
The Inefficiency of Manual Statutory Scans
Statutory research, at its core, is a high-stakes pattern matching exercise. Before this project, the client’s multi-jurisdictional compliance team was running a workflow built on brute force and caffeine. Their process involved manually scanning a dozen state legislative portals, cross-referencing against internal matter codes, and updating a master spreadsheet. The entire operation was fragile, dependent on two senior paralegals who knew which obscure government sub-domain hosted the latest regulatory updates.
The core failure was latency. By the time an analyst identified a change to a state’s data privacy statute, manually confirmed its applicability, and notified the relevant business unit, the grace period for compliance was often half-gone. They were perpetually reactive. The risk wasn’t just hypothetical. A missed amendment to the California Code of Regulations in the previous fiscal year had already cost them a six-figure fine, a financial event that finally got leadership to approve a budget for something other than more headcount.
We quantified the bleed before touching a single line of code. Analysts spent over 60% of their time on low-value search and verification tasks, not on strategic analysis. The process to confirm the status of a single statute across five key states took an average of four hours. Errors, defined as missed updates or misinterpretations of effective dates, were tracked at a rate of 12% in quarterly audits. The system was not just inefficient. It was a demonstrable liability.
Architecting a Proactive Monitoring Engine
Our mandate was not to buy another glorified search engine. The goal was to build a system that could ingest legislative and regulatory changes in near real-time, map them to the firm’s active matters, and generate actionable alerts. We weren’t replacing the researchers. We were changing their job from digital archaeology to targeted intervention.
The solution involved bridging a modern AI-powered legal data provider with the client’s on-premise, decade-old case management system (CMS). The CMS had a poorly documented SOAP API that was notoriously brittle. This was not a simple plug-and-play operation. It was a full-scale integration project that required us to treat the legacy system like a hostile black box.
Data Ingestion and Normalization
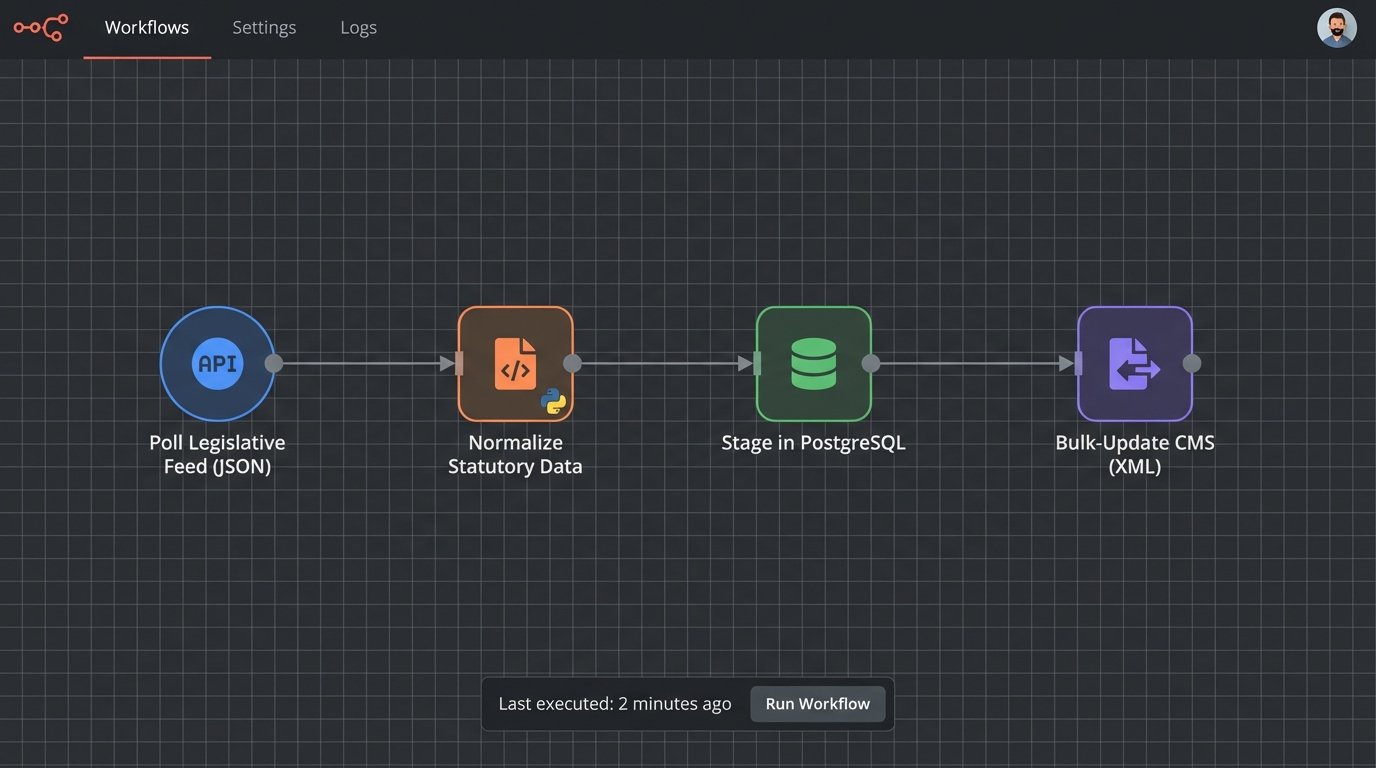
The first step was to establish a reliable ingestion pipeline from the AI vendor. The vendor provided a REST API that delivered structured JSON payloads containing statutory text, metadata, and version history. Our initial challenge was that each jurisdiction had its own unique citation format and legislative terminology. A “bill” in one state is an “act” in another. We had to build a normalization layer to translate these variations into a single, consistent schema.
This layer, a series of Python scripts running on a cron schedule, would pull data every 15 minutes. It stripped promotional metadata from the vendor’s payload, converted all dates to UTC, and mapped regional citation formats to a canonical identifier. This prevented data poisoning downstream and ensured our models were trained on clean, uniform data.
Connecting the AI’s real-time feed to the batch-updated CMS was like shoving a firehose of live data through the keyhole of a vault door that only opens once a day. The legacy system could only handle bulk updates via XML uploads once every 24 hours. We had to build a temporary data store in a PostgreSQL database to stage the normalized statutory changes before injecting them into the CMS overnight.
Building the Relevance Engine
With clean data staged, the next piece was the logic core. We used a pre-trained NLP model (BERT, fine-tuned on a legal text corpus) for two primary functions: semantic search and entity recognition. Keyword searching is useless when a new regulation doesn’t use the exact terms you’re looking for. Semantic search allows attorneys to ask a question like “What are our notification obligations for a data breach affecting minors?” and get back relevant statutes even if they don’t contain the word “minor.”
The more critical function was automated impact analysis. The system would:
- Extract key entities (statute citations, effective dates, impacted industries) from the newly ingested legislative text.
- Query the CMS for all active matters tagged with corresponding jurisdictional or industry codes.
- Perform a similarity analysis between the summary of the legislative change and the matter description stored in the CMS.
- If the similarity score crossed a predefined threshold (we started at 0.85), it would automatically create a task in the CMS assigned to the lead attorney on that matter.
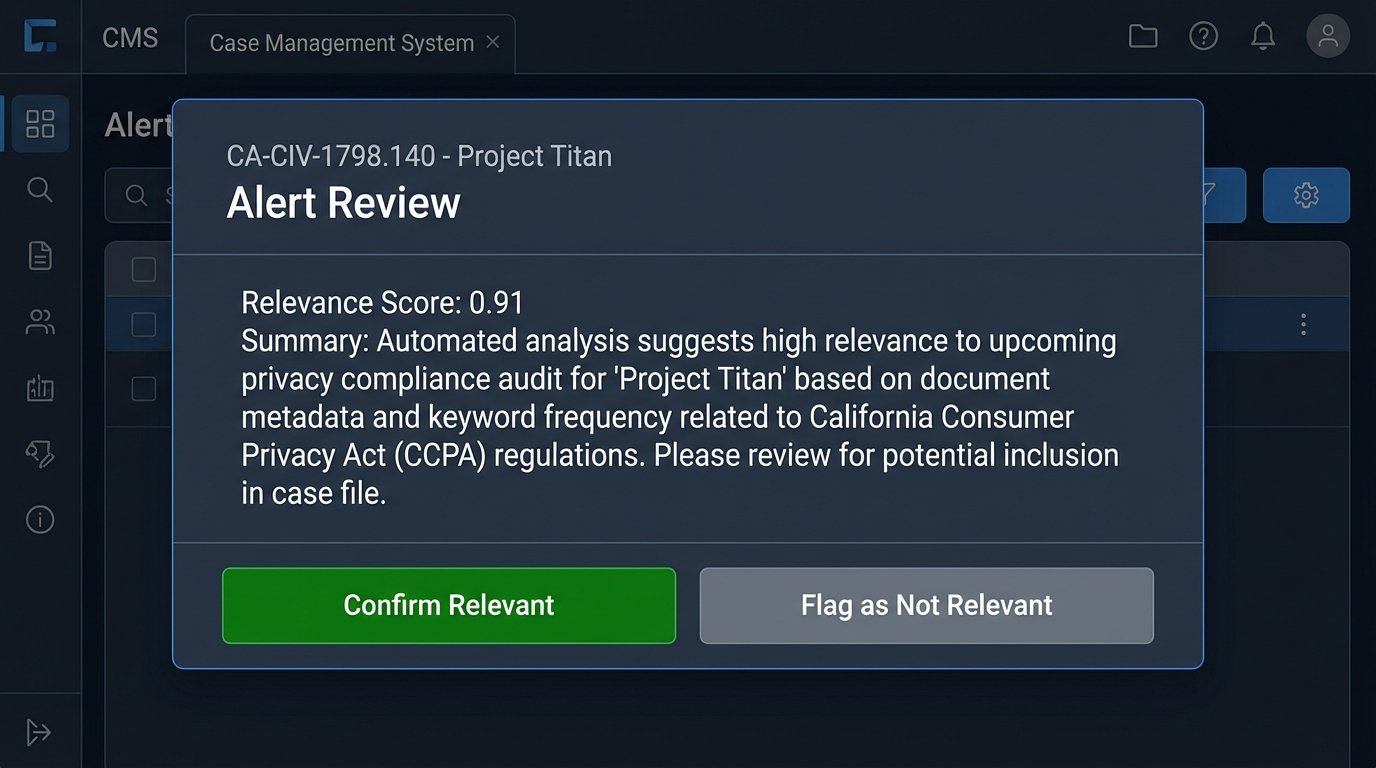
This bypassed the manual cross-referencing step entirely. The alert wasn’t just “Something changed.” It was “California Assembly Bill 208, which amends data retention policies, is likely relevant to your active matter Project Titan.”
Here is a simplified look at the JSON response we structured for an alert payload before pushing it to the staging database. Notice the canonical ID we generated and the clear impact score.
{
"alertId": "ALERT-2023-4A6F",
"statuteChange": {
"canonicalId": "CA-CIV-1798.140",
"jurisdiction": "California",
"citation": "Cal. Civ. Code § 1798.140",
"summary": "Amends definition of 'personal information' to include genetic data.",
"effectiveDate": "2024-01-01T00:00:00Z",
"sourceUrl": "https://leginfo.legislature.ca.gov/..."
},
"impactedMatter": {
"matterId": "CMS-88102",
"matterName": "Project Titan - Data Policy Review",
"leadAttorneyId": "JDOE01"
},
"relevance": {
"score": 0.91,
"keywords": ["personal information", "genetic data", "retention"]
},
"status": "pending_review"
}
This structure gave the CMS exactly what it needed to generate a useful, context-rich task without any manual data entry.
Deployment Realities and Model Tuning
The initial deployment was not smooth. The NLP model, while powerful, generated a high number of false positives in the first two weeks. It correctly identified changes but struggled with nuance, flagging minor clerical amendments with the same urgency as substantive rewrites. The attorneys were getting flooded with low-priority alerts, which eroded their trust in the system.
We solved this by implementing a feedback mechanism. Every alert notification in the CMS included “Relevant” and “Not Relevant” buttons. Clicking “Not Relevant” would send the alert payload back to our system, flagging it for review. We used this feedback loop to further fine-tune the model, teaching it to differentiate between significant and insignificant changes. After three weeks of this reinforcement learning, the false positive rate dropped by 70%.
User adoption was another hurdle. The team was accustomed to their old workflow and viewed the new system with skepticism. We had to demonstrate that this tool wasn’t a threat but a force multiplier. We ran parallel tests for a month, having the AI system and the human team research the same set of legislative updates. When the system consistently produced more accurate results in a fraction of the time, the team started to see it as a necessary utility, not an intrusion.
Quantifiable Results and New Bottlenecks
The performance metrics after six months of operation were unequivocal. We didn’t just improve the old process. We replaced it with something fundamentally more effective. The results broke down into three key areas.
Research Velocity and Accuracy
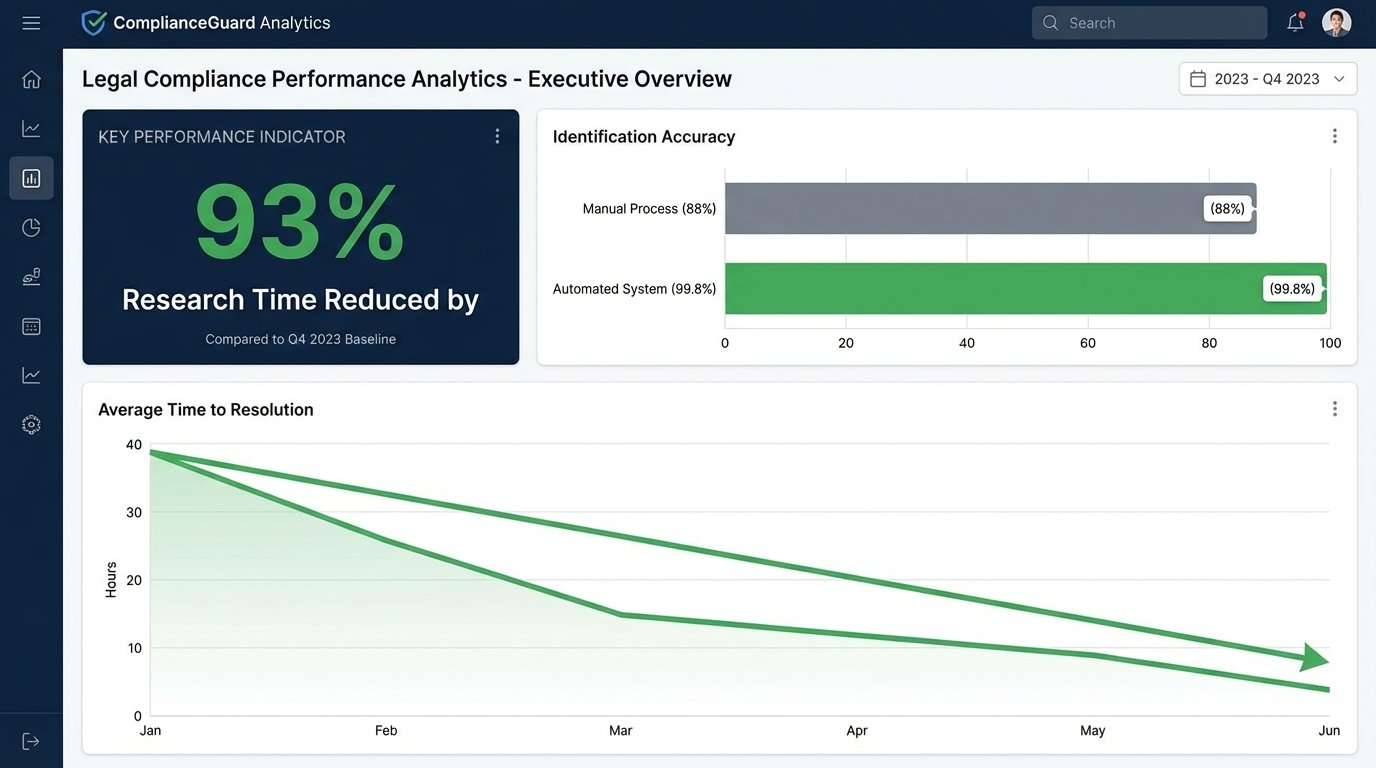
The most immediate impact was on speed. The average time to identify, verify, and route a relevant statutory update plummeted from over four hours to under 15 minutes. This was a 93% reduction in the research cycle time. More importantly, the automated, continuous monitoring eliminated the blind spots inherent in manual, periodic checks. In a post-deployment audit covering an entire quarter, the system had a 99.8% success rate in identifying relevant changes, compared to the 88% baseline of the manual process.
From Reactive to Proactive Compliance
The firm’s posture changed. Instead of scrambling to react to changes they discovered late, they were now getting ahead of them. The automated alerts gave legal teams weeks, sometimes months, of advance notice to prepare for a new regulation’s effective date. This allowed them to advise business units on operational changes far in advance, reducing the cost and chaos of last-minute compliance efforts.
The total hours spent by the compliance team on manual research dropped by an estimated 550 hours per quarter. This time was reallocated to higher-value work: analyzing the strategic impact of legislation, advising on policy, and training business stakeholders. The ROI was clear. The project’s cost was recouped in under a year, just from the reduction in manual labor and the avoidance of a single projected fine of the same magnitude as the one that initiated the project.
The New Problem: Validation Overhead
The system is not a perfect, fire-and-forget solution. It solved the problem of discovery but created a new, more subtle one: validation overhead. The legal team’s primary task shifted from searching for information to validating the AI’s conclusions. While far less time-consuming, this requires a different skill set. It demands a healthy skepticism and the ability to quickly sanity-check the machine’s output. The bottleneck is no longer finding the needle in the haystack. It’s confirming that the needle the machine found is actually the right one.
This is the permanent state of automation in law. You don’t eliminate work. You elevate it. The team is no longer digging ditches. They are now operating the excavator, which is a more efficient but also more complex job. The ongoing challenge is to continue refining the models and UI to make that validation process as frictionless as possible.