
A global firm’s M&A practice was running on fumes and junior associate burnout. Their due diligence process for a typical mid-market deal involved throwing a dozen associates into a virtual data room (VDR) for two weeks straight. They would manually open, read, and tag thousands of PDFs, searching for poison pills, change of control clauses, and other specific liabilities. The process was a cost center, consistently blowing past fixed-fee budgets and generating error rates that kept partners awake at night.
The firm was not just losing money. It was losing talent. The monotonous, high-pressure work was a primary driver of first and second-year associate attrition. Client satisfaction was also eroding, as turnaround times were dictated by brute-force manpower, not efficiency. They had a systemic failure masked by a large headcount.
The Anatomy of the Bottleneck
The core problem was the complete lack of structured data. A VDR is little more than a glorified, and often poorly organized, file share. Associates were tasked with imposing a logical framework onto a chaotic dump of contracts, board minutes, and financial statements. Each document was an island, and the connections between them were only made inside an associate’s head, assuming they were not on their fourth coffee at 2 AM.
This manual review process had three distinct failure points. First was speed. An associate, on a good day, might get through 40 to 50 complex agreements. A data room with 5,000 documents required a small army and a significant time block. Second was consistency. The interpretation of a non-standard assignment clause could vary dramatically between Associate A and Associate B, leading to an inconsistent risk profile. Third was cost. At an average blended rate, the billable hours for a single due diligence review could easily climb into the six-figure range, an amount impossible to justify under fixed-fee arrangements.
The data itself was a mess. We saw everything from crisp, text-searchable PDFs to sideways scans of faxed documents from the 1990s. The VDR providers offered APIs that were, to be charitable, unreliable. Documentation was frequently outdated, and rate limits were punishingly low, making bulk extraction a slow, painful exercise that often timed out.
Forcing Structure onto Chaos: The Architecture
We did not set out to build a magical AI lawyer. The goal was to construct a pipeline that would ingest raw documents, strip out key data points, and present them to a human lawyer for validation. The objective was augmentation, not replacement. We aimed to get the first 80% of the rote review done by the machine, freeing up the legal experts to focus on the critical 20% that required actual judgment.
Ingestion and Normalization
The first step was getting the documents out of the VDRs. After several failed attempts to build a reliable process around the provider’s flaky APIs, we opted for a more direct approach. We built a headless browser automation script using Playwright. The script would log into the VDR with service account credentials, navigate the folder structure, and systematically download the entire document set to a secure staging server. It was a brute-force solution, but it was dependable.
Once staged, the pipeline began. A worker process would pick up each new file. If it was a native PDF, the text was extracted directly. If it was an image-based PDF or a TIFF file, it was routed through AWS Textract for OCR. The quality of the OCR output was a constant battle, especially with older, low-resolution scans. We had to build a post-processing layer to correct common OCR errors, like mistaking ‘l’ for ‘1’ or misinterpreting table layouts.
This entire front-end process was about shoveling a firehose of unstructured PDFs through the needle-eye of a structured database schema. It was messy work that required constant monitoring and tuning.
The Extraction Engine: NLP and Rule-Based Logic
With clean text extracted, the real analysis could begin. We used a hybrid approach. An NLP model handled the initial discovery, and a deterministic rules engine handled the validation. Relying on NLP alone is a recipe for disaster. A model might identify a “change of control” clause with 95% confidence, but legal work requires 100% certainty on key risk factors.
We started with a pre-trained transformer model and fine-tuned it on tens of thousands of the firm’s historical contracts, which had already been manually reviewed and annotated. This taught the model the firm’s specific language and clause variations. The model’s job was not to make a decision, but to locate and classify potential clauses of interest: termination, assignment, indemnification, governing law, and about 50 other types.
The NLP output was then passed to a rules engine. This is where the partners’ knowledge was encoded. For example, a rule might state: IF the NLP model flags a “Change of Control” clause, THEN search the text of that clause for the keywords “consent,” “notice,” or “termination.” IF one of those keywords is present, THEN escalate the flag to “High Priority.” This two-layer system gave us the discovery power of machine learning and the precision of programmatic logic.
Here is a simplified Python example using spaCy’s PhraseMatcher to demonstrate a basic rule for finding an assignment clause that requires consent. This is a toy example, but it illustrates the principle of combining pattern matching with dependency parsing to validate a finding.
import spacy
from spacy.matcher import PhraseMatcher
nlp = spacy.load("en_core_web_sm")
matcher = PhraseMatcher(nlp.vocab, attr="LOWER")
# Define the keyword patterns we're looking for
assignment_terms = ["assign its rights", "transfer its rights", "assignment of this agreement"]
consent_terms = ["prior written consent", "without the consent", "requires consent"]
# Add patterns to the matcher
matcher.add("ASSIGNMENT_CLAUSE", [nlp(text) for text in assignment_terms])
matcher.add("CONSENT_REQUIRED", [nlp(text) for text in consent_terms])
# Process a sample document text
doc_text = """
... any provision hereof, Party A shall not assign its rights or obligations under
this Agreement to any third party without the prior written consent of Party B.
"""
doc = nlp(doc_text)
# Find matches in the document
matches = matcher(doc)
# Logic to check if an assignment clause requires consent
assignment_found = False
consent_found_in_sentence = False
for match_id, start, end in matches:
rule_id = nlp.vocab.strings[match_id]
if rule_id == "ASSIGNMENT_CLAUSE":
assignment_found = True
span = doc[start:end]
# Check if the sentence containing the assignment clause also contains a consent term
for consent_match_id, consent_start, consent_end in matches:
consent_rule_id = nlp.vocab.strings[consent_match_id]
if consent_rule_id == "CONSENT_REQUIRED" and span.sent == doc[consent_start:consent_end].sent:
consent_found_in_sentence = True
break
if assignment_found and consent_found_in_sentence:
break
if assignment_found and consent_found_in_sentence:
print("Result: Found Assignment Clause requiring consent.")
else:
print("Result: No consent requirement found in assignment context.")
Integration and the Human-in-the-Loop
The results of the pipeline were not dumped into a spreadsheet. They were injected directly into the firm’s existing matter management system via its REST API. For each document processed, the system would create a record containing:
- A link to the original document.
- The extracted, plain-text version.
- A JSON object of all flagged clauses, including the clause text, classification, risk level, and the rule that triggered the flag.
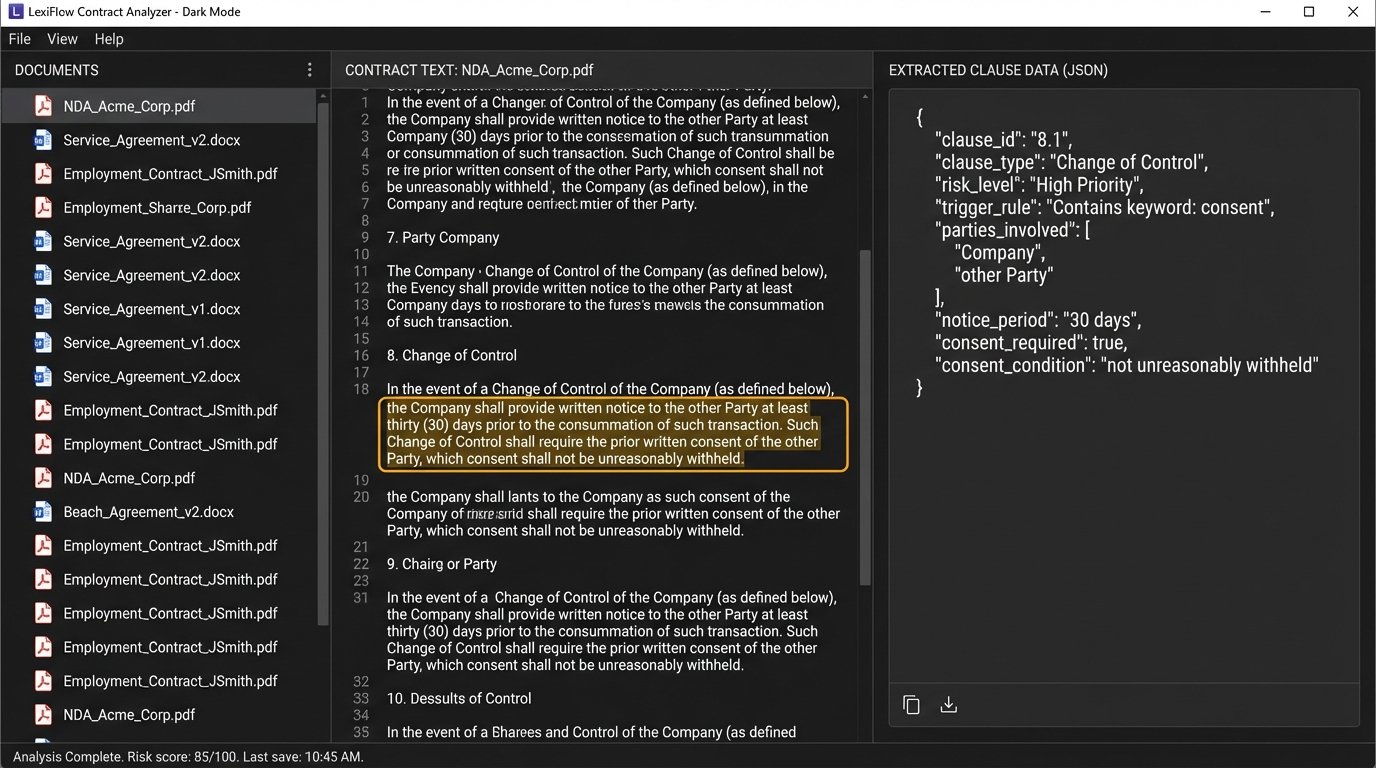
Lawyers then accessed this information through a custom review interface built into their familiar environment. Instead of opening thousands of PDFs, an associate would see a dashboard summarizing the entire data room. They could filter for all “High Priority” change of control clauses or search for any contract that lacked an indemnification clause. A click would show them the extracted clause, highlighted within the context of the full document. The task shifted from finding the needle in the haystack to simply confirming that the needles the system found were, in fact, needles.
Quantifiable Impact: Moving Beyond Billable Hours
The results were immediate and stark. We tracked metrics for a year, comparing a dozen deals done the old way against a dozen done with the automation pipeline. The numbers removed all doubt about the project’s value.
First-Pass Review: From Weeks to Hours
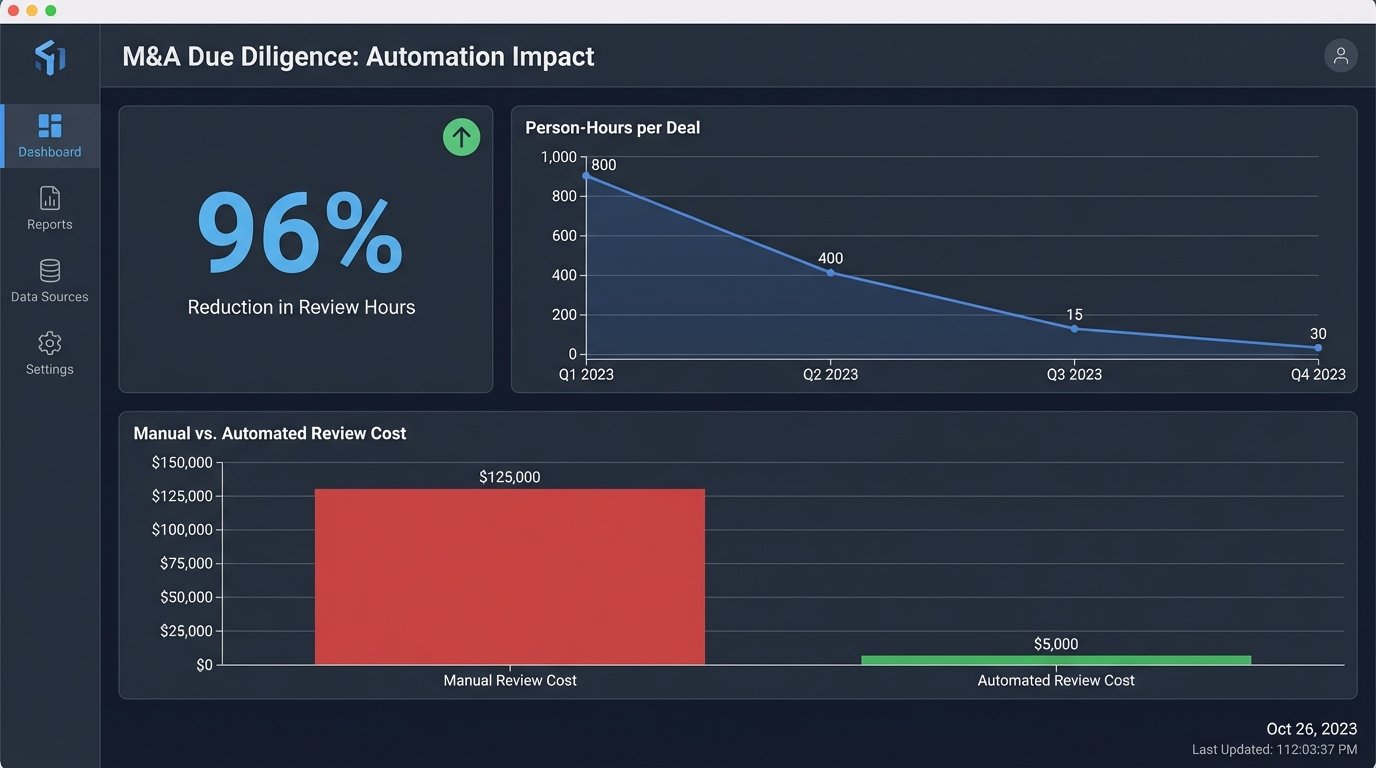
The most dramatic change was in speed. A first-pass review of a 5,000-document data room, which previously took a team of ten associates two full weeks (approximately 800 person-hours), could now be completed by the automation pipeline in about four hours of processing time. The subsequent human validation and analysis, performed by just two senior associates, took an additional two days (32 person-hours). This represented a 96% reduction in person-hours for the initial review phase.
Cost and Accuracy
The cost savings were directly tied to the reduction in hours. The firm was able to handle the same volume of M&A due diligence with a fraction of the staff, allowing them to re-task associates to more complex, higher-value work. They turned a loss-leading, fixed-fee service into a profitable one. Critically, accuracy improved. By automating the initial detection, the system eliminated the “human error” factor of a tired associate missing a key phrase on page 73 of a document. We tracked a 15% reduction in “missed flags” when compared to post-deal analysis of manually reviewed projects.
The Unintended Consequence: A New Data Asset
An outcome the firm did not anticipate was the creation of a massive, structured database of contract intelligence. For the first time, they could run analytics across their entire deal history. Partners could ask questions like, “What is the market standard liability cap for SaaS companies in the EU right now?” or “Show me all the governing law clauses from deals we did in Singapore last year.” The data that was once locked away in thousands of individual PDFs was now a strategic asset for advising clients and winning new business.
The Sobering Reality of Implementation
This was not a plug-and-play solution. The project took nine months and a significant capital investment. The first three months were spent on the grueling task of cleaning and preparing the historical contract data needed to train the NLP model. There were intense political battles to get partner-level buy-in and to convince senior associates to trust the system’s output.
The system is not perfect. It still requires constant maintenance. The VDR automation script breaks whenever a provider changes its UI. The NLP model needs to be periodically retrained with new data to avoid model drift. It was a hard-fought success, built on a foundation of realistic expectations and a willingness to solve messy, real-world problems with pragmatic, robust engineering.