Transaction Automation Is A Minefield Of Silent Failures
We build automation to eliminate manual work, but often we just invent more complex ways for things to break at 3 AM. A poorly designed transaction workflow doesn’t just fail; it fails silently, corrupting data or double-charging accounts until someone in finance notices the balance is off by six figures. The goal isn’t to build a system that never fails. The goal is to build a system that fails predictably and recovers cleanly.
Forget the sales pitches. This is about what happens after the ink is dry on the software contract and you’re left to connect a legacy payment gateway to a modern invoicing system over a flaky VPN. Below are the common pits engineers fall into when architecting these systems, and the practical, non-negotiable fixes.
Mistake 1: Assuming OCR Is a Solved Problem
The first step in many document processing workflows is Optical Character Recognition. The marketing material shows a crisp, clean PDF being ingested perfectly. The reality is a poorly scanned, coffee-stained invoice faxed in 1998 and then photocopied three times. Relying on raw OCR output without a validation layer is architectural negligence.
OCR engines provide confidence scores for a reason. They are admitting their own uncertainty. Your job is to listen. A 95% confidence score on a total amount field isn’t good enough. You must inject logic-checks to cross-validate the extracted data. For an invoice, this means verifying that `subtotal + tax = total`. If the math is wrong, the OCR read is wrong. The document gets flagged for manual review.
Simple pattern matching with regular expressions is another mandatory layer. An invoice number should match a specific format, like `INV-2024-[0-9]{5}`. A date field must parse into a valid date. These checks catch the most egregious OCR errors before they ever hit your business logic.
Your automation’s credibility dies the moment it processes a $900,000 payment instead of $90.00.
# This is a conceptual Python example, not production code.
import re
def validate_invoice_data(ocr_text):
data = {}
# Extract with regex, not just blind trust
invoice_id_match = re.search(r'INV-[0-9]{6}', ocr_text)
if not invoice_id_match:
raise ValueError("Invoice ID format invalid.")
data['invoice_id'] = invoice_id_match.group(0)
# Logic-check the numbers
subtotal = float(re.search(r'Subtotal: \$([0-9.]+)', ocr_text).group(1))
tax = float(re.search(r'Tax: \$([0-9.]+)', ocr_text).group(1))
total = float(re.search(r'Total: \$([0-9.]+)', ocr_text).group(1))
# The actual validation gate
if abs((subtotal + tax) - total) > 0.01: # Account for float precision
raise ValueError("Financials do not reconcile. Flag for manual review.")
data['total'] = total
return data
Mistake 2: Disregarding API Throttling and Latency
Your logic is perfect. Your code is clean. You deploy a workflow to process a backlog of 5,000 transactions. The first 50 work flawlessly, then everything grinds to a halt with a storm of `429 Too Many Requests` errors. You’ve just discovered the third-party API’s rate limit, which was probably buried on page 47 of their documentation.
Treating external APIs as if they are local function calls is a foundational error. They are unreliable, slow, and have rules you must obey. The fix is to decouple your processing engine from the API calls themselves. Do not loop through a list and call the API directly. Instead, push each transaction task into a message queue like RabbitMQ or AWS SQS. A separate pool of workers can then pull from this queue at a controlled rate, respecting the API’s limits.
This architecture gives you throttling, but you also need to handle transient failures. The API might return a `503 Service Unavailable` because it’s having a bad day. Your worker should not immediately fail the transaction. It must implement an exponential backoff strategy. It retries the call after 2 seconds, then 4, then 8, and so on, before finally moving the message to a dead-letter queue for investigation.
The network doesn’t care about your batch job’s success.
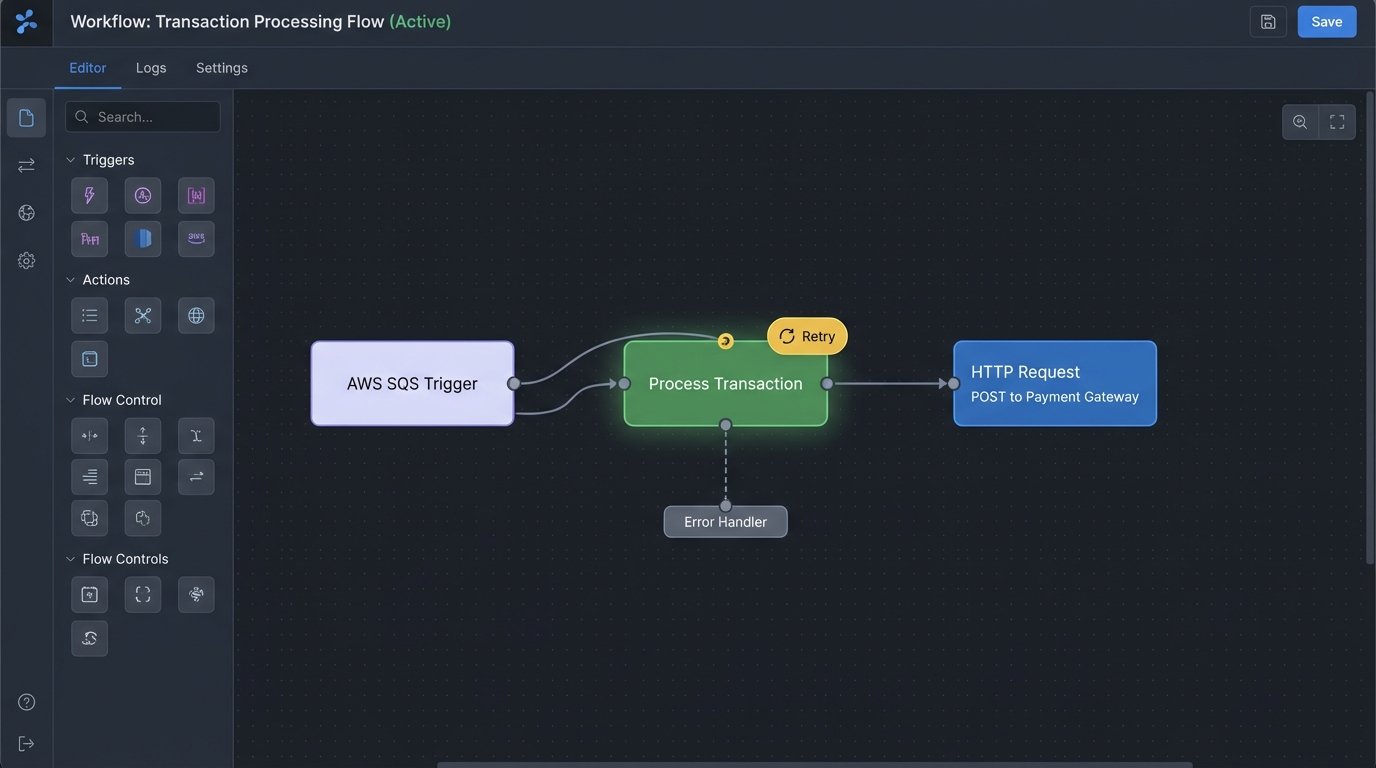
Mistake 3: Building Monolithic Workflows
A typical transaction process might have several stages: Receive, Validate, Enrich, Authorize Payment, Record, Notify. A monolithic script attempts to do all of this in a single, linear execution. If the “Record” step fails because of a database deadlock, the entire process must be restarted from the beginning, which might re-authorize a payment that already went through.
This is fragile and opaque. A better approach is to model the workflow as a state machine. Each stage is an independent, idempotent function. The state of each transaction (`RECEIVED`, `VALIDATION_FAILED`, `PAYMENT_AUTHORIZED`) is tracked persistently in a database or a service like AWS Step Functions. When a transaction fails at the “Record” stage, you can simply restart that specific stage once the database issue is resolved. You don’t have to re-run the payment authorization.
Thinking in states forces you to define failure paths explicitly. What happens if validation fails? The state becomes `VALIDATION_FAILED` and a notification is sent. What if the payment gateway is down? The state becomes `AUTHORIZATION_PENDING_RETRY` and the system tries again later. This gives you visibility and control over in-flight transactions.
A monolithic process is like an old string of holiday lights. One bulb burns out and the entire string goes dark. A state machine is like a modern LED string; you just find and replace the one faulty bulb without taking down the whole setup.
Your system spends most of its life in a state of partial failure. Design for it.
Mistake 4: Weak or Non-Existent Idempotency
Idempotency ensures that making the same request multiple times produces the same result as making it once. Without it, a simple network hiccup that triggers an automated retry can lead to a customer being charged twice or an inventory item being decremented twice. It’s one of the most critical and frequently overlooked aspects of transaction automation.
The fix is to enforce idempotency at the receiving endpoint. When the client system initiates a transaction, it should generate a unique key (a UUID is a good choice) called an idempotency key. This key is sent along with the request, typically in a header like `Idempotency-Key: some-unique-value`.
The server-side logic must be designed to handle this. Upon receiving a request, it first checks if it has ever processed a transaction with this key. If it has, it doesn’t re-process the logic. It simply returns the stored result from the original request. If the key is new, it processes the transaction, then stores the result and the key before sending the response. This prevents any duplicate operations caused by retries.
“Did we already do this?” is a question that your architecture must answer, not a person.
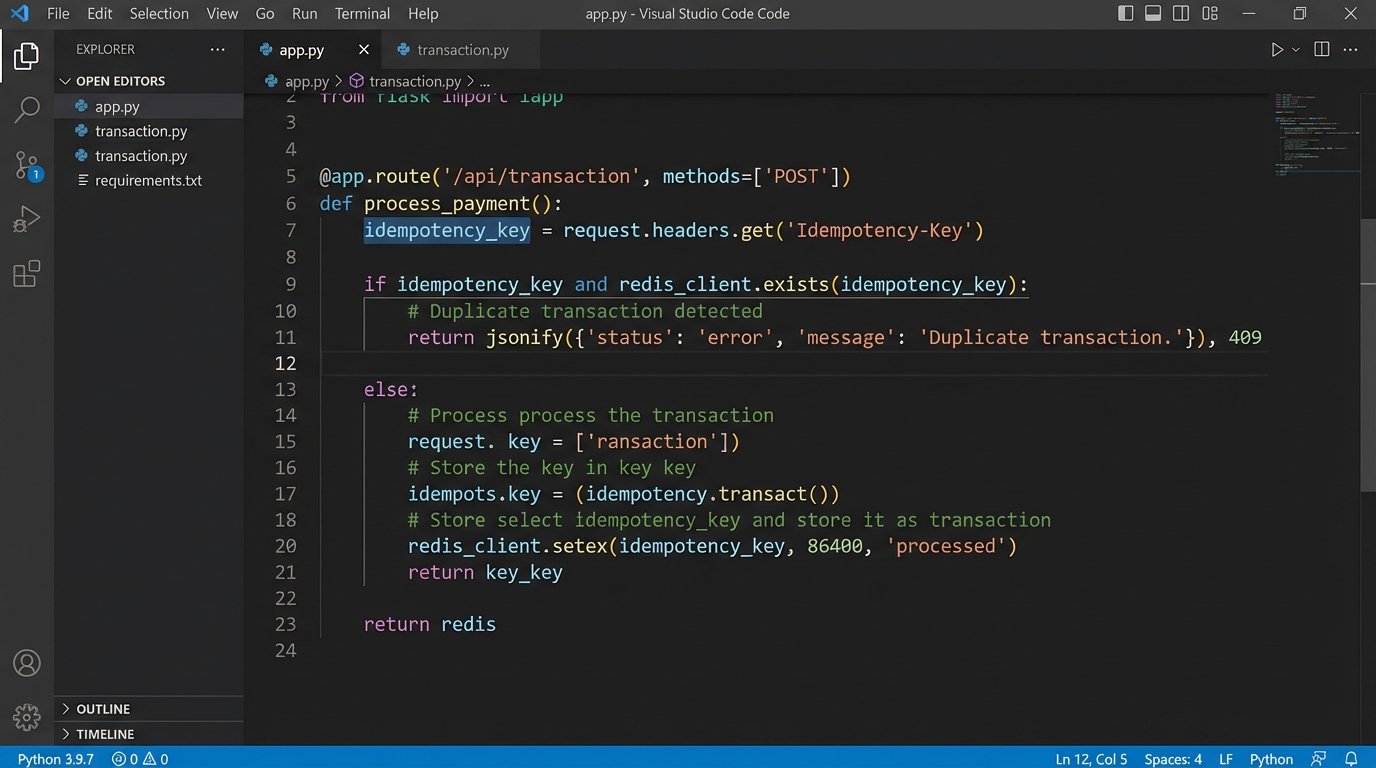
Mistake 5: Skipping Pre-Processing Normalization
Data arrives from different sources in different formats. One system sends dates as `MM/DD/YYYY`. Another sends `YYYY-MM-DD`. One partner sends currency as `$1,234.56` while another sends `1234.56`. Your core processing logic should not be cluttered with conditionals to handle this chaos. It creates a brittle system where adding a new data source requires changing the core engine.
The solution is to force all incoming data through a strict normalization pipeline *before* it’s accepted by the main workflow. This pipeline acts as a defensive barrier. Its only job is to strip, clean, and reformat data into a single, canonical format that your system understands. All dates become ISO 8601 strings. All monetary values are converted to cents and stored as integers. All country codes are standardized to two-letter ISO codes.
This approach decouples the problem of data ingestion from the problem of data processing. If a new partner sends data in a bizarre new format, you only update the normalization layer for that partner. The core transaction engine, which is far more critical and complex, remains untouched. It continues to operate on the clean, predictable data it expects.
Your automation is only as reliable as its most inconsistent input.
Mistake 6: Treating Monitoring as an Afterthought
Most teams set up basic “server down” alerts and call it monitoring. This is insufficient for transaction systems. A server can be running perfectly while the automation logic is stuck in a loop, failing to process a queue that is growing by thousands of items per hour. The system is “up,” but it is not working.
Effective monitoring for automation requires tracking the health of the process, not just the infrastructure. You need to instrument your code to expose key metrics.
- Queue Depth: How many transactions are waiting to be processed? If this number grows continuously, your workers can’t keep up.
- Processing Latency: What is the average time from when a transaction is received to when it is completed? A sudden increase indicates a bottleneck.
- Error Rate by Type: Don’t just count total errors. Differentiate between `VALIDATION_FAILURE` and `API_TIMEOUT`. One indicates bad data, the other a failing dependency.
- Dead-Letter Queue Size: How many transactions have failed all retry attempts? A non-zero number here requires immediate human investigation.
Feed these metrics into a system like Prometheus or Datadog. Build dashboards that give you a real-time view of the workflow’s health. Configure alerts for anomalies, not just total failures. For example, alert if the P95 latency exceeds 5 seconds, or if the number of validation failures from a specific partner doubles.
If you learn about a problem from an angry email instead of an automated alert, you don’t have a monitoring strategy.

Building these systems isn’t about finding the perfect tool. It’s about having a deep-seated paranoia for how things break. Assume the network will fail. Assume the data will be malformed. Assume the API will reject your request. Architecting defensively is the only way to build transaction automation that doesn’t create more problems than it solves.