
Calculating the return on investment for any large scale automation project is usually an exercise in creative accounting. A managing partner wants to see a hard number, a dollar figure that justifies a seven-figure spend on software and implementation. The real metrics, however, are found in the operational friction you eliminate and the second-order effects of that removal. This was the case with a 2000-attorney litigation practice drowning in its own e-discovery intake process.
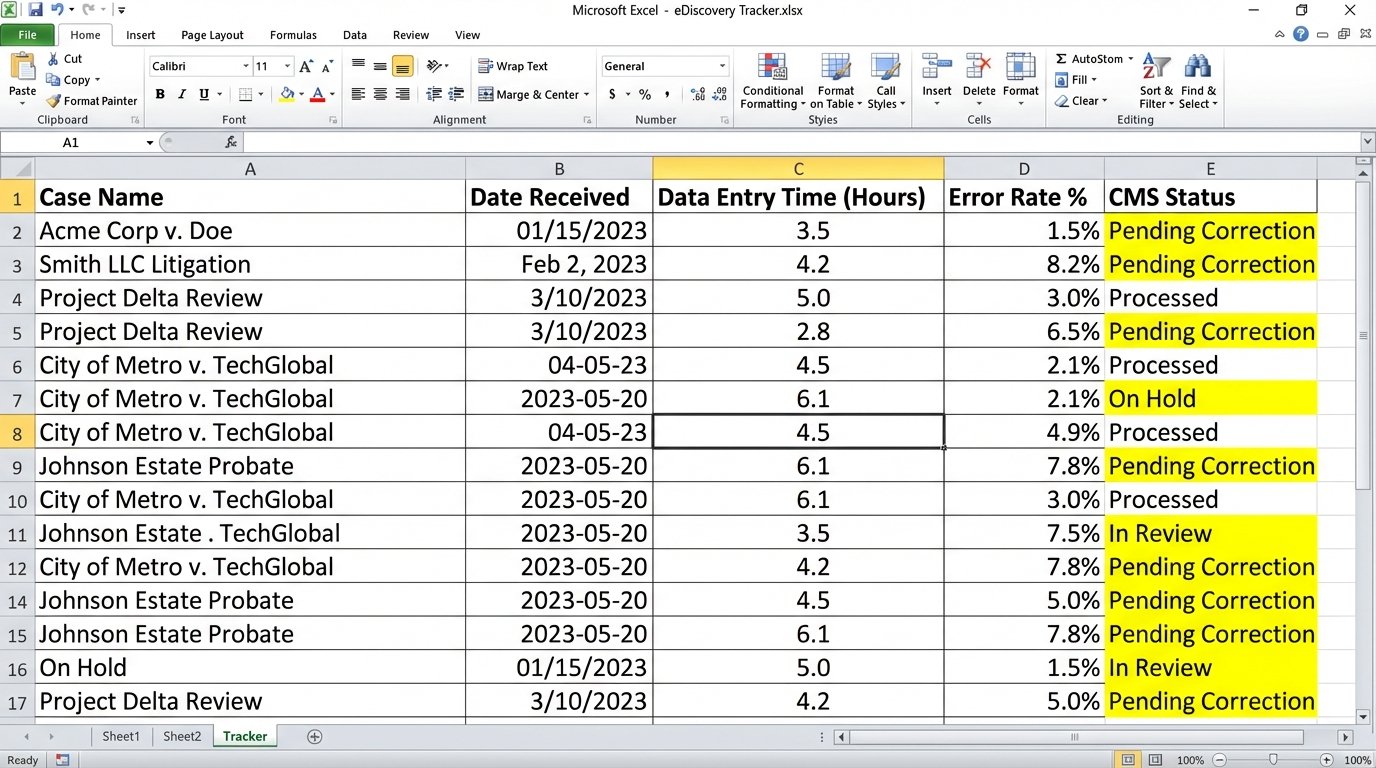
The firm’s process was a textbook example of manual decay. A new discovery request arrived via email as a PDF. A paralegal would print it, manually key over 50 fields into a spreadsheet, and then re-key that same data into the firm’s ancient case management system. The CMS API was so poorly documented that direct integration was considered a high-risk project. The entire workflow, from email receipt to matter activation, took an average of four business hours and involved two separate human handoffs. At the scale of hundreds of new matters a month, the firm was burning millions on non-billable, error-prone administrative labor.
The Anatomy of the Failure
Before any solution could be designed, we had to quantify the existing failure points. We logged every step of the process for a month. The data was not surprising, but it was stark. We tracked time, error rates, and correction loops. The average paralegal spent nearly 25% of their week on administrative tasks directly tied to this broken intake workflow. These were not junior assistants but experienced paralegals whose time was better spent on substantive, billable work.
The core problems were systemic:
- Data Redundancy. Information was entered three times: once on paper notes, once in the tracking spreadsheet, and once into the CMS. Each entry point was a potential point of failure.
- High Error Rate. The manual data entry error rate, including typos and transpositions, was a staggering 8%. Correcting these errors required a senior paralegal to track down the source documents and reconcile the CMS record, consuming more time.
- Lack of Visibility. Partners had no real-time view of the intake pipeline. Status updates were delivered via email chains, which were frequently out of date. This created delays and frustrated both internal teams and clients.
This wasn’t just inefficient. It was a financial drain. The cost of non-billable time, error correction, and write-offs from client disputes over billing mistakes was directly traceable to this single, broken process.
The total cost was not just the sum of wasted hours. It was the opportunity cost of what those paralegals could have been doing. It was the reputational risk of telling a major client their matter was delayed because of a data entry backlog. The initial project proposal focused on this financial bleed as the primary justification for the required budget.
Building an Abstraction Layer, Not a Replacement
The first instinct in these situations is often to demand a full rip-and-replace of the legacy CMS. This is a wallet-drainer of a project that can take years and often fails. A smarter approach is to isolate the legacy system and build a modern service layer around it. We decided to gut the manual process and replace it with a centralized automation engine that would force data into the CMS through a controlled, validated pathway.
The architecture consisted of three main components:
1. The Ingestion & Parsing Service: We configured a dedicated Microsoft 365 mailbox to receive all incoming discovery requests. A Power Automate flow was triggered on each new email, which grabbed the PDF attachment and passed it to a Python script running in an Azure Function. The script used the `PyMuPDF` library to extract raw text and a series of regular expressions to identify and strip key data points like case names, jurisdictions, and opposing counsel.
This is where the initial heavy lifting happens. Getting the regex right for dozens of different PDF formats from various courts and clients was 90% of the battle.
import fitz # PyMuPDF
import re
def extract_case_details(pdf_path):
doc = fitz.open(pdf_path)
text = ""
for page in doc:
text += page.get_text()
case_number_pattern = re.compile(r'Case No\.\s*([\w\-]+)')
plaintiff_pattern = re.compile(r'Plaintiff:?\s*(.*)')
defendant_pattern = re.compile(r'Defendant:?\s*(.*)')
details = {
"case_number": case_number_pattern.search(text).group(1) if case_number_pattern.search(text) else None,
"plaintiff": plaintiff_pattern.search(text).group(1).strip() if plaintiff_pattern.search(text) else None,
"defendant": defendant_pattern.search(text).group(1).strip() if defendant_pattern.search(text) else None
}
# Basic validation logic would go here
if not all(details.values()):
raise ValueError("Failed to parse critical case details.")
return details
The output was a clean JSON object. This structured data is the fuel for the rest of the automation. If the parser failed to achieve a confidence score above 95%, the entire process was flagged for human review.
2. The Orchestration and Validation Engine: The JSON object was then pushed to a workflow automation platform. We used a legal-specific tool, but this could have been done with any modern orchestrator. This engine served as the central brain. It performed business logic checks, such as cross-referencing the client name against the firm’s primary database to fetch the correct client ID. It also managed the approval process, routing the parsed data to a supervising attorney for a one-click confirmation via a simple web form.
Trying to shove the raw, parsed data directly into the legacy CMS without this middle validation step would be like trying to shove a firehose through a needle. It guarantees a mess.
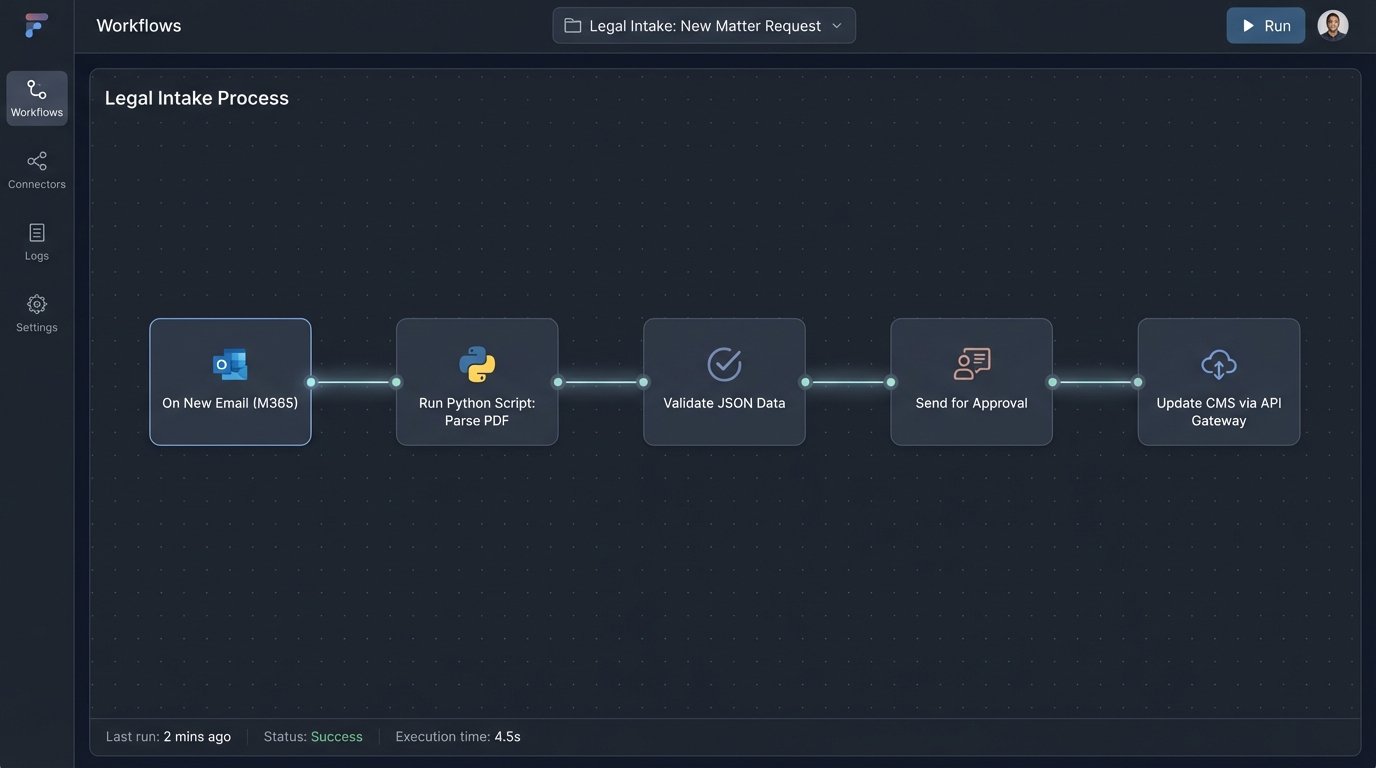
3. The CMS API Gateway: This was the most critical piece of custom engineering. The firm’s CMS had a SOAP API that was both sluggish and unforgiving. We built a small microservice that acted as a facade, exposing a clean, modern RESTful API to our orchestration engine. This gateway handled all the ugly work of authentication, session management, and transforming our simple JSON into the complex XML the legacy system demanded. It also managed rate limiting and retries, making the fragile endpoint appear stable to the rest of our system.
This approach de-risked the project significantly. We were not modifying the core CMS. We were simply building a better door to get data into it. The firm’s IT department was more comfortable with this approach, as it isolated our new components from their core systems of record.
The Reality of Implementation
The technical build was straightforward. The real challenge was data hygiene and user adoption. The first data migration tests revealed years of inconsistent data entry in the CMS. We had to run a massive data cleansing project in parallel, standardizing client names and case types before the automation could function reliably. You cannot automate a process built on a foundation of bad data.
User adoption was the other hurdle. Paralegals were accustomed to their spreadsheets. We had to remove the old option entirely. The new process was not optional. We conducted mandatory training sessions that focused on the outcome: less data entry for them and more time for high-value work. Once they saw the system could open a new matter in minutes, not hours, the resistance faded.
Measuring the Actual Return
After six months of operation, we measured the same KPIs we had benchmarked at the start. The results were immediate and substantial.
The hard numbers told a clear story:
- Intake Time Reduction: The average time from receiving a request to having an active matter in the CMS dropped from 4 hours to just 15 minutes. This includes the average time for attorney approval.
- Error Rate Collapse: The data entry error rate fell from 8% to less than 0.5%. The only errors remaining were from incorrect source documents, not manual keying mistakes.
- Reclaimed Paralegal Hours: We calculated that the system saved the firm approximately 20,000 paralegal hours per year. This was time they could now dedicate to billable activities like document review and case preparation.
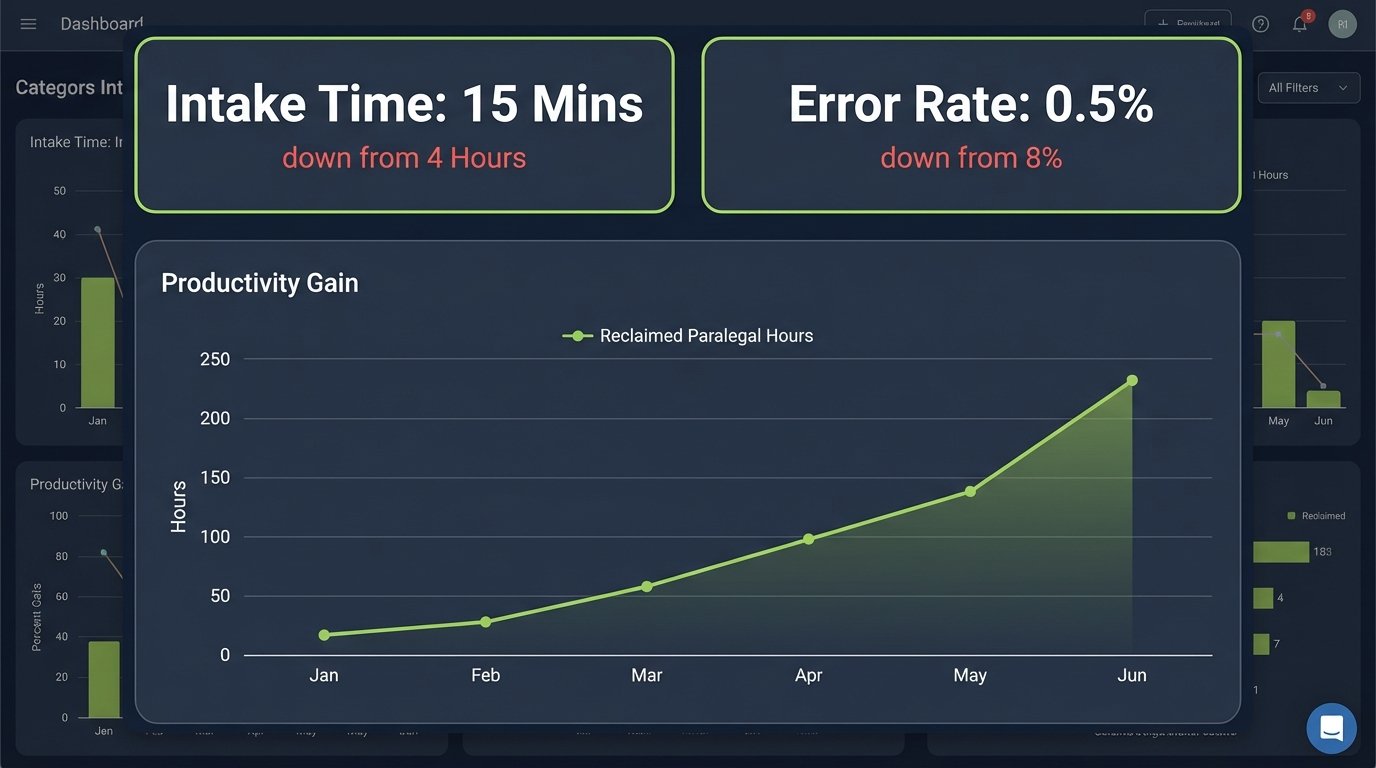
The financial ROI was calculated based on these metrics. The 20,000 reclaimed hours, at a blended paralegal rate of $150/hour, represented a $3 million productivity gain. Even if only half of that time was converted to new billable work, it still amounted to $1.5 million in potential new revenue annually. The entire project, including software licensing and implementation consulting, cost just under $750,000. The system paid for itself in six months.
The second-order effects provided even more value. The speed of intake became a selling point for the firm’s litigation support services. The data flowing into the CMS was now clean and structured, which opened up new possibilities for data analytics and business intelligence. Partners could now pull real-time reports on the litigation pipeline without having to ask a paralegal to compile a spreadsheet.
This project was not about buying a single piece of software. It was about re-architecting a broken business process. The technology was a tool, but the real work was in analyzing the workflow, cleaning the data, and forcing a change in how people operated. The return on investment was not just a number on a balance sheet. It was a fundamental improvement in the firm’s operational capacity.