
The standard advice for real estate agents is to slap a Calendly link on their website and call it a day. This approach treats appointment scheduling as a solved problem, a simple utility. It is not. Off-the-shelf schedulers are data islands, creating logic traps that actively sabotage a serious agent’s workflow by failing to integrate context from the Multiple Listing Service or the Customer Relationship Management platform.
These tools know your stated availability. They do not know that a specific property only allows showings between 2 PM and 4 PM on Tuesdays. They do not know you blocked an hour in your CRM to draft an offer. The result is a constant, manual reconciliation of multiple calendars, leading directly to double bookings and frantic rescheduling calls. It’s a leaky pipe masked as a modern solution.
The Brittle Reality of Point-to-Point Glue
The first instinct is to patch these leaks with integration platforms like Zapier. You build a “Zap” to create a CRM contact when a Calendly meeting is booked. You build another to block your Google Calendar. Each connection is a separate, fragile thread. When a third-party API changes without warning, the thread snaps. You won’t know it’s broken until a client complains they never got a confirmation or you miss a meeting because the calendar event never synced.
This is not a system. It is a collection of dependencies waiting to fail. Debugging this mess involves checking error logs across three different platforms, each with its own latency and failure notification system, assuming notifications even exist. You are perpetually reacting to breakages instead of controlling the flow of information. The entire setup is as stable as a house of cards on a vibrating table.
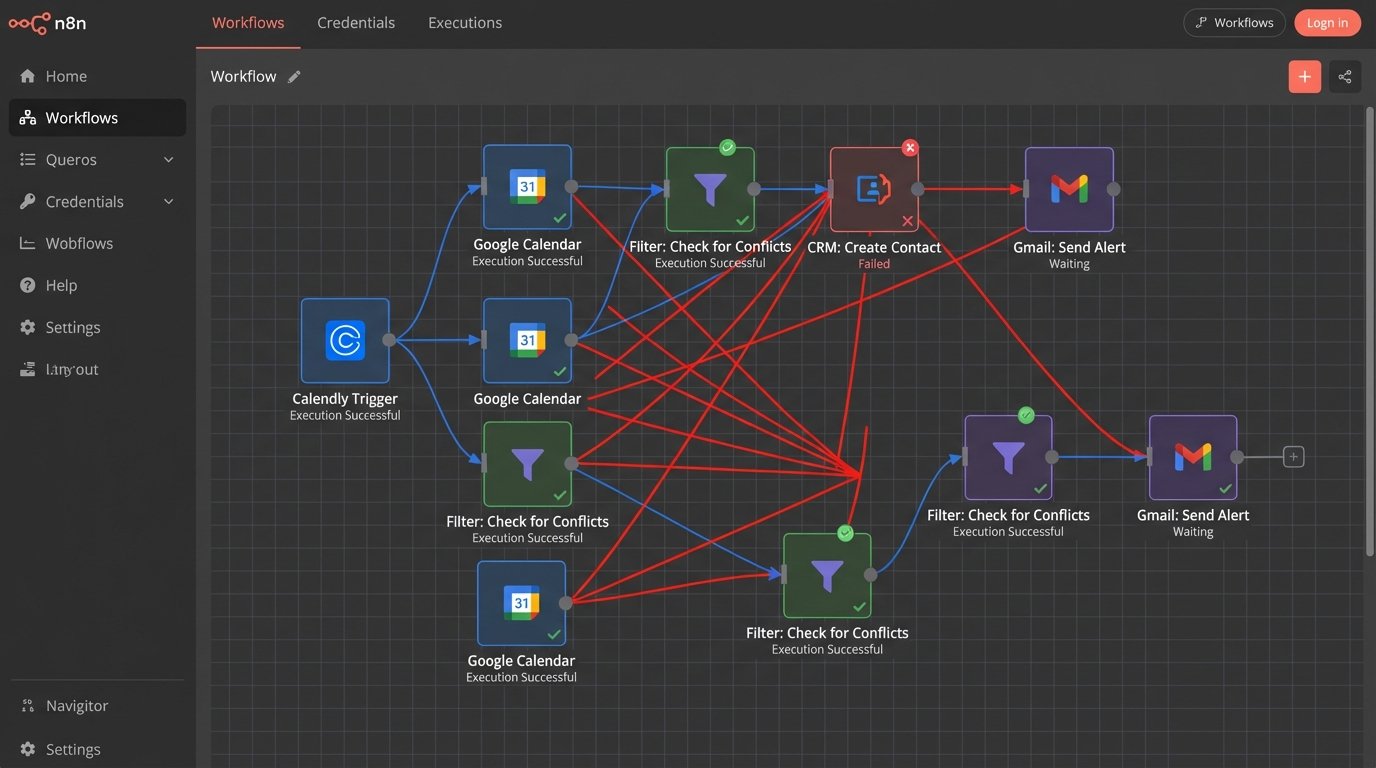
Trying to force real-time transactional logic through these asynchronous, batch-oriented platforms is a fundamental architectural error. It’s like trying to build a high-frequency trading bot using email alerts. The tool is simply wrong for the job, and no amount of complex, multi-step zaps can fix the underlying mismatch between the requirement for data integrity and the platform’s design.
Owning the Logic: The Availability State Machine
A durable solution requires gutting the third-party scheduling logic and building a central availability engine. This service acts as a state machine, becoming the single source of truth for an agent’s time. Its sole function is to ingest availability data from multiple sources, compute the final set of bookable slots based on a set of rules, and expose that information through a clean Application Programming Interface.
This is not about reinventing the calendar. It is about abstracting the business logic away from the presentation layer. Your Google Calendar still holds your personal appointments. Your CRM still holds your client tasks. The MLS still dictates showing windows. The engine’s job is to query these sources, merge their constraints, and present a single, coherent picture of what is actually possible.
Ingestion: The Data Scrape
The first step is pulling data. We connect to the Google Calendar API using OAuth 2.0 to fetch all “busy” events. This requires handling token refreshes and paginating through results. It’s a standard but tedious process that must be hardened against API rate limits and temporary network failures. We are not just reading the calendar, we are subscribing to a stream of its state changes.
Next, we bridge to the CRM. A platform like Follow Up Boss has a reasonably coherent API for pulling tasks and appointments assigned to a user. These are treated as additional “busy” blocks. The critical piece here is mapping the CRM’s event types to our engine’s logic. A “call” task might block 15 minutes, while a “Listing Appointment” task blocks 90 minutes and adds a 30-minute travel buffer before and after.
Connecting to the MLS is the ugliest part. MLS data access is a notoriously fragmented hellscape of legacy RETS feeds and inconsistent REST APIs, if one exists at all. In many cases, this step is impossible to fully automate. The fallback is a manual override where an agent or assistant can input a property’s specific showing constraints directly into the engine’s rule set. Assuming API access is possible, we query for a listing’s status and showing restrictions, adding them as a top-priority layer of constraints.
The Core Computation: Merging Time Blocks
Once we have lists of busy intervals from all sources, the core logic executes. The engine takes a date range, for example, the next 7 days, and creates a master list of all unavailable blocks. It then layers on the business rules: “no appointments after 7 PM,” “minimum 15-minute buffer between any two appointments,” “block all day if more than three showings are already booked.”
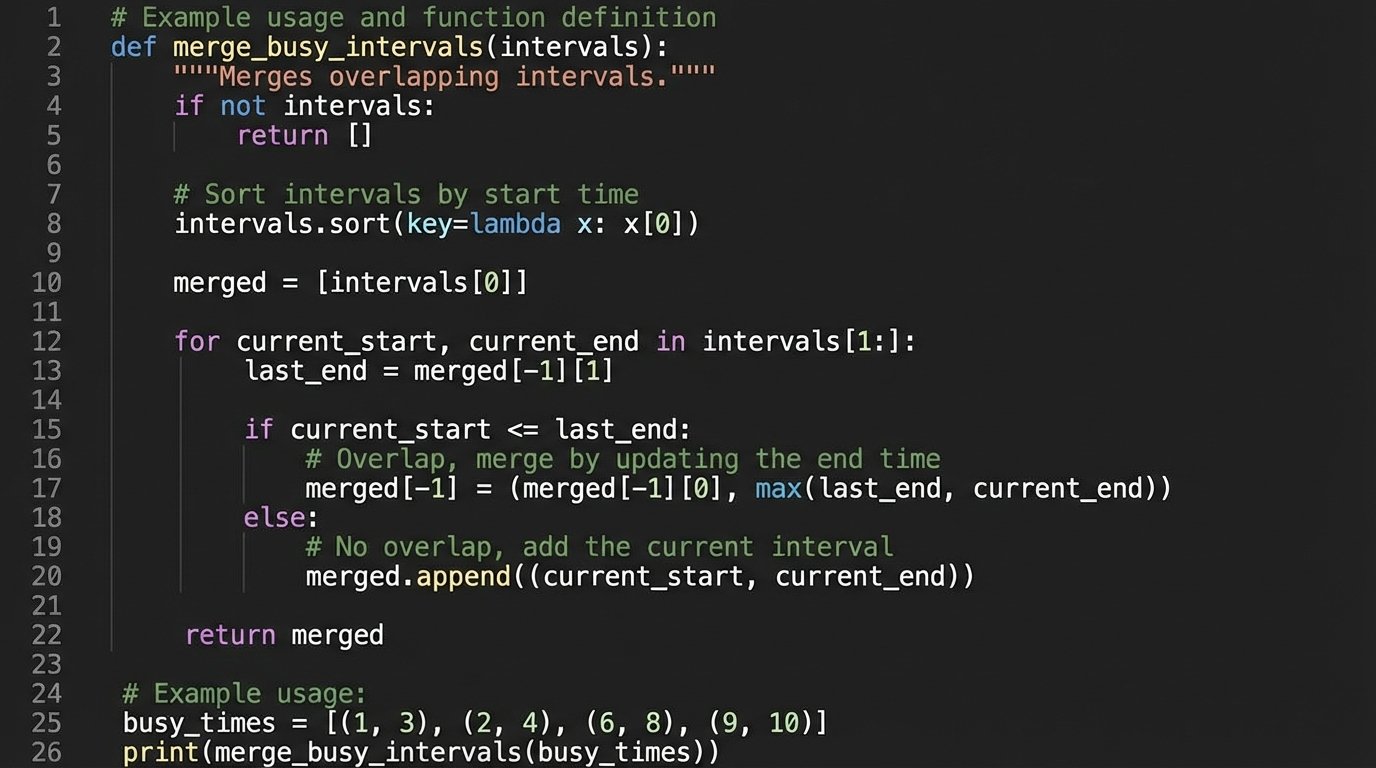
This process of merging and padding time intervals is where the real value lies. It’s a deterministic calculation, not a hope-and-pray sync operation. You get a precise list of available start times. This is the kind of logic you can write unit tests for. You cannot unit test a Zap.
The logic to flatten multiple busy schedules into one can be deceptively simple. The following Python snippet conceptualizes merging two sorted lists of busy time intervals. The real engine would do this for N sources and then apply the business rules.
def merge_busy_intervals(intervals):
if not intervals:
return []
# Sort intervals based on start time
intervals.sort(key=lambda x: x[0])
merged = [intervals[0]]
for current_start, current_end in intervals[1:]:
last_end = merged[-1][1]
# If the current interval overlaps with the last one, merge them
if current_start <= last_end:
merged[-1] = (merged[-1][0], max(last_end, current_end))
else:
merged.append((current_start, current_end))
return merged
# Example Usage:
google_calendar_busy = [(9, 10), (12, 13)] # 9-10 AM, 12-1 PM
crm_busy = [(9.5, 10.5), (14, 15)] # 9:30-10:30 AM, 2-3 PM
all_busy = google_calendar_busy + crm_busy
# The engine computes the final unavailability
final_busy_blocks = merge_busy_intervals(all_busy)
# Expected output: [(9, 10.5), (12, 13), (14, 15)]
# This represents the true unavailability after merging sources.
This computation is the engine’s heartbeat. It takes chaotic inputs from disconnected systems and produces a single, ordered output that represents ground truth. This is what enables reliable automation.
Exposure and Action: The API and Frontend
With the core logic defined, the engine exposes it through a simple, secure API. A primary endpoint like GET /available-slots?date=YYYY-MM-DD&duration=30 would return a JSON array of available appointment start times for a given day and duration. This endpoint is what a custom-built booking widget on the agent’s website would call.
The benefit of a custom frontend is total control. We can inject tracking pixels, A/B test the call to action, and design a user experience that matches the agent’s brand. We are not trapped inside the iframe of a third-party tool. When the user selects a time and submits their information, the frontend makes a POST /book-appointment call to our engine.
This POST request triggers the egress logic. The engine validates the requested slot is still available, then performs a series of actions:
- Creates an event on the agent’s Google Calendar, inviting the client.
- Creates a contact and logs the appointment activity in the CRM.
- Sends a confirmation email or SMS via a dedicated service like Twilio or Postmark.
- Optionally, triggers a webhook to notify other internal systems.
These actions are performed atomically. If any step fails, the system can roll back the transaction or flag it for manual review. This closed-loop system ensures data consistency across all platforms.
What This Architecture Actually Buys You
This approach isn’t about adding features. It’s about taking control. When you own the scheduling logic, you can implement rules specific to your business that no SaaS product will ever offer. You can enforce a 45-minute travel buffer for appointments more than 10 miles from your office. You can automatically decline showing requests for listings that are under contract. You dictate the rules of engagement.
Data integrity is the second major gain. By centralizing the logic, you eliminate the race conditions and sync delays inherent in point-to-point integration tools. The system cannot book an appointment for a time that is already blocked in another system because it checks all sources before presenting any slot as “available.” Double bookings become an architectural impossibility.
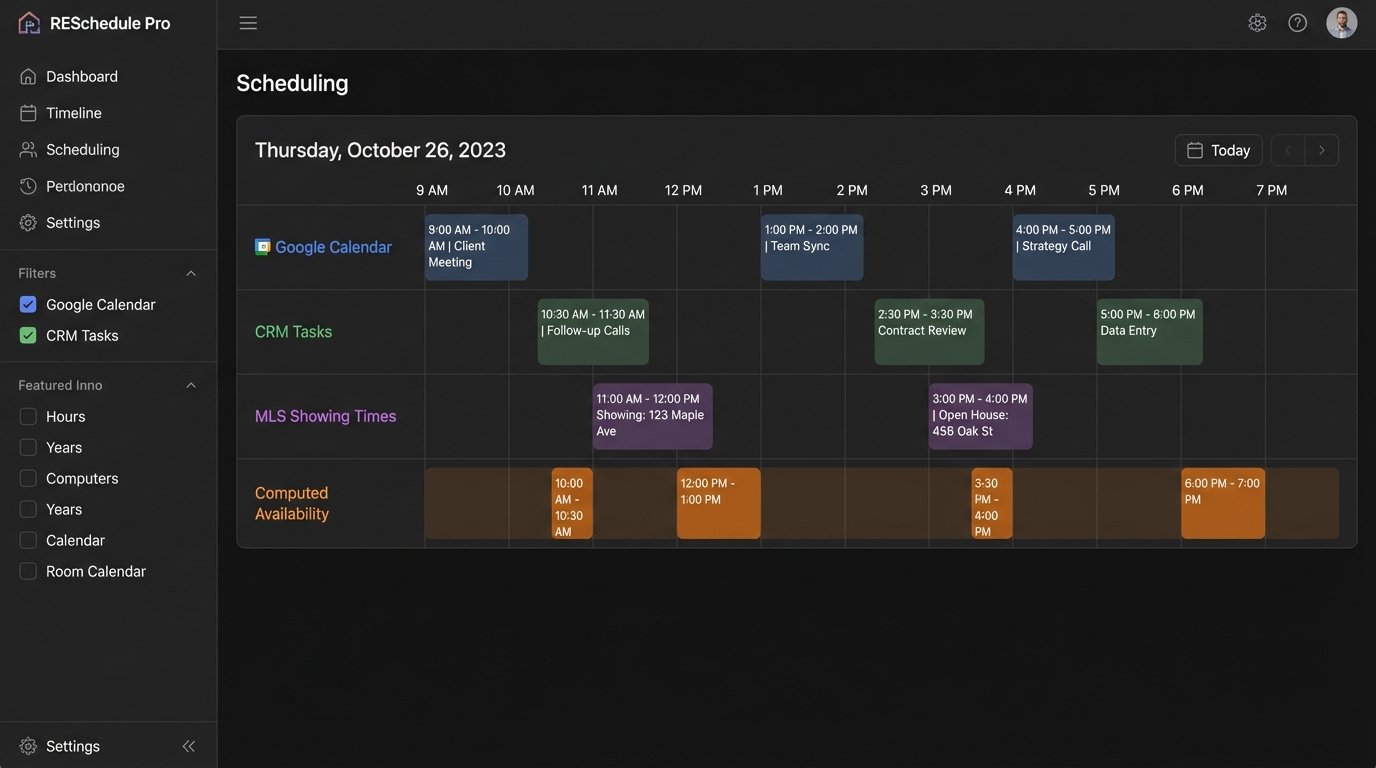
Finally, this architecture scales. It can handle complex team scheduling, round-robin assignments, and pooled availability scenarios that would require a top-tier, wallet-draining subscription on a commercial platform. Adding a new agent is a matter of adding their calendar credentials to the engine’s configuration, not rebuilding a dozen zaps.
The Real Cost
Building a service like this is not a trivial undertaking. It requires engineering resources, hosting infrastructure, and ongoing maintenance. The APIs it depends on will change, and the code will need to be updated. It is an asset that must be managed, not a disposable tool.
The decision to build versus buy is not about saving a few dollars on a monthly subscription. It’s a strategic choice. Agents who view technology as a simple expense will find this approach ludicrous. Operations that treat their workflow and data integrity as a competitive advantage will recognize the necessity.
The true cost of the off-the-shelf solution is not the subscription fee. It is the time lost to manual calendar checks, the client goodwill destroyed by scheduling errors, and the opportunities missed because your system was too rigid to adapt. The question is whether you can afford to continue paying that price.