
The core failure of most business processes is not strategic. It is mechanical. It is the latency and error rate injected by shuffling digital paper, typically PDFs and spreadsheets, between systems that do not speak to each other. This manual intervention, often framed as “human oversight,” is a systemic bottleneck that introduces unpredictable failures. Every time a human re-keys an invoice number or copies a shipping address, you are rolling the dice on data integrity.
We are not talking about simple typos. We are talking about cascading failures where incorrect data propagates from a sales order into the ERP, then into the logistics platform, and finally onto a shipping label. The cost to unwind that single error is astronomical compared to the cost of preventing it. The entire concept of processing documents by hand is a relic of a pre-API economy.
Diagnosing the Failure Points in Manual Document Handling
Legacy transaction flows are brittle by design. They rely on a series of disconnected, manual steps that function as failure traps. The first point of failure is ingestion. An emailed PDF is not a data source. It is an image of data, locked away behind a presentation layer. Optical Character Recognition (OCR) is the typical first response, but it is a weak bridge. OCR engines struggle with low-resolution scans, varied layouts, and an intern spilling coffee on the document.
You get garbage characters and misplaced fields. This forces a human to visually inspect and correct the OCR output, negating any automation and reintroducing the primary risk of manual entry. It is a slow, expensive, and fundamentally unreliable method for extracting structured information.
The Validation Black Hole
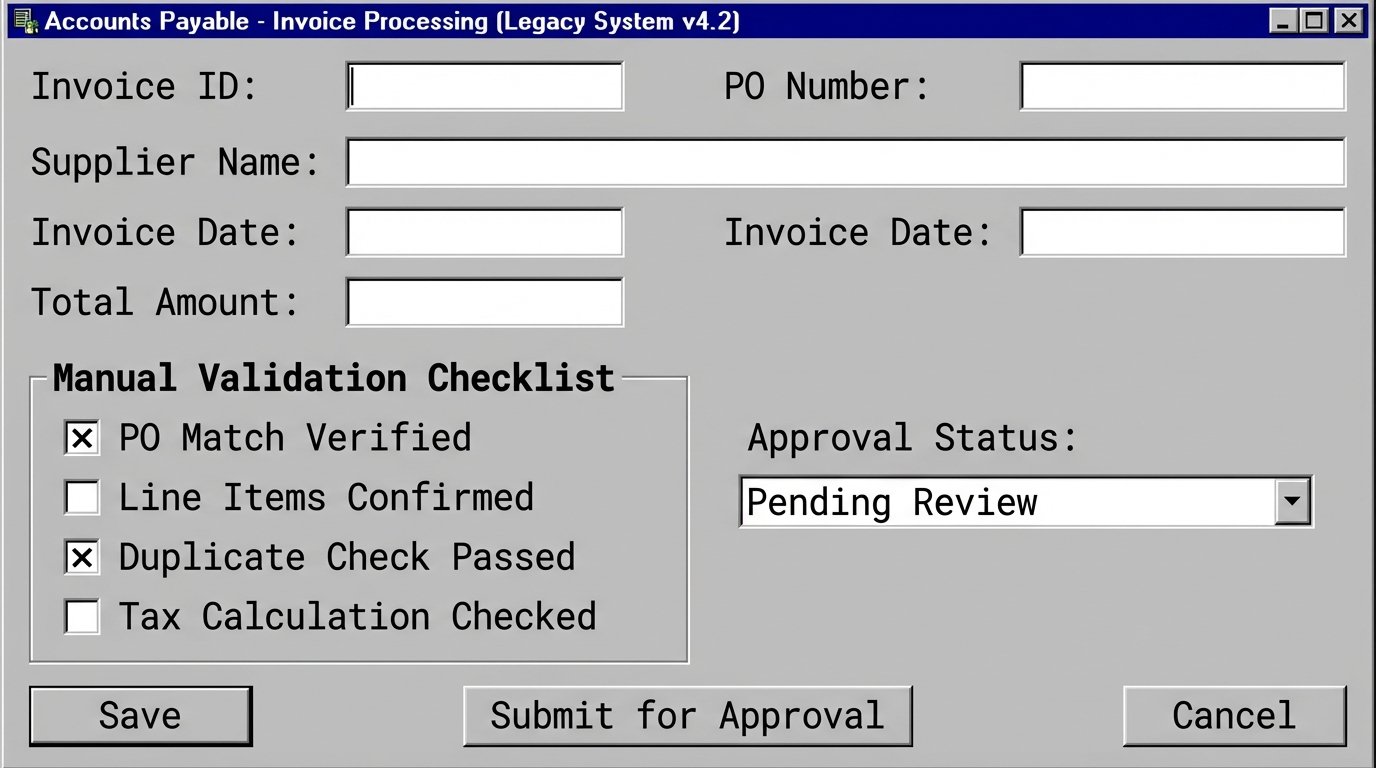
Assuming the data is extracted correctly, it next enters the validation stage. In a manual system, this means a checklist. An accounts payable clerk checks if the purchase order number matches the invoice. They check if the line items are correct. This process is entirely dependent on the individual’s focus and knowledge. Business rules are not enforced programmatically. They exist in a binder or worse, in the collective memory of the team.
This approach does not scale. It creates variance in rule application and makes auditing a nightmare. Finding out why a transaction was approved requires interviewing the person who approved it, assuming they remember the specific transaction from three weeks ago.
Data Enrichment as a Manual Lookup
Transactions often require enrichment with data from other systems. For example, a new client order might require a credit check or a lookup of the customer’s master record in the CRM. Manually, this means the operator opens another application, runs a search, copies the required data, and pastes it back into the primary system.
Each context switch is a point of delay and a potential source of error. The operator might pull the wrong customer record or misinterpret the credit status. The entire process is held hostage by the speed of the user and the responsiveness of secondary systems.
Architecture for a Digital Transaction Pipeline
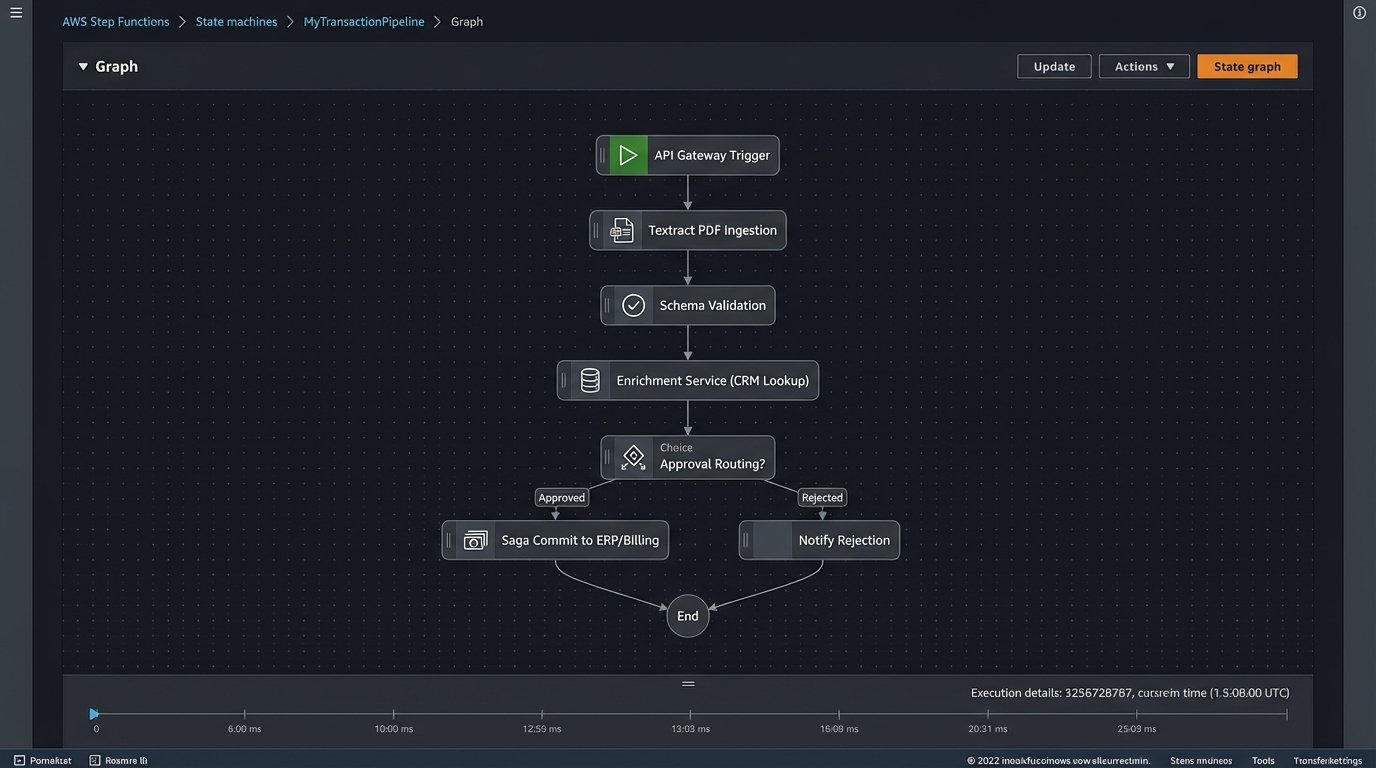
The fix is to architect a system that treats a transaction as a single, atomic unit of data flowing through a controlled, automated pipeline. The goal is to eliminate human hands from the process entirely, except for handling true exceptions. This is not about building one massive application. It is about orchestrating a set of specialized microservices that each perform one function reliably.
This architecture is built on a simple principle. Structure is non-negotiable. The pipeline must reject any data that does not conform to a predefined, machine-readable contract. Ambiguity is the enemy.
Component 1: The API-First Intake Manifold
All transactions must enter the system through a controlled gateway, preferably a set of RESTful APIs. Your business partners should be sending you JSON payloads, not scanned PDFs. This enforces a strict data contract from the very beginning. You define the required fields, data types, and formats in a schema, and the API gateway rejects any request that violates it. This pushes the responsibility of data quality back to the source.
If you are stuck supporting legacy partners who can only send PDFs, the first step inside your system is immediate and aggressive conversion. An industrial-grade document AI service like AWS Textract or Google Document AI guts the document, extracts the key-value pairs, and structures them into your canonical JSON format. Anything that fails this conversion is shunted to an exception queue for manual review.
Trying to force raw API JSON into a 20-year-old relational database is like shoving a firehose of data through the eye of a needle. You need a pressure regulator, a transformer, to reshape the flow without losing the important bits. The goal is to get all incoming data into one consistent shape before it goes any further.
A basic data contract for an invoice might look like this. It is simple, explicit, and leaves no room for interpretation.
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Invoice",
"description": "A standard invoice data structure",
"type": "object",
"properties": {
"invoiceId": {
"type": "string",
"pattern": "^[A-Z0-9]{8,16}$"
},
"customerId": {
"type": "string"
},
"issueDate": {
"type": "string",
"format": "date"
},
"dueDate": {
"type": "string",
"format": "date"
},
"lineItems": {
"type": "array",
"items": {
"type": "object",
"properties": {
"sku": { "type": "string" },
"quantity": { "type": "integer", "minimum": 1 },
"unitPrice": { "type": "number", "exclusiveMinimum": 0 }
},
"required": ["sku", "quantity", "unitPrice"]
}
}
},
"required": ["invoiceId", "customerId", "issueDate", "lineItems"]
}
Component 2: The Automated Validation Engine
Once the data is ingested and structured, it hits a dedicated validation service. This service is stateless and its only job is to enforce business rules programmatically. It confirms that the customer ID exists in the CRM. It cross-references the SKU on each line item with the product catalog. It checks if the total amount exceeds a certain threshold requiring special approval.
This is not a simple script. It is a microservice that ingests the transaction data, runs a battery of logic checks, and either passes the transaction to the next stage or flags it with specific error codes and routes it to an exception queue. Using a dedicated rules engine can be useful here, but for many cases, a well-organized codebase is sufficient. The key is that every rule is codified, versioned, and executed identically every single time.
Component 3: Enrichment and Transformation
A validated transaction is trustworthy, but it may not be complete. The enrichment service is responsible for adding necessary data from other systems of record. It might fetch the full customer shipping address from the CRM, pull the latest product descriptions from the PIM, or append tax information based on the customer’s location. This is done via direct, server-to-server API calls.
The service enriches the canonical data object. Following enrichment, a transformation step may be required to map the data into the specific format required by the destination system, especially when dealing with legacy ERPs that expect a rigid, outdated schema. This logic must be isolated to prevent tight coupling between systems.
Component 4: The Atomic Commit to Systems of Record
The final stage is the most critical. The fully validated and enriched transaction data must be committed to one or more systems of record, like an ERP and a billing platform. This operation must be atomic. If the update to the ERP succeeds but the write to the billing platform fails, the entire transaction must be rolled back from the ERP to prevent data inconsistency.
Implementing a distributed transaction protocol like a two-phase commit or a Saga pattern is essential. The Saga pattern is often more practical in a microservices environment. Each service commits its local transaction and publishes an event. Subsequent services listen for these events to perform their work. If a step fails, a series of compensating transactions are triggered to undo the preceding work. It is complex, but it is the only way to guarantee consistency across distributed systems.
The Reality of Implementation and Tooling
Building this pipeline is not a trivial task. It requires a robust workflow orchestration engine to manage the flow of data between services. Tools like AWS Step Functions or Camunda are built for this. They provide state management, retries, and error handling out of the box. Using a batch-oriented tool like Airflow for a real-time transaction process is a common mistake that leads to unacceptable latency.
Your choice of an API Gateway is also critical. A gateway like Kong or Apigee handles the tedious but necessary work of authentication, rate limiting, and request routing. Building this plumbing yourself is a waste of engineering resources. Focus on the business logic inside your services, not on reinventing infrastructure.
The biggest shift is not technical. It is operational. The goal of this architecture is to process 99% of transactions without any human involvement. The role of the operations team changes from data entry to exception management. Their new job is to monitor a dashboard of failed transactions, diagnose the root cause of the failure based on the error codes from the validation engine, and either correct the source data or fix the underlying business rule. This requires a more analytical skillset.
Moving from a paper-based process to a fully digital transaction pipeline is a foundational change. It forces discipline in data management and process definition. The initial investment is significant, and the political resistance from departments accustomed to their manual workarounds can be the biggest hurdle. But the alternative is to continue operating with a slow, opaque, and error-prone system that cannot compete at scale.