefore grounded in the source material you provided. It synthesizes an answer from the relevant statutory text, often citing the specific sections it used. This is not legal advice. It is a high-speed research memo generator that drastically cuts down the time required to find the starting point for a legal analysis.
Validation, Costs, and Other Hard Truths
This technology is not magic. An LLM can misinterpret legal nuance, especially in areas requiring deep subject matter expertise. A RAG system is entirely dependent on the quality of its source documents and the effectiveness of its chunking strategy. The output of these systems should always be treated as a first draft, a tool to accelerate research, not replace a lawyer’s judgment. Every output must be validated by a qualified attorney.
There are also costs to consider. API calls to providers like OpenAI are a direct operational expense that scales with usage. This can become a significant wallet-drainer. Self-hosting open-source models gives you more control and privacy but requires a substantial upfront investment in GPU hardware and the technical skill to maintain it. Sending client-specific fact patterns to a third-party API also raises serious data privacy and confidentiality concerns that must be addressed through your provider’s terms of service or by using on-premise solutions.
The goal is not to build an automated lawyer. The goal is to build a tool that mechanizes the most repetitive, low-value parts of statutory research. It is about augmenting your best attorneys, letting them focus on high-level strategy instead of hunting for keywords in a PDF. Control over your information flow is a competitive advantage, and building your own tools is how you achieve it.