
A 1000-lawyer AmLaw 50 firm ran its M&A practice on the back of junior associates, black-marker pens, and thousands of printed PDFs. Their due diligence process for a private equity client’s target acquisition was a case study in controlled chaos. The entire workflow hinged on a team of ten associates manually reviewing a virtual data room containing upwards of 20,000 documents, armed only with an Excel checklist. This was not analysis. It was a high-stakes, manual search operation.
The consequences were predictable. A standard first-pass review consumed over 200 billable hours and stretched across four weeks. Key clauses were missed due to human fatigue, requiring expensive rework or, worse, client-facing apologies. The data extracted was dumped into a sprawling spreadsheet that was impossible to query or reuse for future deals. The entire knowledge base was ephemeral, existing only in that one Excel file, destined for a document management system archive.
Our firm’s leadership saw the bleeding but resisted the obvious cure. The partners’ primary objection was a classic one, rooted in the billable hour. Why automate a 200-hour process when you can bill for 200 hours of associate time? The argument was fundamentally flawed. Clients were pushing back on costs, demanding fixed fees, and becoming less tolerant of delays. The real mandate was not to eliminate billable work but to shift it from low-value document hunting to high-value risk analysis and strategic advice.
Phase One: A Low-Risk Trojan Horse
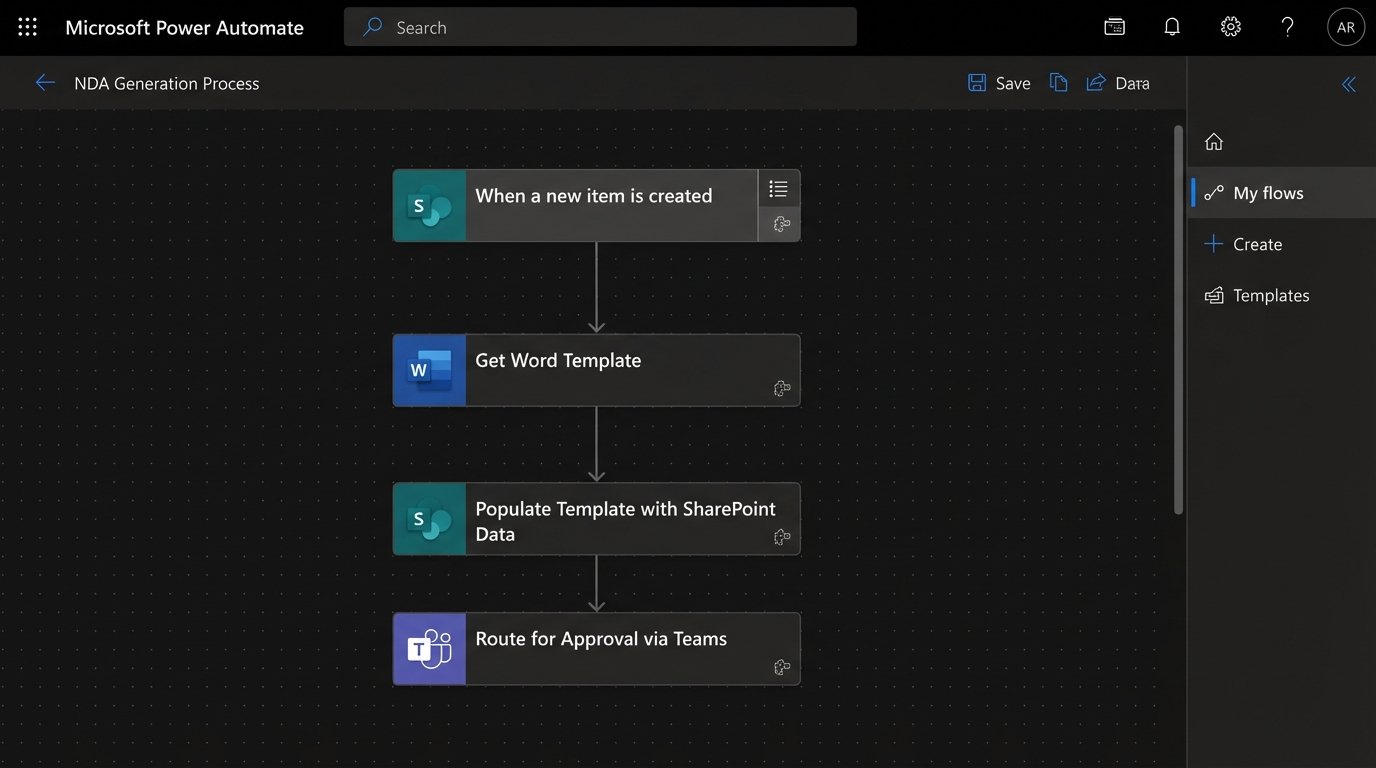
To get buy-in, we had to demonstrate value without touching a core M&A workflow. We targeted the Non-Disclosure Agreement. NDAs are high-volume, low-complexity, and a constant source of friction for every practice group. The existing process involved a paralegal finding the last-used template, manually updating party names and dates, and routing it through three different email inboxes for approval. It was a 45-minute task, repeated dozens of times a day.
We bypassed the firm’s sluggish document management system entirely for this pilot. We built a simple intake form using Microsoft Forms, which fed requests into a SharePoint list. This triggered a Power Automate flow that performed the logical heavy lifting. The flow would select the correct template based on jurisdiction, determine if reciprocal clauses were needed, and then call a document generation API to inject the correct entity names, effective dates, and governing law clauses directly into a Word document. The final document was then routed for review.
The entire Rube Goldberg machine cost less than a partner’s monthly expense account to build. It reduced the NDA generation cycle from 45 minutes of manual labor to under two minutes of automated execution. This was the political victory we needed. It proved automation could deliver immediate, tangible results without threatening the core business model. It was fast, cheap, and it worked.
Phase Two: Gutting the Due Diligence Process
With the NDA success providing air cover, we moved on to the main target: M&A due diligence. This was not about simple document generation. It was about deconstructing a complex analytical workflow and rebuilding it with a scalable, machine-driven core. The goal was to build an engine that could ingest, process, and analyze tens of thousands of documents, surfacing only the critical information for human review.
The process was broken into three distinct stages: ingestion, analysis, and presentation.
Ingestion and Data Stripping
First, we had to get the documents out of the client’s virtual data room. This was the initial bottleneck. VDRs like Intralinks and Datasite have APIs, but they are often poorly documented and throttled. We wrote a series of Python scripts using libraries like `requests` and `BeautifulSoup` to authenticate and recursively crawl the VDR folder structure, pulling down every file. It was a brittle solution that required constant maintenance as VDRs updated their front-end code, but a bulk manual download was not a viable alternative.
Once downloaded, the files, a mix of native PDFs, scanned documents, and Word files, were fed into a processing pipeline. We used AWS Textract to perform Optical Character Recognition on scanned images, converting them into machine-readable text. The output was often messy, riddled with OCR errors from skewed scans or low-quality originals. This forced us to build a pre-processing and post-processing clean-up layer to normalize text, remove artifacts, and standardize formatting before any analysis could begin. Trying to run analysis on raw OCR output is like trying to build a foundation on mud.
The NLP Analysis Core
The clean text for each document was then pushed into our analysis engine. We used a hybrid approach. First, a document classification model sorted files into categories like “Lease Agreement,” “Employment Contract,” or “Master Services Agreement.” This gave us an immediate high-level view of the data room’s composition.
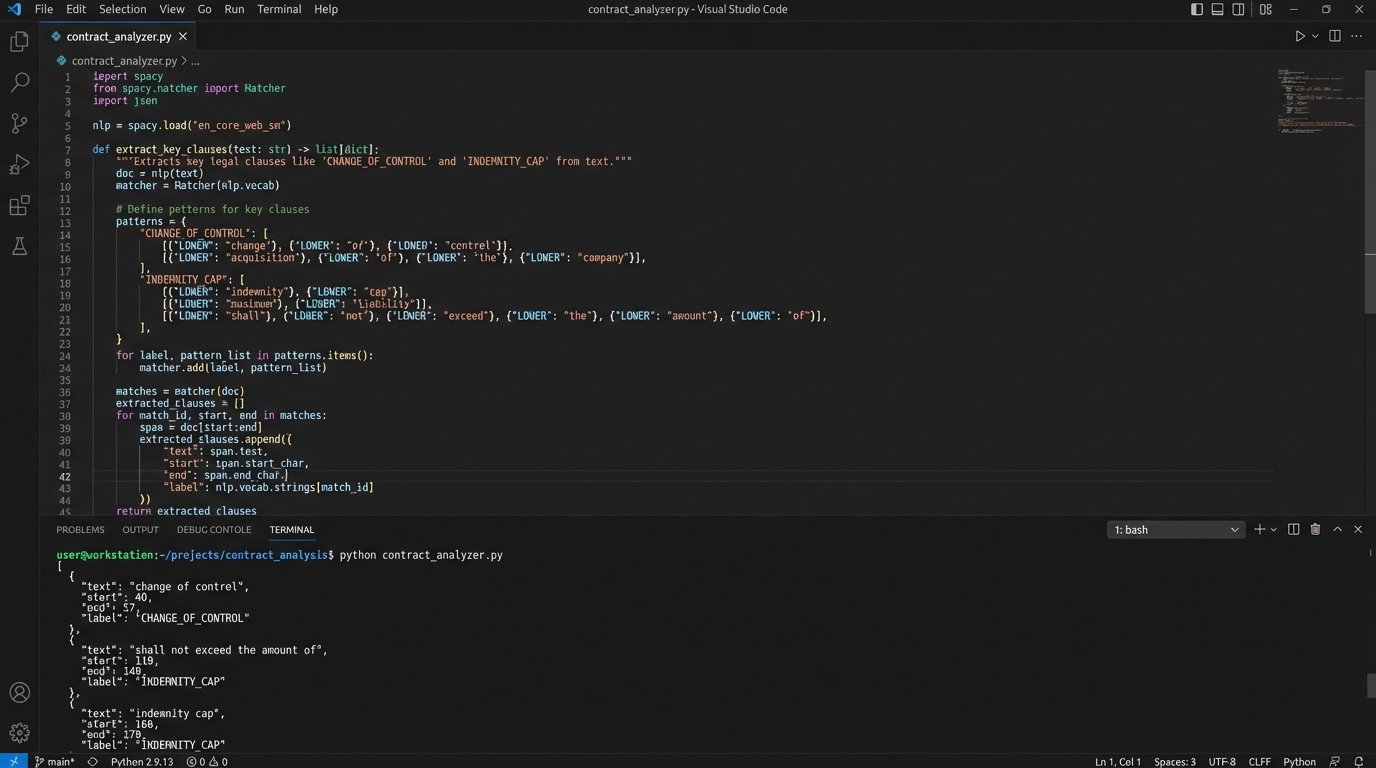
The real work was in clause extraction. For this, we had to train a custom Named Entity Recognition (NER) model. We used the spaCy framework. General-purpose legal models could find basic entities like “Governing Law” or “Termination,” but we needed to identify highly specific and nuanced clauses critical to M&A, such as “Change of Control,” “Assignment upon Merger,” and “Indemnification Caps.” This required creating our own training data. We enlisted a team of five associates for two weeks to do nothing but highlight these specific clauses in a sample set of 2,000 documents. It was a soul-crushing, manual task, but it was the only way to generate the high-quality labeled data the model needed to learn.
This is what the core logic looks like conceptually after the model is trained. It’s a function that takes raw document text and spits out structured data.
import spacy
# Load the custom-trained NER model from disk
nlp_model = spacy.load("./models/merger_agreement_v1")
def extract_key_clauses(document_text: str) -> list[dict]:
"""
Processes document text with the custom NER model
and extracts specific legal clauses.
"""
processed_doc = nlp_model(document_text)
clauses = []
# The model identifies spans of text as entities (our clauses)
for entity in processed_doc.ents:
if entity.label_ in ["CHANGE_OF_CONTROL", "INDEMNITY_CAP", "ASSIGNMENT"]:
clauses.append({
"clause_type": entity.label_,
"text": entity.text,
"start_char": entity.start_char,
"end_char": entity.end_char
})
return clauses
# Example Usage:
# sample_text = "..." # Text from a supply agreement
# extracted_data = extract_key_clauses(sample_text)
# print(extracted_data)
This function became the heart of the engine. Every document passed through it. The output was not just a pile of text, but structured, queryable data: a list of every single Change of Control clause across the entire data room, linked back to its source document and page number.
Integration with Legacy Systems
An isolated analysis engine is a science project. To be useful, it had to inject its findings back into the firm’s existing systems of record. This meant bridging our modern Python-based application with the firm’s ten-year-old iManage DMS and its even older Elite 3E practice management system. This was the least glamorous but most critical part of the project.
We wrote a custom connector for the iManage COM API to file the final diligence reports and summary spreadsheets into the correct client matter workspace. The API was slow and its documentation was a collection of half-truths, requiring weeks of reverse-engineering and trial-and-error. For the practice management system, we bypassed its non-existent API and wrote scripts to generate formatted flat files for a nightly bulk-upload process. It was ugly, but it worked. This step ensured the intelligence we generated was captured permanently, not lost in an engineer’s database.
Building this bridge was like shoving a firehose through a needle. The new system could generate data at an incredible rate, but the legacy systems could only absorb it slowly and through very specific, rigid channels. Managing this impedance mismatch became a core operational task.
Quantifiable Results and Lingering Problems
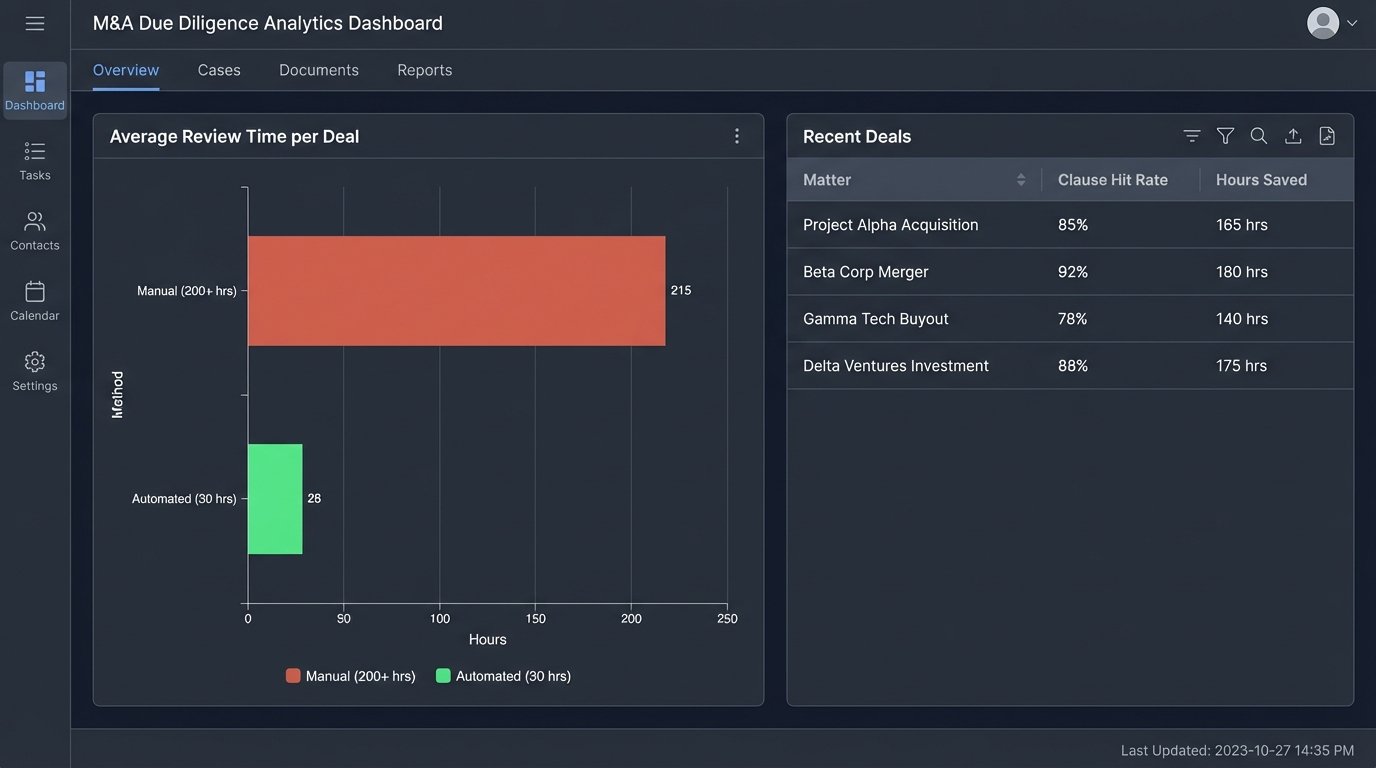
The impact was immediate and stark. The average time for a first-pass due diligence review on a typical M&A deal plummeted from over 200 hours to just 30. Associates no longer spent weeks searching for clauses. Instead, they spent their time analyzing the clauses the system had already found, assessing their impact, and advising the client on the identified risks. Their role shifted from search to synthesis.
Accuracy improved dramatically. The system found every instance of a “Change of Control” clause, while manual reviews typically had a miss rate of 5-10% due to human error and fatigue. The firm could now offer fixed-fee diligence services at a price point its competitors, still reliant on manual labor, could not match. It created a durable competitive advantage built on technical execution.
The victory was not absolute. The system is a resource drainer, requiring constant care and feeding. The custom NER models suffer from “model drift.” As contract language evolves, the model’s accuracy degrades. We have to retrain it on new documents every six months, a process that requires more tedious annotation work from associates. The brittle VDR scraping scripts break whenever a provider changes its website layout, triggering frantic, late-night fixes.
Adoption also remains a challenge. A vocal minority of senior partners still distrust the output and insist on a parallel manual review, effectively negating the efficiency gains for their matters. The automation is not a magic black box. It is a complex piece of machinery that requires skilled operators, constant maintenance, and a firm-wide willingness to abandon old habits. The war is won, but small battles continue every day.