
The core rot in most large law firms is not a lack of legal talent. It is operational friction, baked into decades of manual processes and patched-together systems. Our engagement with a Global 100 firm was a classic case. The mandate from management was vague, centered on “digital transformation,” but the symptoms on the ground were specific, measurable, and costing the firm millions in leaked revenue and squandered non-billable hours.
The Diagnosis: Systemic Process Debt
The firm ran on a heavily customized, on-premise practice management system. Its API was poorly documented and access was gated by an overworked internal IT team. The Document Management System (DMS) was a digital filing cabinet, not a knowledge base. Finding a specific clause from a prior deal was an exercise in institutional memory, requiring an associate to ask a senior partner who might remember a similar transaction from five years ago. This is not a scalable model.
We isolated two primary areas bleeding efficiency: Mergers and Acquisitions (M&A) deal closings and firm-wide knowledge management. The two were deeply connected. The manual, chaotic nature of the closing process directly prevented the structured capture of knowledge for future use. Every closed deal was a lost opportunity to make the next one smarter.
M&A Closing Checklists: The Epicenter of Chaos
A typical mid-market M&A deal involved a closing checklist managed in a multi-tabbed Excel spreadsheet. This file, often exceeding 20MB, was the single source of truth. It was emailed back and forth between internal teams and opposing counsel, leading to severe version control issues. Paralegals spent the majority of their time reconciling these different versions instead of performing substantive work.
The workflow for tracking signature pages was entirely manual. A junior associate would maintain a separate tracker, cross-referencing it with the master checklist and a folder of PDF scans on a shared drive. The lead partner on the deal had zero real-time visibility into progress. Their view was filtered through a junior associate who was perpetually behind on updating the status. Deals were delayed by days, not because of legal negotiation, but because a single signature page was missing and nobody knew it until the final hours.
Knowledge Management: A Digital Landfill
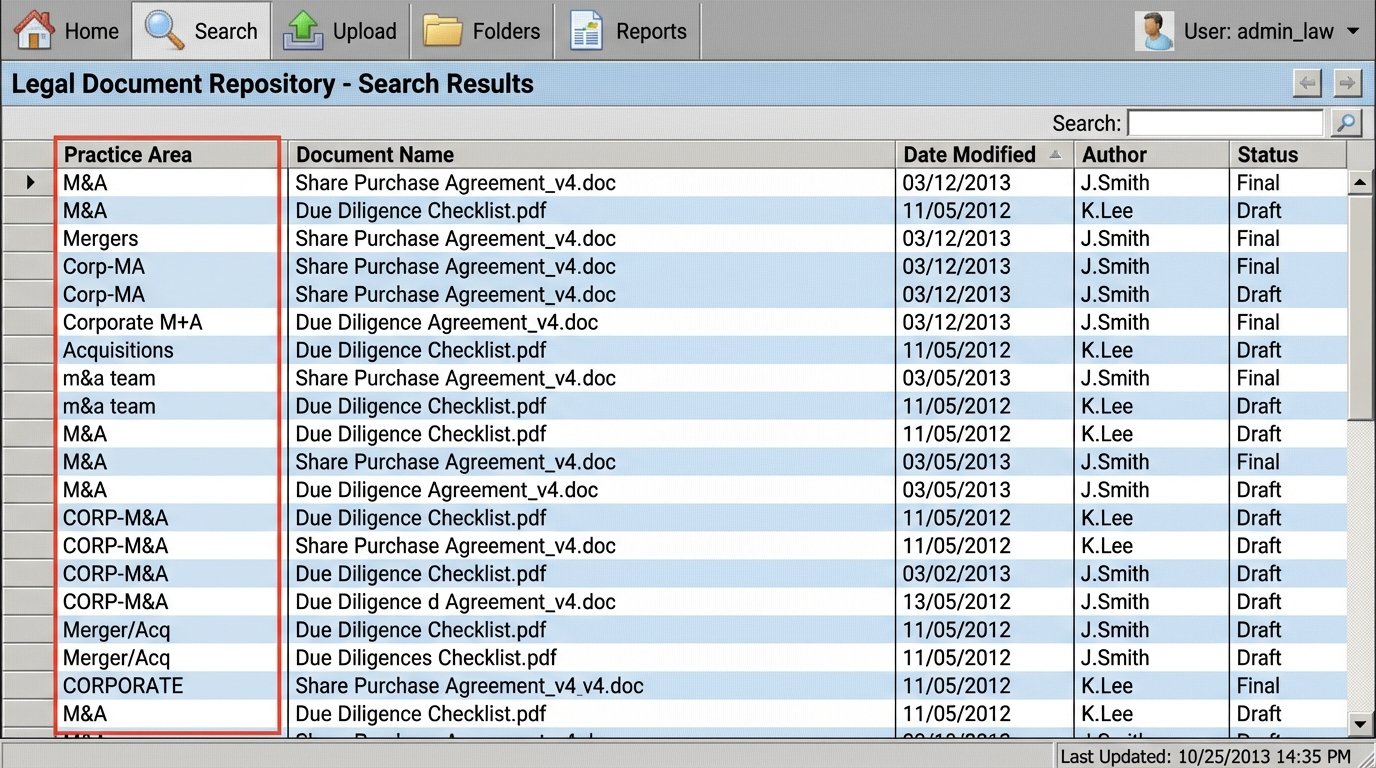
The firm’s DMS contained millions of documents with inconsistent metadata. The “practice area” field was a free-text box, resulting in dozens of variations for the same group (e.g., “M&A,” “Mergers,” “Corp-MA”). Without a rigid taxonomy, searching for precedent was useless. Associates resorted to searching their own sent items or personal network drives, creating information silos and risk.
This forced a reactive approach to drafting. Instead of starting with the firm’s best-in-class examples, associates started from old templates of questionable origin. This introduced errors and inefficiencies, requiring multiple rounds of partner review to fix basic mistakes. The firm’s collective intelligence was effectively locked away, inaccessible at the moment of need.
The Architecture of the Solution
Our objective was not to replace the core PMS or DMS. A rip-and-replace project would have been a multi-year, multi-million dollar wallet-drainer with a high probability of failure. The strategy was to build a lightweight orchestration layer on top of the existing infrastructure, forcing structure onto the chaos. We decided to tackle the M&A process first, as a successful outcome there would produce the structured data needed to solve the KM problem.
Phase 1: The M&A Closing Room Application
We used a low-code application platform to rapidly prototype and deploy a web-based “Closing Room.” This approach bypassed the firm’s internal development queue, which was backlogged for 18 months. The platform provided the UI components, database, and workflow engine, allowing us to focus on the integration logic.
The application’s core function was to digitize the closing checklist. We forced a structured import process using a locked-down Excel template. Once ingested, the checklist became a series of assignable tasks within the web application. Each task was linked to a specific document placeholder.
The critical step was integration. We built two key bridges:
- DMS Integration: Using the iManage REST API, the application could pull document versions directly into the checklist item. An associate could link the “Final Purchase Agreement” task to the correct document ID in the DMS. This eliminated the need to track versions via email attachments.
- E-Signature Integration: We used the DocuSign API to manage the signature process. From the Closing Room, a paralegal could send a document for signature. The API webhook would automatically update the status of the checklist item from “Sent for Signature” to “Executed” upon completion, attaching the certified PDF back to the task.
The user interface was a simple dashboard showing the percentage of tasks completed, items outstanding, and which party was responsible for the next action. Partners could now see the real-time status of a closing from their phone without having to call an associate. This was not about complex technology; it was about injecting data integrity and visibility into a broken process.
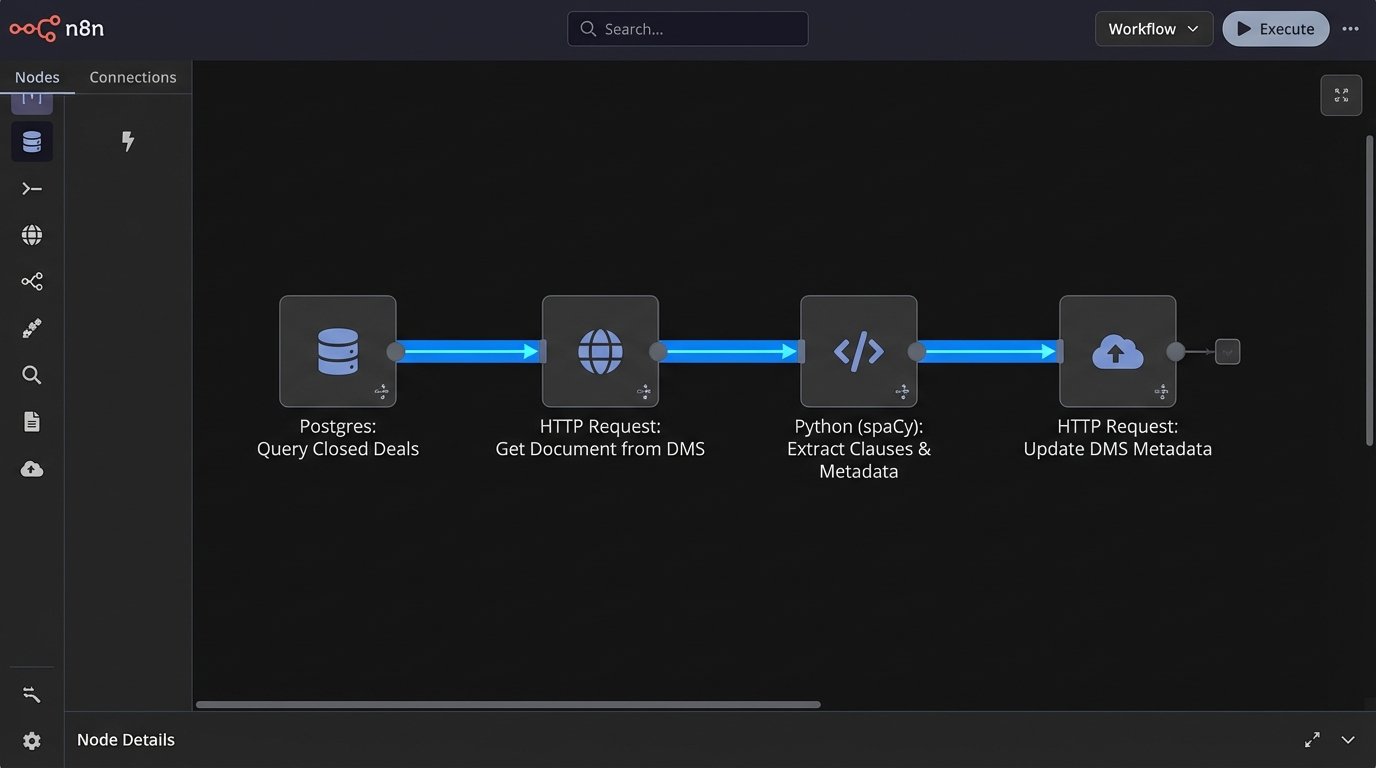
Phase 2: Building the KM Data Pipeline
With the M&A Closing Room generating structured data, we could finally address the KM disaster. Every completed deal in the system represented a perfectly curated set of final, executed documents with clear labels. We built a data pipeline to extract and weaponize this information.
The pipeline was a series of Python scripts running on a schedule. It was not a single, elegant piece of software. It was a gritty, functional chain of processes designed to operate in a hostile data environment.
The process worked like this:
- Extraction: A script queries the Closing Room application’s production database nightly via a read-only replica. It looks for deals marked as “Closed” in the last 24 hours.
- Document Retrieval: For each closed deal, the script gets the list of document IDs from the checklist data and retrieves the final executed versions from the DMS using the API.
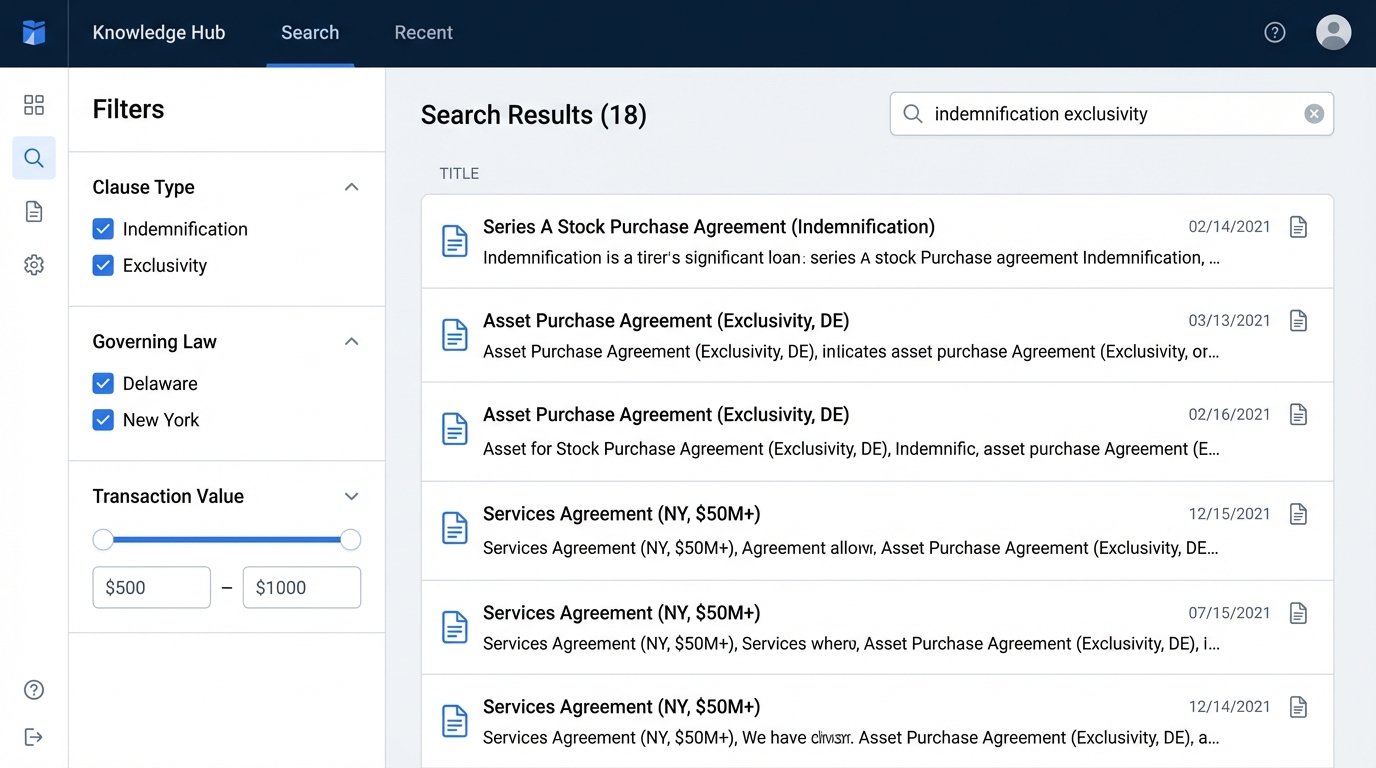
- Data Stripping and Analysis: The script then performs two actions on each document. First, it converts the PDF to plain text. Second, it pushes that text through a natural language processing model we trained using spaCy. The model was trained to identify and tag specific legal clauses (e.g., “Indemnification,” “Governing Law,” “Exclusivity”). The model also extracted key metadata like party names, transaction value, and governing jurisdiction.
- Injection: The final script takes this new, enriched metadata and injects it back into the DMS. It updated the custom metadata fields for the corresponding document, overwriting the inconsistent, human-entered data with clean, machine-generated tags.
This process felt like building a filtration system for a river of mud to get a few ounces of clean water. The NLP model was not perfect, but it was consistent. And consistency is the foundation of any useful search index.
To demonstrate the logic, here is a simplified Python snippet showing how we might update a document’s metadata using a hypothetical DMS API client. This is the final step in the pipeline.
import dms_api_client
from nlp_processor import extract_clauses
# Assume dms_client is an authenticated session
dms_client = dms_api_client.connect(api_key="YOUR_API_KEY")
def update_document_metadata(doc_id):
"""
Fetches a document, processes it, and updates its metadata.
"""
try:
document_text = dms_client.get_document_text(doc_id)
if not document_text:
print(f"Failed to retrieve text for doc_id: {doc_id}")
return
# nlp_processor returns a dictionary of extracted metadata
metadata = extract_clauses(document_text)
# Map NLP output to the DMS's custom metadata fields
update_payload = {
"custom_field_101": metadata.get("governing_law"),
"custom_field_102": metadata.get("indemnity_cap"),
"is_precedent": True,
"clauses_detected": ", ".join(metadata.get("clauses", []))
}
# The API call that injects the structured data
response = dms_client.update_metadata(doc_id, update_payload)
if response.status_code == 200:
print(f"Successfully updated metadata for doc_id: {doc_id}")
else:
print(f"Error updating doc_id {doc_id}: {response.text}")
except Exception as e:
print(f"A critical error occurred processing doc_id {doc_id}: {e}")
# Example usage:
# new_document_ids = [1138, 1139, 1140]
# for doc_id in new_document_ids:
# update_document_metadata(doc_id)
This code represents the final, critical injection step. The real work was in the error handling and the logic within the `extract_clauses` function, which was the result of weeks of training and refinement. The vendor’s API documentation was a work of pure fiction, so half the battle was reverse-engineering the required payload structure through trial and error.
Quantifiable Results and Operational Costs
The project was evaluated on hard metrics, not platitudes. We tracked key performance indicators before and after implementation for a six-month pilot period involving the firm’s core M&A group.
M&A Group Performance
The impact on the deal closing process was immediate.
- Reduction in Administrative Drag: We measured the average non-billable time spent by paralegals and junior associates on checklist management and signature tracking. This dropped from an average of 110 hours per deal to just under 30 hours. This was a 72% reduction in low-value administrative work.
- Accelerated Closing Velocity: The average time-to-close for deals under $250M decreased by 22%. By eliminating the administrative friction and providing partners with real-time visibility, we removed artificial delays from the timeline. The firm could recognize revenue faster.
The primary cost was adoption. Getting partners to abandon a 20-year-old workflow required more social engineering than software engineering. The system was only as good as the data within it, and bypassing it for the “old way” was a constant threat during the first few months.
Firm-Wide Knowledge Access
The results of the KM pipeline took longer to materialize but were more profound.
- Search Time Reduction: We surveyed associates on time spent searching for precedents. The self-reported average was 6 hours per week before the project. Six months after the pipeline was operational for the M&A document set, that average dropped to less than one hour per week.
- Quality of Drafts: Partners reported a noticeable improvement in the quality of initial drafts from junior associates. By providing easy access to high-quality, relevant precedents, we reduced the number of unforced errors and review cycles.
The sacrifice here is precision. The NLP model has an accuracy of about 85%. It occasionally misidentifies a clause or fails to tag a key term. This is not a perfect system. It is a statistical improvement over chaos, requiring a dedicated KM attorney to periodically review and correct the machine-generated tags. It is a system that needs active gardening.
The total cost of software licensing and our implementation fees was recovered within 14 months, based solely on the value of the recovered billable hours in the M&A group. The firm now owns a scalable architecture that can be extended to other practice areas like finance and real estate, replicating the model to transform their other digital landfills into structured, searchable knowledge assets.