
The Technical Debt of Disconnected Calendars
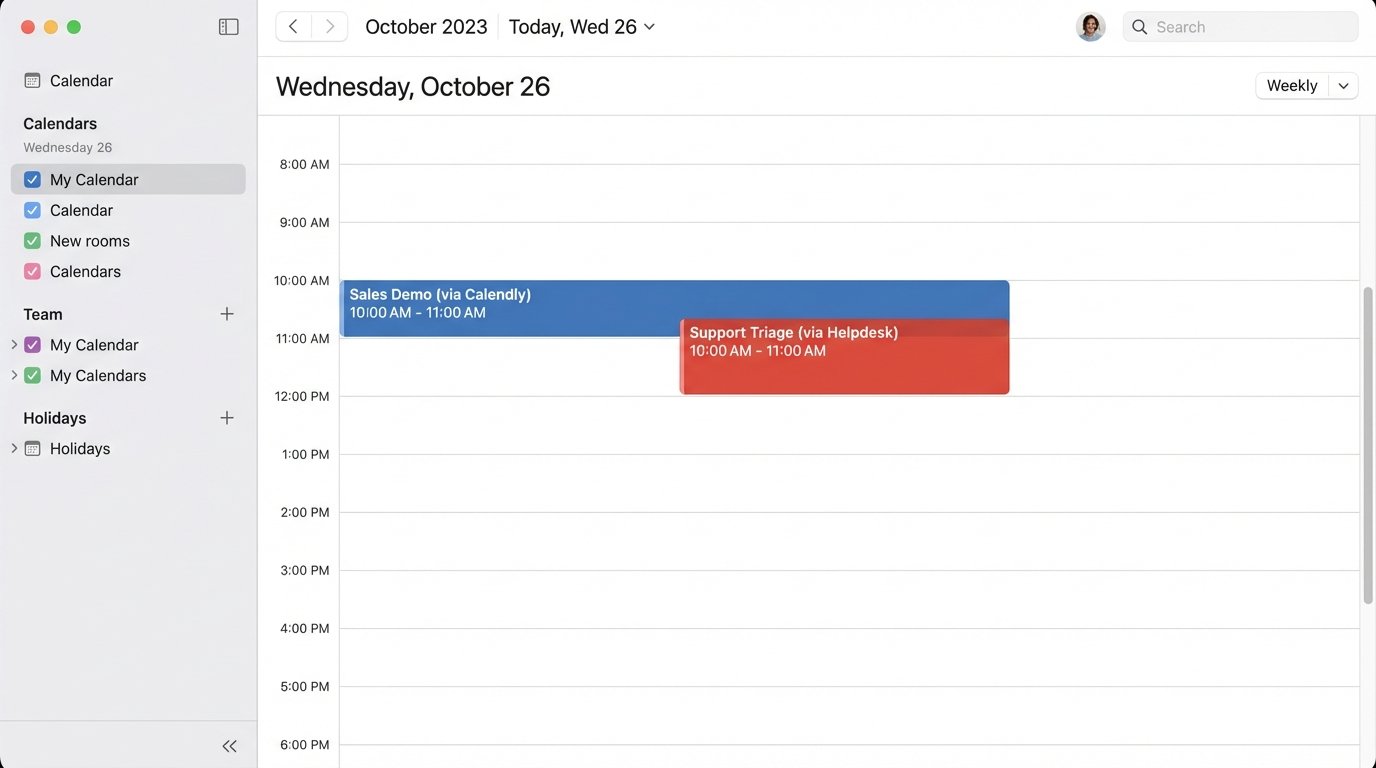
Multiple scheduling platforms operating in parallel are not a sign of a flexible tech stack. They are a source of data corruption. When Calendly, a sales CRM, and a support desk’s booking tool all have write-access to a resource’s time, you are not creating options. You are building a system that guarantees race conditions and data forks that require manual intervention to fix.
The core failure is the absence of a single source of truth. Each platform operates on a cached, and therefore stale, version of reality. This distributed state management model is fundamentally broken for high-concurrency operations like appointment booking.
Failure Point 1: Race Conditions and Double Bookings
The most immediate and visible failure is the double booking. System A checks for availability at 10:00 AM and finds the slot open. System B checks for the same slot milliseconds later and also finds it open. System A’s user confirms the booking. System B’s user confirms the booking. Both APIs write the event to their respective calendars. The sync job that runs every five minutes between them will eventually flag a conflict, but by then two customers have confirmations for the same time.
This is not a theoretical edge case. It is the mathematical certainty of running unsynchronized distributed systems.
Failure Point 2: Notification Noise and Signal Loss
A fragmented system bombards users with redundant or contradictory information. A customer books a demo through a marketing site’s scheduler. They receive a confirmation from that system. The salesperson’s CRM syncs the event and sends its own, slightly different confirmation. The salesperson’s Google Calendar then sends a third generic invite. This is unprofessional and erodes trust.
The inverse is worse. The customer cancels via the link in the Google Calendar invite. This cancellation event never propagates back to the CRM or the original booking tool. The salesperson still gets a reminder for a cancelled meeting, wastes time preparing, and calls a confused and annoyed prospect.
Failure Point 3: Data Fragmentation
Each scheduling tool becomes its own miniature CRM, collecting names, emails, and phone numbers. When a customer updates their contact information in one portal, that data is orphaned. The sales CRM retains the old phone number, marketing automation has the old email, and the support system has the new one. This makes automated follow-up sequences unreliable and potentially non-compliant with data privacy rules.
You cannot build a coherent customer journey when the customer’s identity is shattered across three different databases.
Architecting a Central Source of Truth
The fix is not another off-the-shelf calendar app. The fix is to architect an integration layer that serves as the canonical record for all appointments. This custom service becomes the single writer to the master schedule, while the external tools are demoted to read-only clients or write-requestors. All booking requests are funneled through this central logic gate, which serializes access and enforces consistency.
This is not a wallet-drainer project requiring a huge team. A single engineer can build a robust prototype using serverless functions and a managed database.
The Core Component: A Canonical Datastore
The heart of this system is a dedicated datastore. A simple PostgreSQL database is more than sufficient, offering transactional integrity that is critical for this use case. The schema does not need to be complex. A single table for events can hold the essential fields: `event_id`, `resource_id`, `start_time`, `end_time`, `status`, `attendee_details`, and `source_system`.
Using a relational database allows you to enforce constraints at the database level, such as preventing overlapping time slots for the same `resource_id`. This is your last line of defense against bugs in the application logic.
Ingestion Pathways: Webhooks vs. Polling
Getting data into the canonical store requires connecting to the source systems. The ideal method is through webhooks. When an event occurs in an external tool like Calendly, it sends an HTTP POST request to an endpoint you control. This is a real-time, event-driven approach. It is efficient and provides immediate data consistency.
The downside of webhooks is that you must expose a public API endpoint, which requires security measures like signature verification to prevent spoofed requests. You are also at the mercy of the third-party service’s reliability. If they have a service disruption and fail to send a webhook, you lose data unless they have a robust retry mechanism.
For legacy systems or APIs that do not support webhooks, you are forced to use polling. A scheduled job, such as a cron job or an AWS Lambda function on a timer, makes an API call to the external system every N minutes to ask for changes. This approach is sluggish, introduces latency, and is prone to hitting API rate limits. It is a brute-force solution, but sometimes it is the only one available.
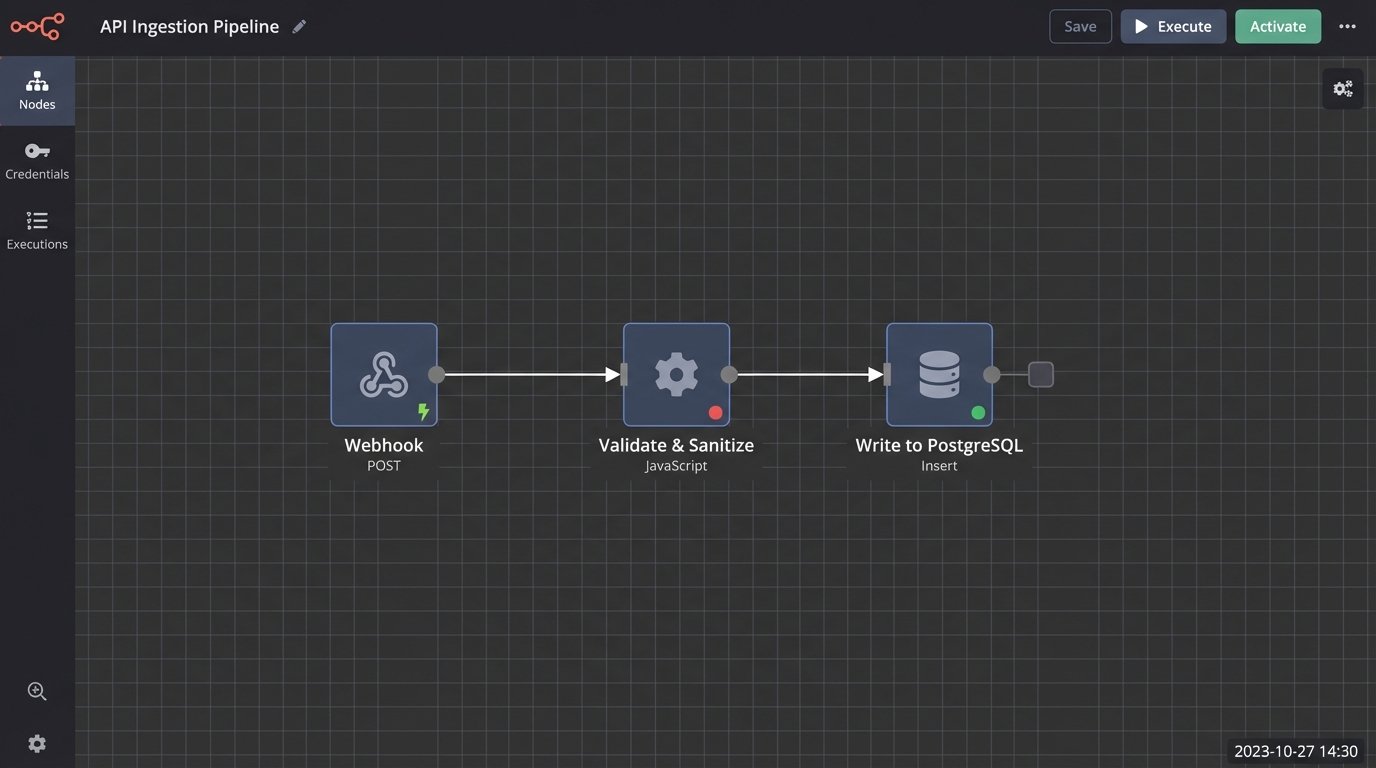
Processing and Validation Logic
Once data arrives, either from a webhook or a polling job, it must be processed before being written to the canonical datastore. This logic lives inside your integration service. Its job is to strip the incoming data down to its essential parts, validate its integrity, and map it to your internal schema. Never trust incoming data from a third-party API.
A payload from a scheduling tool might contain dozens of fields you do not care about. Your service should explicitly select the required fields and discard the rest. This prevents your system from breaking if the source API adds new, unexpected fields to its payload.
Here is a basic Python example using Flask for a webhook endpoint. It does not contain business logic, but it shows the necessary steps of signature verification, data extraction, and validation.
from flask import Flask, request, abort
import hmac
import hashlib
app = Flask(__name__)
# This should be stored securely, not hardcoded
WEBHOOK_SECRET = 'your_calendly_signing_key'
@app.route('/webhook/calendly', methods=['POST'])
def calendly_webhook():
# 1. Verify the signature to ensure the request is from Calendly
signature_header = request.headers.get('Calendly-Webhook-Signature')
if not signature_header:
abort(400, 'Missing signature header')
t_value, sig_value = signature_header.split(',')
timestamp = t_value.split('=')[1]
signature = sig_value.split('=')[1]
signed_payload = f"{timestamp}.{request.get_data(as_text=True)}"
expected_signature = hmac.new(
key=WEBHOOK_SECRET.encode(),
msg=signed_payload.encode(),
digestmod=hashlib.sha256
).hexdigest()
if not hmac.compare_digest(expected_signature, signature):
abort(403, 'Invalid signature')
# 2. Extract and validate the payload
payload = request.json
if payload.get('event') != 'invitee.created':
return 'OK', 200 # Ignore events we dont care about
event_data = payload.get('payload', {})
event_uri = event_data.get('uri')
start_time = event_data.get('start_time')
end_time = event_data.get('end_time')
if not all([event_uri, start_time, end_time]):
abort(400, 'Missing required event data')
# 3. Queue the data for processing (e.g., write to a message queue or call a service function)
# process_new_booking(event_uri, start_time, end_time)
return 'OK', 200
Propagation and State Management
After a new event is committed to the central database, the integration layer must propagate that change to all other relevant systems. This ensures their local state reflects the new source of truth. The service triggers API calls to the other platforms to create, update, or cancel the corresponding events in their systems.
These outbound API calls must be designed to be idempotent. If you try to create an event in a downstream system and the network connection times out, you do not know if the request succeeded. Your service must be able to safely retry the request. Using a unique identifier from your canonical store as an idempotency key in the target API prevents the creation of duplicate events on retries.
Implementing Conflict Resolution and Error Handling
The most difficult part of this architecture is correctly handling conflicts and failures. A well-designed system anticipates that downstream APIs will be slow, return errors, or go offline entirely. It also anticipates that near-simultaneous requests will attempt to book the same slot.
Atomic Writes and Pessimistic Locking
You can prevent double bookings by using database transactions. When a request to book a slot comes in, the service should start a transaction, check for availability for the given resource and time range, and if available, insert the new event record. The entire operation is wrapped in a transaction that locks the relevant rows, preventing any other process from reading that slot as “available” until the transaction is committed or rolled back.
This pessimistic locking strategy is simple and highly effective. It serializes access to calendar slots at the database level, which is the only place where you can truly guarantee consistency.
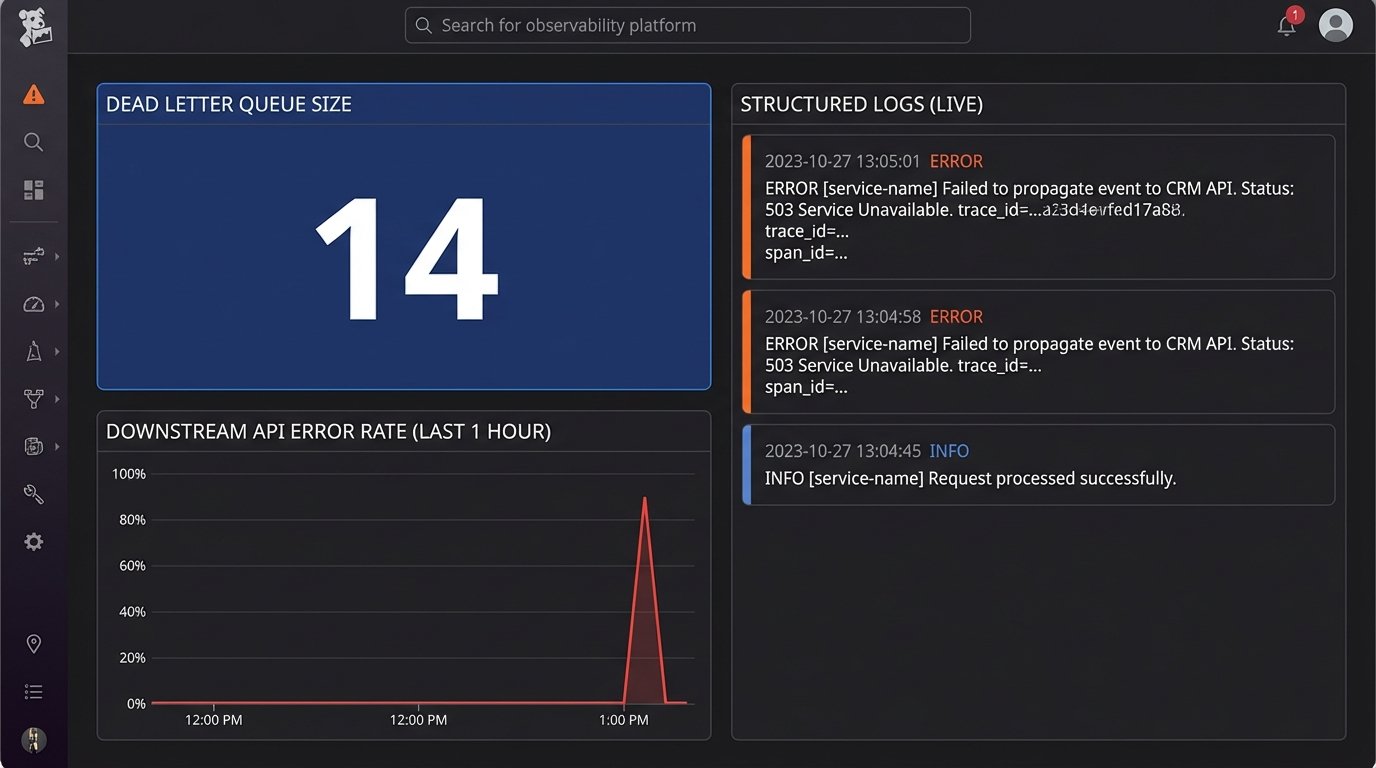
Dead Letter Queues for Failed API Calls
When your service tries to propagate a change to a downstream system and the API call fails, you cannot simply drop the event. The state of your system will diverge from the external systems. The solution is to use a dead letter queue (DLQ).
If an API call to update the CRM fails after several retries, the job is moved to a DLQ. This is a separate queue of failed tasks that an engineer can inspect manually. It preserves the failed operation and its context, preventing data loss and providing a clear audit trail of system failures. This turns a transient network error from a silent data corruption bug into a monitored, fixable problem.
Long-Term Maintenance and System Observability
This integration layer is not a one-time project. It is a piece of critical infrastructure that requires ongoing maintenance. The third-party APIs it depends on will change their authentication methods, update their schemas, and deprecate endpoints. You must have monitoring in place to detect these changes before they cause an outage.
Logging, Monitoring, and Alerting
Your service must produce structured logs for every major action: webhook received, data validated, database write attempted, downstream API call initiated. These logs should be shipped to a centralized logging platform like Datadog or an ELK stack. This is non-negotiable.
You need dashboards that track key metrics like API error rates for each integrated system, the latency of your processing logic, and the size of your dead letter queue. Set up alerts that trigger when any of these metrics exceed a defined threshold. You need to know that the HubSpot API is timing out before your head of sales does.
The Reality of API Versioning
The APIs you integrate with will evolve. A stable integration requires you to pin your code to specific API versions. Check the documentation for each service’s versioning strategy. When they announce a new version, you need a plan to test and migrate your integration. This is a recurring maintenance cost that must be factored into the project.
An automated integration is only reliable if it is actively monitored and maintained. Without observability, you have not fixed the chaos. You have just hidden it inside a black box that will fail at the worst possible moment.