
Most AI-powered case law research platforms are sold as magic boxes. You type a natural language query, and it spits out a ranked list of authorities. This convenience masks a dangerous reality. The underlying models are often opaque, their training data is a mystery, and their reasoning is a statistical illusion. Relying on them without understanding their mechanical limitations is professional malpractice waiting to happen.
This is not a guide for beginners. This is a manual for operators who need to get under the hood, bypass the friendly UI, and force these systems to deliver verifiable, defensible results. We will tear down the process from query construction to output validation, focusing on the failure points the sales demos conveniently ignore.
Deconstructing the Query Before It Touches the Machine
The system’s output is garbage if your input is imprecise. A conversational query like “Find cases about contract breaches during the pandemic” is an invitation for the model to hallucinate. It will pattern-match on broad concepts, pulling in irrelevant tort cases or tangential statutory analysis. You must first translate the legal question into a set of machine-readable instructions. This is not about keywords. It is about defining the logical boundaries of the search.
Start by extracting the core legal entities. In our example, these are “breach of contract,” “force majeure,” and “impossibility of performance.” Then, define the factual predicates: “pandemic,” “supply chain disruption,” “government shutdown.” Finally, establish the constraints: jurisdiction, court level, and date range. These components are not just words. They are parameters you will inject into the system to narrow its field of vision.
A poorly constructed query forces the AI to guess your intent. A well-structured one eliminates ambiguity and turns the AI from a creative writer into a high-speed clerk.
API Control Versus UI Guardrails
The standard web interface on a research platform is designed for simplicity, which strips away control. It might offer a few filters for date or jurisdiction, but the core search logic is hidden. You have no way to know if it is defaulting to a vector search, how it is weighting terms, or what proximity operators it might be applying automatically. For anything beyond a cursory search, this is unacceptable.
A platform with API access is the only viable option for serious work. The API exposes the machine’s control panel, allowing you to specify every parameter of the search query. You can explicitly disable conceptual searching to force a precise keyword-and-operator search. You can script complex multi-stage queries, where the output of one search becomes the input for the next. This level of control is non-negotiable for complex litigation research.
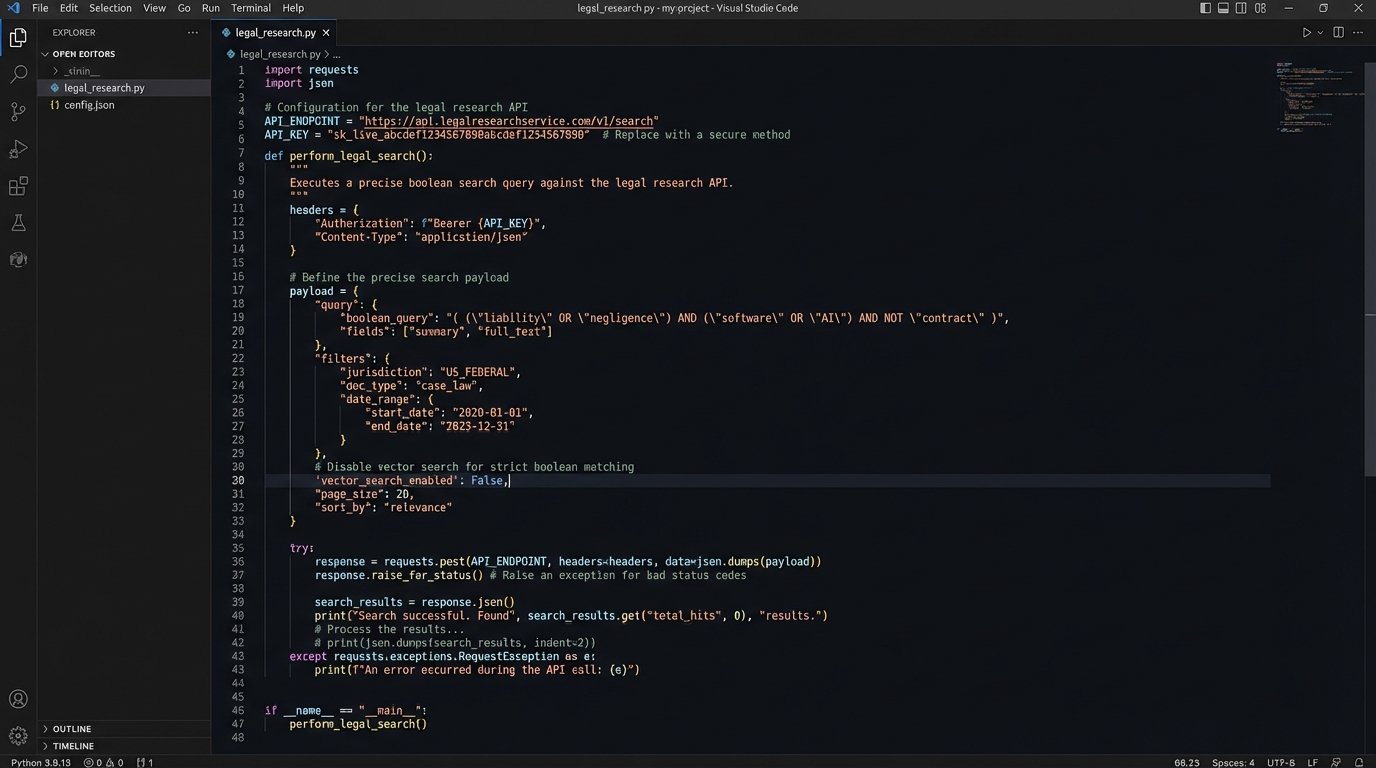
Consider this hypothetical Python script. It bypasses the UI entirely to execute a targeted search against a legal data provider’s API. Notice the explicit controls for jurisdiction, date range, and court level. The key parameter here is “vector_search_enabled”: False. We are deliberately turning off the conceptual “fuzziness” to demand precision. This is the kind of surgical control a web form will never give you.
import requests
import json
# A hypothetical API endpoint for a legal research service
API_ENDPOINT = "https://api.caselaw-provider.com/v2/search"
API_KEY = "YOUR_API_KEY_HERE" # This should be managed as a secret
# Deconstructed legal query into a machine-readable payload
query_payload = {
"boolean_query": "(\"breach of contract\" OR \"contractual nonperformance\") AND (\"force majeure\" OR \"impossibility of performance\") AND (pandemic OR COVID-19)",
"jurisdiction": ["NY", "DE", "CA"],
"date_range": {
"start": "2020-03-01",
"end": "2022-12-31"
},
"court_level": ["appellate", "supreme"],
"vector_search_enabled": False, # Forcing a literal, operator-driven search
"exclude_unpublished": True,
"max_results": 50
}
headers = {
"X-API-Key": API_KEY,
"Content-Type": "application/json"
}
# Execute the API call
response = requests.post(API_ENDPOINT, headers=headers, data=json.dumps(query_payload))
if response.status_code == 200:
results = response.json()
# Logic to parse and validate the returned case list
print(f"Found {len(results.get('cases', []))} matching cases.")
for case in results.get('cases', []):
print(f"- {case['citation']}: {case['case_name']}")
else:
print(f"API call failed. Status: {response.status_code}")
print(f"Error Details: {response.text}")
The difference is stark. The UI asks you to trust the machine. The API lets you command it.
The Vector vs. Keyword Battle
Under the hood, these systems use two fundamentally different methods to find documents: keyword search and vector search. Keyword search is old-school, rigid, and reliable. It finds documents containing the exact strings you specify, governed by Boolean operators like AND, OR, and NOT. It is predictable and transparent. Its weakness is its literalness. It will miss a document that discusses “termination of agreement” if you only search for “breach of contract.”
Vector search operates on conceptual meaning. It converts your query and the entire library of case law into numerical representations (vectors) in a high-dimensional space. The search finds cases whose vectors are “closest” to your query’s vector, even if they do not share any keywords. This is powerful for discovery but also incredibly dangerous. The model’s idea of “conceptually similar” can be bizarre and legally irrelevant, leading you down rabbit holes of useless authority.
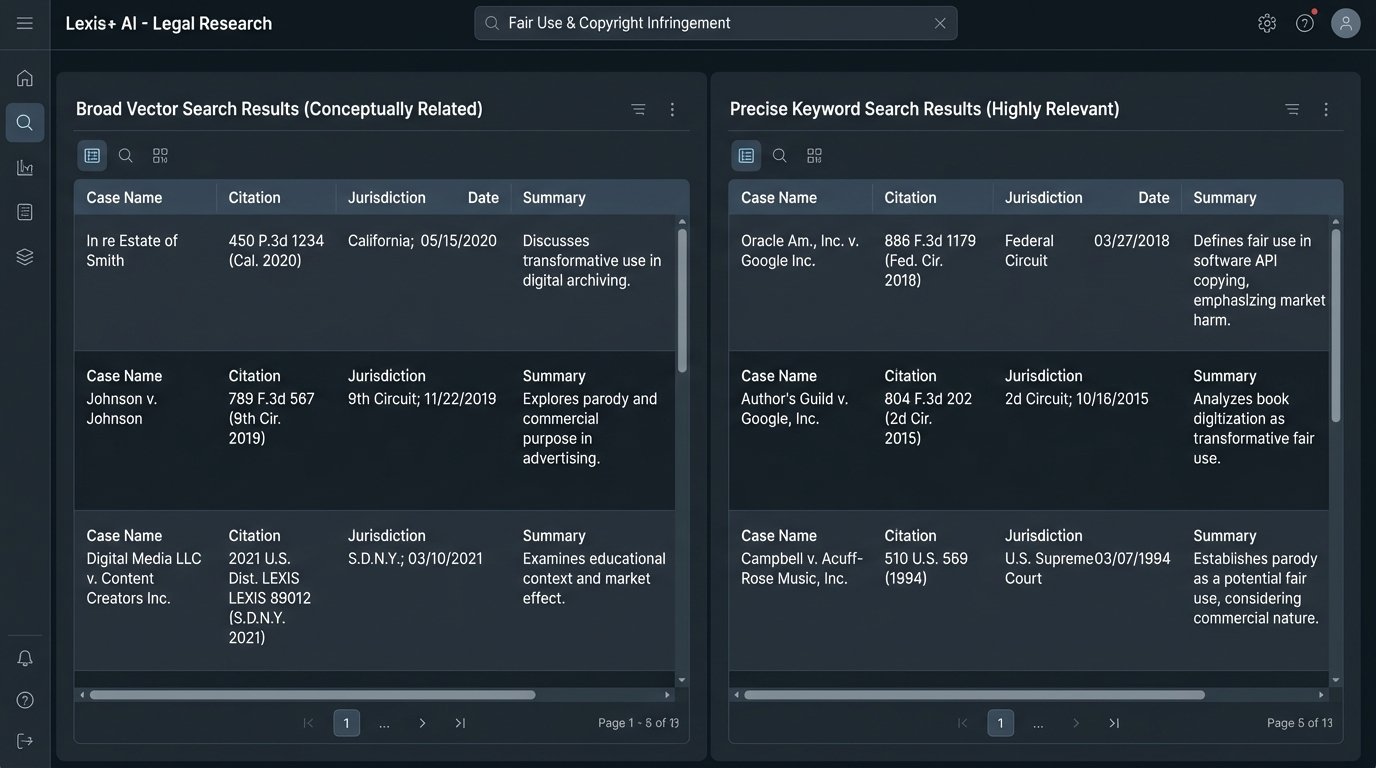
Treating a generative AI’s output like a finished legal brief is like accepting a sealed container from a stranger and shipping it without inspection. You have to x-ray the contents first to verify what is inside. The same principle applies here. Vector search results are leads, not conclusions. They require a secondary, more rigorous validation step to confirm their relevance and authority.
The optimal strategy is a hybrid approach. Use a broad vector search initially to identify the potential universe of relevant cases and key terminology you might have missed. Then, use the insights from that initial pass to construct a precise, operator-driven keyword search to zero in on the most directly applicable authorities. Never trust a pure vector search for the final output.
The Validation Gauntlet: How to Red Team the AI’s Output
The research is not done when the AI returns a list of cases. That is when the real work of validation begins. Do not trust the summaries, the key passages it highlights, or its interpretation of a holding. These are all generated by the model and are susceptible to subtle misinterpretations or outright hallucinations. Every single assertion the AI makes must be independently verified.
Your validation workflow should be systematic.
- Direct Citation Check: Pull the actual document for every top-ranked case. Read the relevant sections yourself. Does the case actually say what the AI summary claims it says? Does the context alter the meaning of the quoted passage?
- Negative Treatment Verification: The AI is often poor at identifying when a case has been overturned, distinguished, or superseded by statute. You must run every promising citation through a traditional citator service like Shepard’s or KeyCite. There is no AI substitute for this. A model trained on a static dataset from last year has no knowledge of a ruling from last week.
- Control Group Comparison: Run a parallel search in a legacy system like Westlaw or Lexis using a carefully constructed Boolean query. Compare the top results from the AI with the top results from the legacy system. If the AI missed a landmark case that your Boolean search found immediately, its relevance ranking algorithm is flawed. If it surfaces cases the legacy system missed, investigate why.
- Jurisdictional Sanity Check: Large language models trained on global internet data can have a weak grasp of jurisdictional hierarchy. Verify that a case from the Ninth Circuit is not being presented as binding authority for a matter in a New York state court. This is a common and basic error for generalist models.
This validation cycle is non-negotiable. It is the human firewall that prevents machine-generated error from becoming a filed legal argument.
Common and Unavoidable Failure Points
Every system has breaking points. Understanding them is key to mitigating risk.
Data Freshness and Corpus Gaps
An AI model’s knowledge is frozen at the time of its last training run. A platform that updates its model quarterly is three months out of date on its best day. This makes it useless for tracking recent developments or emerging areas of law. Always verify the “knowledge cutoff date” for the model you are using. Furthermore, question the corpus itself. Does it include unpublished opinions? Does it have comprehensive coverage of state trial court orders? Any gaps in the training data are blind spots in the final product.
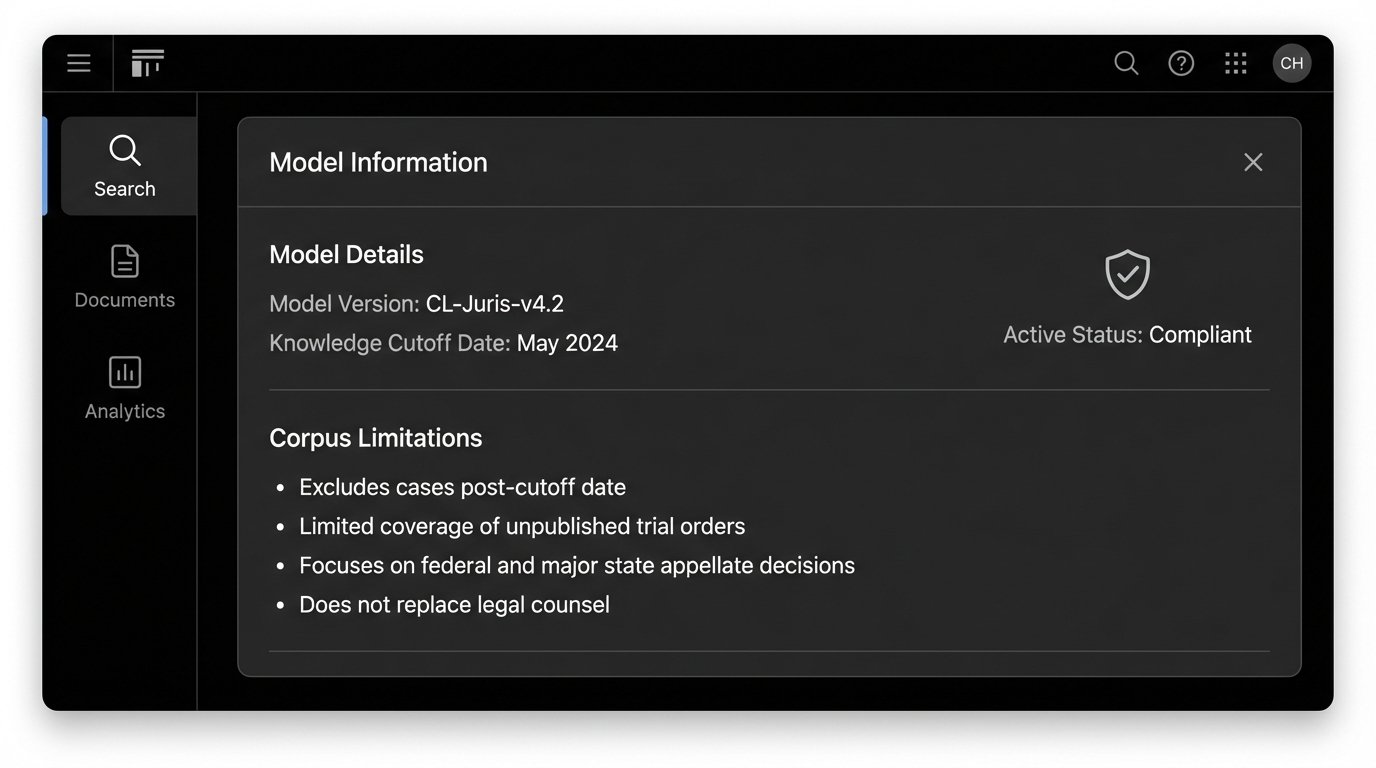
Model Drift and Performance Degradation
AI models are not static. Their performance can degrade over time as new data is introduced or as the underlying software is tweaked. A query that produced excellent results six months ago might return garbage today. This phenomenon, known as model drift, is rarely disclosed by vendors. The only defense is constant testing and running benchmark queries periodically to ensure the quality of the output remains consistent.
The Black Box Problem
Finally, there is the fundamental problem of transparency. Most commercial legal AI platforms will not disclose their model architecture, their full training dataset, or their relevance ranking algorithms. They brand it as proprietary IP. This forces you to trust a system you cannot inspect. This is a business risk. If a tool’s reasoning is a black box, its output cannot be fully trusted for high-stakes legal work. Demand transparency from your vendors. If they refuse, find one that will.
Adopting these tools is not about replacing lawyers. It is about equipping them with powerful, and potentially flawed, instruments. The goal is not to trust the AI’s answer, but to use the AI to find potential answers more quickly, which you then subject to the same rigorous, skeptical analysis you would apply to the work of a junior associate.