Stop Blaming Users for Double-Booked Slots. Your Architecture is Broken.
A double-booked appointment isn’t a user error. It’s a system integrity failure. The root cause is almost always a flawed approach to state management, typically relying on asynchronous processes that operate on stale data. When two requests for the same 10:00 AM slot arrive milliseconds apart, your system has to definitively know which one to accept and which to reject. Anything less is just inviting chaos.
The common culprit is a batch-sync job that runs every five minutes. This approach is fundamentally flawed because it creates a window of vulnerability. In that five-minute gap, your booking system’s reality has drifted from the calendar’s reality. It’s a race condition waiting to happen, and at scale, it will happen. You end up with angry customers and operational overhead trying to manually reschedule the conflicts.
The Anatomy of a Sync Failure
The problem originates from treating two separate data sources, your application database and the target calendar (Google, Outlook), as if they are one. They are not. Network latency, API rate limits, and temporary service outages create unavoidable gaps between them. A user sees an open slot on your web front-end because your local database says it’s free. They click “Book,” and your system fires off an API call to the calendar.
While that API call is in flight, another user does the exact same thing. Your application, blind to the first in-flight request, green-lights the second booking. Both requests eventually hit the calendar API, which happily creates two events for the same time. The calendar API doesn’t know your business logic; it just executes valid commands. Your system failed to enforce its own rules before making the call.
Trying to manage state without a dedicated locking mechanism is like directing traffic in a tunnel with a flashlight. You can see what’s right in front of you, but you have no idea what’s coming from the other end until the crash. You need a centralized, authoritative source to signal that a resource is currently being contested.
The Architectural Fix: Event-Driven Syncing with Pessimistic Locking
A robust solution doesn’t poll for changes. It reacts to them in real time. This requires an event-driven architecture that triggers a workflow the instant a booking is attempted. The core components are a webhook listener, an orchestration function, a state-locking mechanism, and direct API communication with the target calendar.
This isn’t a simple “if-this-then-that” workflow. It’s a transaction that must be atomic. It either fully succeeds in booking the slot and locking it, or it fails completely, leaving the slot available. There is no middle ground.
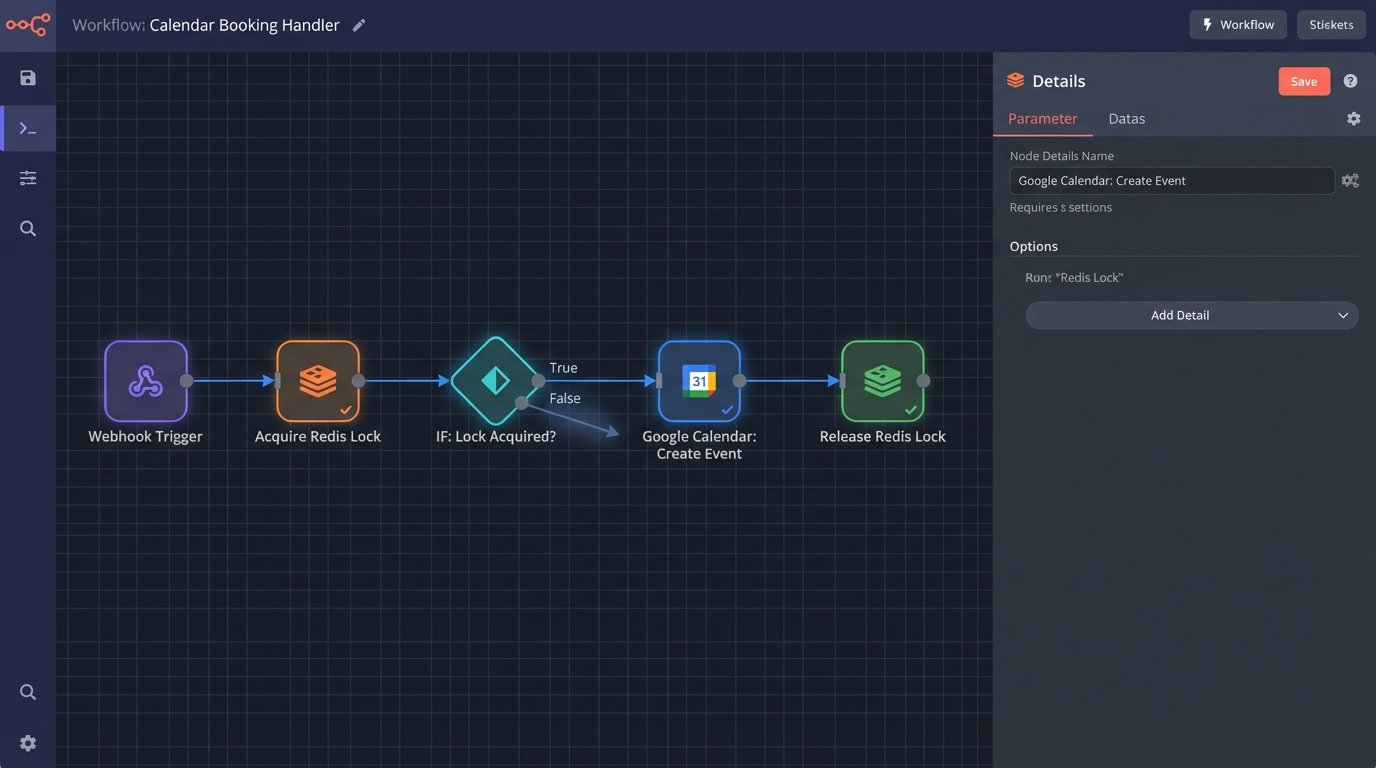
Component 1: The Webhook Listener
Your booking platform must fire a webhook the moment a user confirms an appointment. This is your trigger. The payload should contain all necessary data: `appointment_id`, `customer_id`, `staff_id`, `start_time_utc`, and `end_time_utc`. Your listener, typically an API gateway endpoint pointing to a serverless function, ingests this payload.
First-level validation happens here. Does the payload have the correct structure? Is the security signature valid? Many webhook providers include a signature in the headers, calculated using a shared secret. You must recalculate this signature on your end and compare it to the one provided. This logic-checks that the request is authentic and hasn’t been tampered with. If the signature fails, you drop the request with a 401 Unauthorized. Don’t process unverified data.
Component 2: The Orchestration Function and Locking Mechanism
This is where the real work gets done. The function, a Lambda or Cloud Function, receives the validated webhook payload. Its first job is not to call the calendar API. Its first job is to acquire a lock. This prevents race conditions cold.
We use a centralized cache like Redis or DynamoDB for this. The function creates a unique lock key, for example `lock:staff_id:start_timestamp`. It then attempts to write this key to Redis with a `SETNX` (SET if Not eXists) command and a short Time-To-Live (TTL), like 30 seconds. If `SETNX` succeeds, it means no other process is currently working on this exact time slot for this exact staff member. This process now owns the lock.
If the `SETNX` command fails, it means another process got there first. The lock already exists. The function immediately stops processing and can either return an error to the booking system or place the request in a queue for a retry. The key is that it does not proceed to the calendar API. This is pessimistic locking. We assume a conflict will happen and force processes to wait their turn.
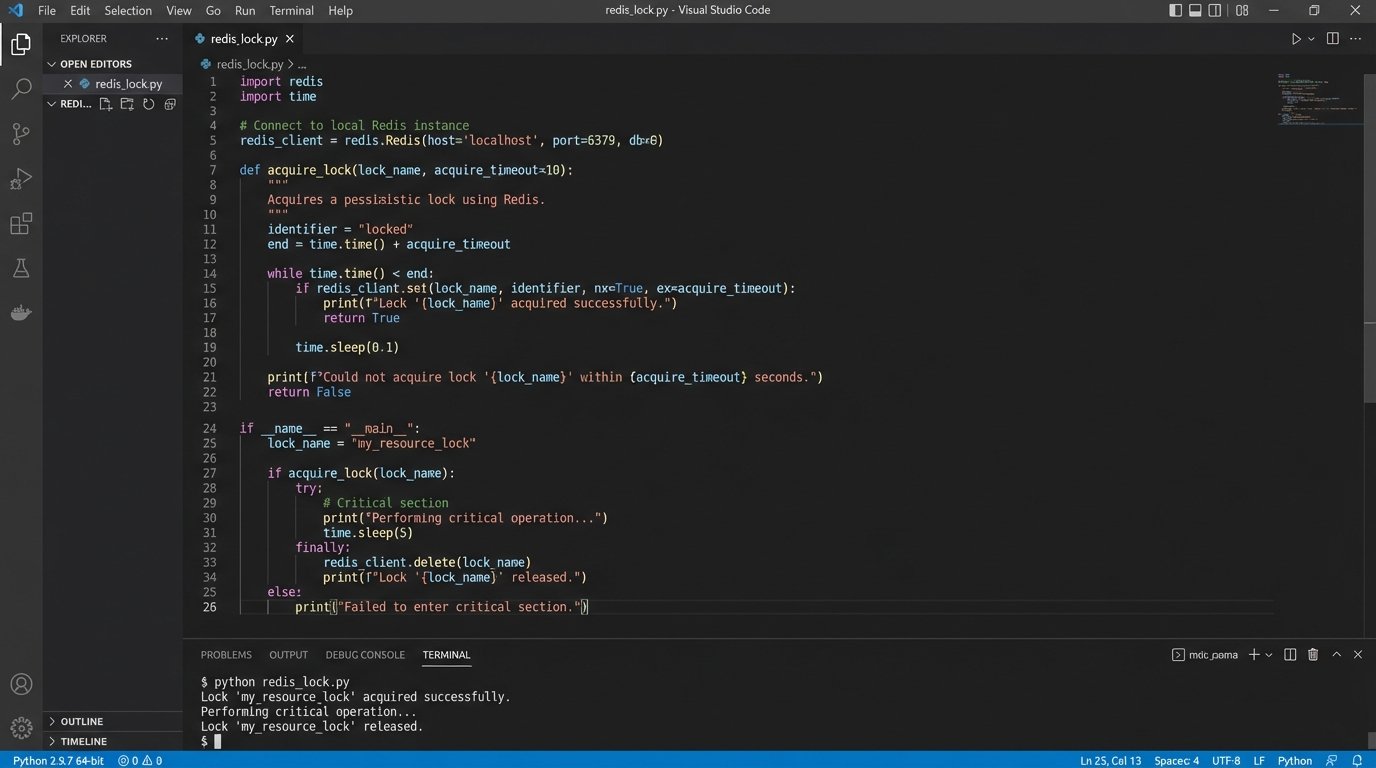
Here is a conceptual Python snippet of what this lock acquisition looks like using a Redis client.
import redis
import time
# Assume redis_client is a configured Redis client instance.
STAFF_ID = "staff_123"
START_TIMESTAMP = "1672531200" # Unix timestamp for the start of the slot
LOCK_TTL = 30 # seconds
def acquire_lock(staff_id, timestamp):
lock_key = f"lock:{staff_id}:{timestamp}"
# SETNX returns True if the key was set, False otherwise.
was_lock_acquired = redis_client.set(lock_key, "locked", ex=LOCK_TTL, nx=True)
return was_lock_acquired
# Main logic in the orchestration function
if acquire_lock(STAFF_ID, START_TIMESTAMP):
try:
# Lock acquired. Proceed to call the calendar API.
print("Lock acquired. Creating calendar event...")
# ... calendar_api.create_event(...)
finally:
# Always release the lock when done.
redis_client.delete(f"lock:{STAFF_ID}:{START_TIMESTAMP}")
print("Lock released.")
else:
# Lock was not acquired. Another process is handling this slot.
print("Failed to acquire lock. Slot is busy.")
# Terminate or queue for retry.
The lock must be released after the operation completes, whether it succeeds or fails. A `finally` block is critical here to prevent orphaned locks that would permanently block a time slot.
Component 3: The Target Calendar API
Once the lock is secured, the function can safely interact with the target calendar API, like Google Calendar or Microsoft Graph. Authentication is the first hurdle. You will be dealing with OAuth 2.0. This means your system needs a secure way to store and manage refresh tokens for each connected user account. HashiCorp Vault or AWS Secrets Manager are appropriate tools for this job. Do not store these tokens in plain text in a database column.
The next step is to correctly format the request. This involves mapping the data from your webhook payload to the structure the calendar API expects. Pay close attention to time zones. Your internal systems should operate exclusively in UTC. The payload you send to the calendar API must explicitly declare the correct time zone ID, like `America/New_York`. If you send a naive timestamp, the calendar will likely interpret it in its default time zone, causing the appointment to show up at the wrong time.
You also need to handle API responses correctly. A 2xx status code means the event was created. A 4xx or 5xx code indicates an error. Rate limiting is a common 4xx error (specifically 429 Too Many Requests). Your code must be able to handle this by implementing an exponential backoff retry strategy. Don’t just immediately retry. Wait one second, then two, then four, and so on, to avoid hammering the API and making the problem worse.
Error Handling and Reconciliation
What happens if the calendar API is down when you try to create an event? Your function holds a lock, but it can’t complete the operation. After a few retries, it should release the lock and push the failed event into a dead-letter queue (DLQ). A separate process can then monitor the DLQ to re-process these failures later when the API is back online.
This ensures that a temporary external outage doesn’t cause you to lose bookings. The original booking still exists in your system, and the DLQ holds the task to sync it to the calendar. Relying solely on webhooks without a reconciliation job is like trusting a shipping manifest without ever auditing the warehouse. Eventually, things go missing.
A nightly or hourly reconciliation job is still valuable, but its purpose changes. It’s no longer the primary sync mechanism. It’s a safety net. This script should query appointments from your database for a given period and cross-reference them with events in the target calendar. It reports any discrepancies, which could indicate a bug in your webhook processor or a webhook that was never delivered. This provides a mechanism to force data integrity over time.
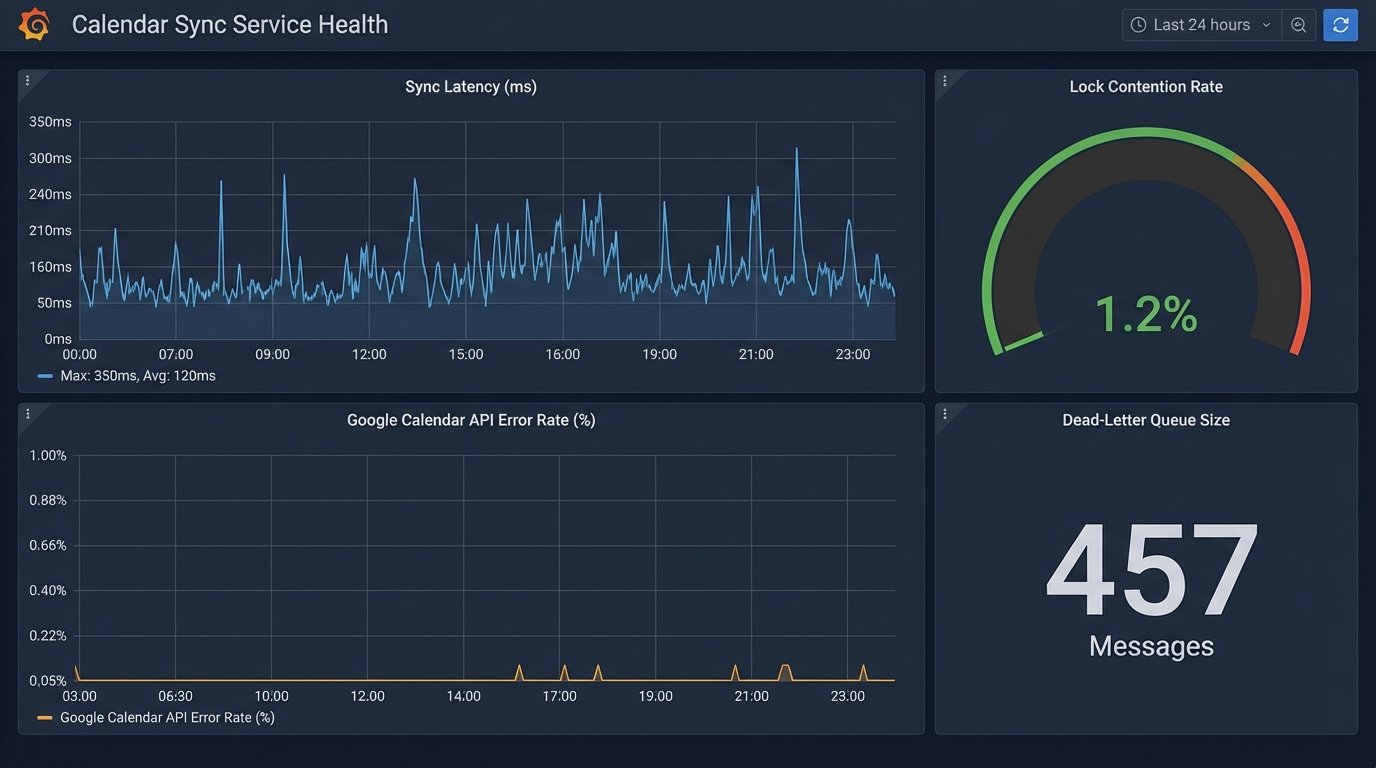
Monitoring the System
A system like this cannot run silently. You need telemetry. Key metrics to monitor include:
- Sync Latency: The time between a webhook being received and a calendar event being successfully created. A spike here could indicate network issues or problems with the calendar API.
- Lock Contention Rate: How often are processes competing for the same lock? A high rate might suggest performance bottlenecks or could be a valid result of a high-volume booking period.
- API Error Rate: The percentage of calendar API calls that fail. This should be near zero. Any sustained rate indicates a problem with authentication, request formatting, or the external service itself.
- Dead-Letter Queue Size: A growing DLQ is a clear signal that events are consistently failing to process and require manual intervention.
These metrics, fed into a dashboard like Grafana or Datadog, give you a real-time view of the system’s health. You can configure alerts to notify you of anomalies before they become widespread problems. This is the difference between a resilient, production-grade system and a fragile one that breaks silently.
Building this architecture is more complex than a simple batch job. The payoff is a system that eliminates double-bookings by design, not by chance. It handles race conditions, recovers from transient errors, and provides the visibility needed to maintain it effectively. It’s the correct way to solve the problem.