
Most conversations about AI in legal research are superficial. They fixate on generative models that summarize case law, a function that introduces unacceptable risk through hallucination and citation errors. The actual forward movement in 2025 will not be in better summarization engines. It will be in the plumbing underneath: structured data extraction and the construction of relational knowledge graphs from the chaos of unstructured legal text.
Vendors are selling the dream of a conversational oracle. The reality is that we are still fighting a data ingestion and validation war. Any firm that invests heavily in generalized large language models (LLMs) for primary research tasks is building its house on sand. The foundation is, and always will be, clean, structured, and verifiable data.
The Dead End of Generative Summarization
Generative AI, particularly in the form of LLMs, is a pattern-matching machine. It identifies statistical relationships in text to predict the next word. It has no conception of truth, legal precedent, or the consequences of a misquoted statute. Relying on it to synthesize a complex legal argument is an act of professional malpractice waiting to happen.
Retrieval-Augmented Generation (RAG) is the industry’s patch for this fundamental flaw. The model is forced to pull from a trusted corpus of documents, like a firm’s internal case files or a specific legal database, before generating its answer. While this reduces the model’s tendency to invent facts, it does not solve the core problem of interpretation. The model can still misread nuance, conflate separate legal tests, or fail to identify a controlling precedent that is phrased unusually.
It’s a more sophisticated version of a keyword search, but it still lacks true analytical capability.
Hallucination and the Citation Integrity Problem
The models are designed to be helpful, which means they will invent a source if they cannot find one. We have seen this repeatedly in production environments. An LLM tasked with finding support for a specific legal proposition will fabricate case names, create false citations, or attribute a direct quote to the wrong judge. The validation workload to check every single output from one of these systems negates any efficiency gained.
An intern who invents a case citation gets fired. A multi-million dollar software platform that does the same is called innovative. This is a dangerous double standard driven by marketing budgets, not technical reality.
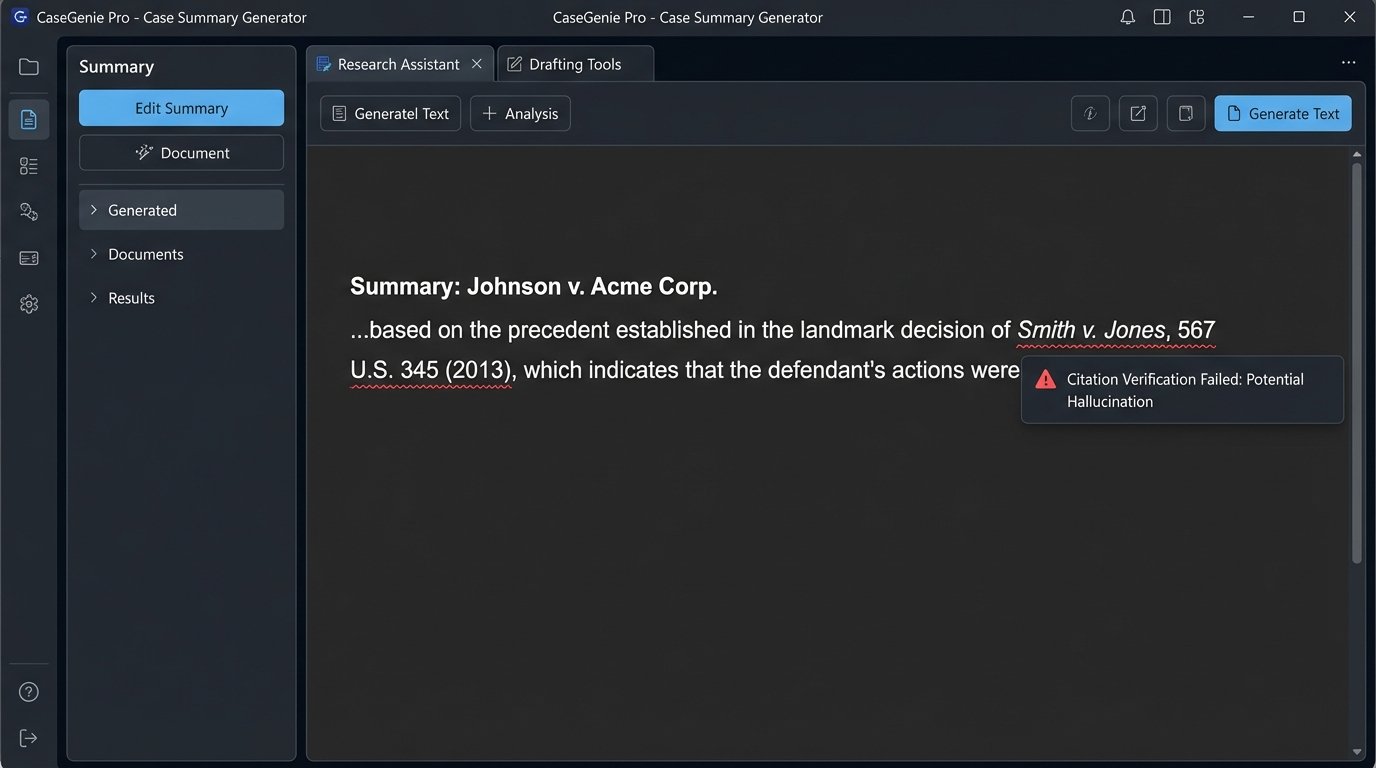
We need to force a shift in thinking away from natural language generation and toward machine-readable data extraction. The goal is not to have an AI write a memo. The goal is to have an AI deconstruct ten thousand documents into a database of facts, rulings, and relationships that a human expert can then analyze with precision.
Structured Data Extraction: The Real Work
The next significant step is not better prose, but better parsing. We are now deploying models fine-tuned for a single, narrow task: identifying and extracting specific entities from legal documents. This is not about understanding the document as a whole. It is about treating it as a container for valuable data points and pulling those points out with surgical accuracy.
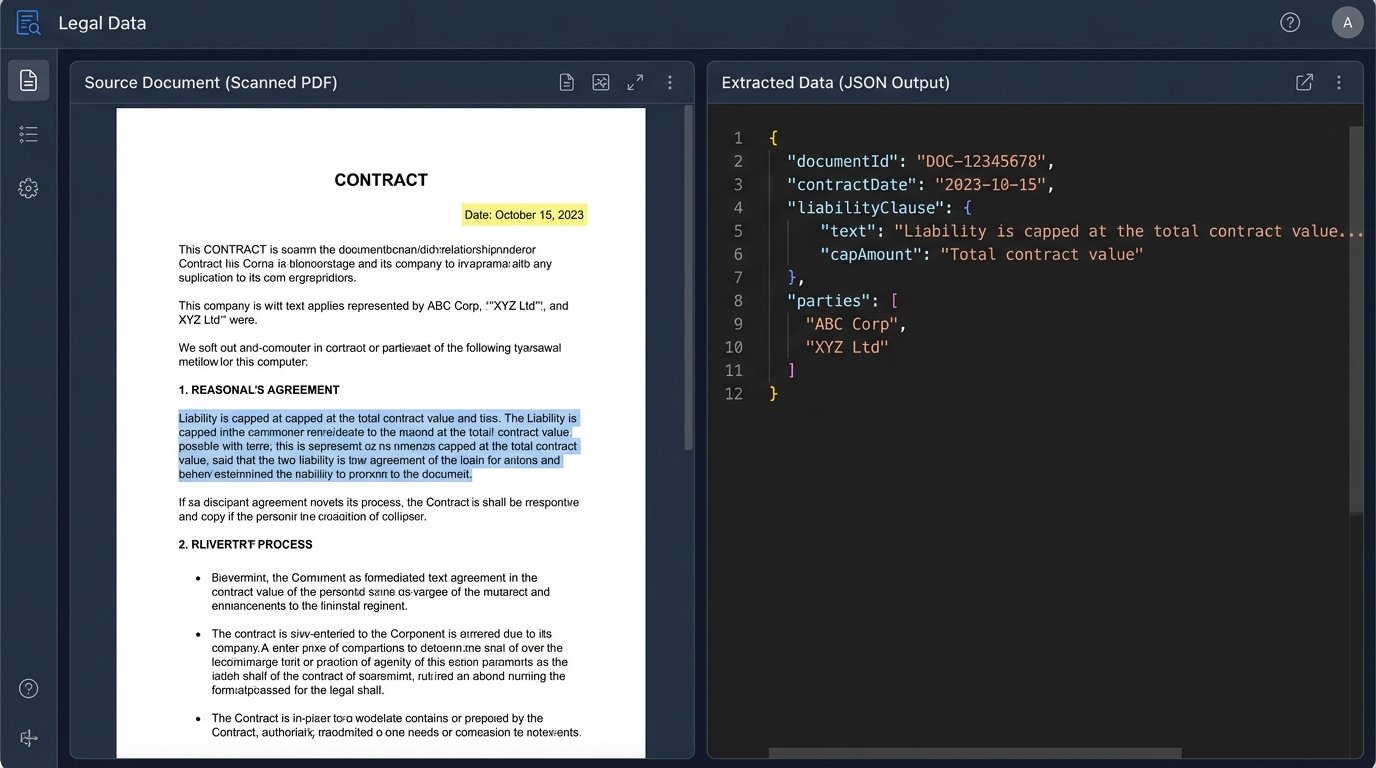
Think of a thousand commercial lease agreements. An LLM might give you a vague summary of common clauses. A specialized extraction model will return a structured JSON object for each lease, containing the exact commencement date, rent escalation percentage, force majeure triggers, and notice periods. This is data you can build on.
This approach converts a mountain of PDFs into a queryable database. That is the actual objective.
Named Entity Recognition (NER) for Legal
Standard NER models are insufficient. They can find people, places, and organizations. We require models trained to identify legal-specific entities: Courts of Jurisdiction, Presiding Judges, Specific Statutes Cited, Monetary Damage Amounts, and Contractual Obligations. Building these fine-tuned models is computationally expensive, but the result is a tool that can process discovery documents at scale and with a high degree of reliability.
Here is a simplified example of what a structured output for a contract clause might look like. This is the format a machine can read and act upon, unlike a prose summary.
{
"document_id": "MSA_2024_ACorp_BCorp.pdf",
"clause_type": "Limitation of Liability",
"clause_text": "In no event shall either party's aggregate liability arising out of or related to this agreement exceed the total amount paid by Customer hereunder in the 12 months preceding the last event giving rise to the liability.",
"entities": [
{
"entity_type": "Liability Cap",
"value": "12 months fees",
"condition": "preceding the event"
},
{
"entity_type": "Liability Scope",
"value": "arising out of or related to this agreement"
}
],
"is_mutual": true,
"confidence_score": 0.97
}
This JSON object is infinitely more valuable than a paragraph of text. You can run analytics on it, trigger alerts, and compare it across a portfolio of thousands of agreements. You cannot do that with a summary.
Trying to build predictive models on raw text from PACER is like trying to build a city’s water system by connecting random garden hoses. You need standardized pipes and junctions, which is what structured extraction provides. Without it, you get leaks, pressure drops, and contaminated results.
Knowledge Graphs: Mapping the Legal Genome
Once you have structured data, the next logical step is to map the relationships between data points. This is where knowledge graphs outperform simple vector databases. A vector database is good for finding documents that are semantically similar. A knowledge graph is built to understand and query the connections between them.
A vector search might find all briefs that mention “summary judgment.” A knowledge graph can answer a query like, “Show me all cases where Judge Smith granted summary judgment in the Northern District of California, where the opposing counsel was from Firm X, and which cited precedent Y.”
This is a multi-hop query that requires understanding the relationships between entities: Judge -> grants -> Motion, Case -> heard_in -> Court, Counsel -> represents -> Party. These relationships are the core of legal analysis.
Constructing the Graph from Extracted Data
The structured JSON outputs from our extraction models become the raw material for the graph. Each entity becomes a node (e.g., ‘Judge Smith’, ‘Firm X’). The context of the document defines the edges, or relationships, between these nodes. Building this graph is a complex ETL (Extract, Transform, Load) process that requires significant domain expertise to define the schema correctly.
The process involves a few key stages:
- Ontology Definition: Defining the types of nodes (Person, Court, Company, Legal Concept) and the types of edges (presided_over, filed_in, cited_by) that will exist in the graph. This is a joint effort between legal experts and data architects.
- Entity Resolution: Deduplicating entities is a critical step. ‘Judge John Smith’, ‘J. Smith’, and ‘John H. Smith’ might all refer to the same person. The system must be able to resolve these to a single canonical node in the graph.
- Relationship Extraction: The system analyzes the co-occurrence and grammatical structure of text around the extracted entities to infer the relationships between them, creating the edges that connect the nodes.
The result is a dynamic, queryable map of your entire legal universe, whether that is your firm’s internal case history or a massive external dataset like court filings. This is the infrastructure required for genuine legal intelligence.
The Integration Nightmare with Legacy Systems
None of this exists in a vacuum. The most advanced AI system is useless if it cannot interface with a firm’s existing Case Management System (CMS), document repository, and billing software. Most of these platforms are monolithic, with poorly documented or non-existent APIs. The integration work is often the most expensive and time-consuming part of any legal automation project.
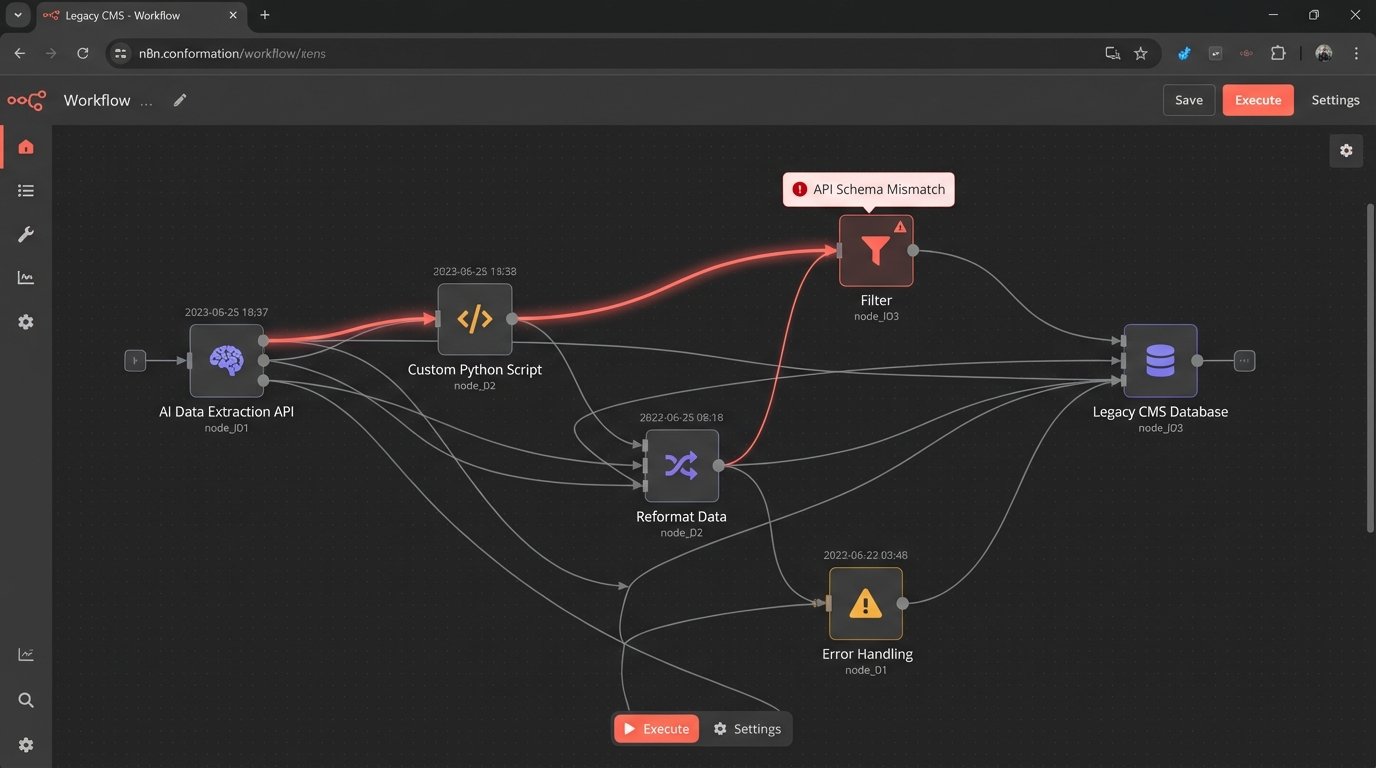
Getting a new extraction model to talk to a ten-year-old CMS often involves building a fragile bridge of custom scripts and middleware. These connections require constant maintenance. An API update on one end can break the entire workflow, and debugging the failure point is a slow, painful process.
Before any firm signs a contract for a new AI tool, they must demand a detailed technical specification of its API endpoints, data export formats, and authentication protocols. If the vendor cannot provide this, walk away. They are selling a closed box, not a tool.
Predictive Analytics Becomes Possible
With structured data populating a knowledge graph, we can finally move past descriptive analytics (what happened) and into predictive analytics (what is likely to happen). We can start to build models that answer high-value questions.
What is the likely duration of a case filed in this court, with this judge, against this opposing counsel? What is the probability that a motion to dismiss will be granted given a specific set of facts? Which clauses in our standard contract template are most frequently litigated?
These are not questions a generative LLM can answer. They require statistical analysis of a large, structured dataset of past outcomes. The AI tools of 2025 that matter will be the ones that build this dataset, not the ones that write poetry about it. The focus must be on creating machine-readable legal data first. Everything else is a distraction.