
Most AI legal research tools are marketed as magic wands. They are not. They are statistical models trained on massive, often unverified, text corpora. Their output is a probability distribution, not a statement of fact. Forgetting this distinction is the fastest path to a malpractice suit. The core engineering challenge isn’t finding the right tool, it’s building a validation framework around a tool that is designed to be confidently wrong.
The entire system rests on a simple premise. You convert a complex legal query into a vector, a string of numbers representing its semantic meaning. The tool then scours its pre-indexed vector database of case law to find documents with the closest numerical representation. It’s just math, not legal reasoning. The quality of the result is entirely dependent on the quality of the initial vectorization and the cleanliness of the source data.
This is not a substitute for an experienced paralegal. It’s a force multiplier for one who knows how to spot a fabricated citation from a mile away.
Deconstructing the AI: Vector Search vs. Glorified Keywords
The first step is to gut the marketing language from any potential vendor. Ask for API documentation, not a demo. If a tool cannot differentiate between a query about “contractual breaches in maritime law” and one about “ships breaking agreements,” it is likely using a legacy keyword or TF-IDF model with an AI label slapped on top. A true semantic search engine understands the intent behind the query, not just the words used.
A proper system uses a transformer-based language model, often a fine-tuned version of something like BERT or a proprietary equivalent, to generate these vectors. This process happens upfront, during indexing. Every document, every paragraph, every case in the database is converted into a numerical vector and stored. Your query undergoes the same transformation at runtime. The search is then a high-speed nearest-neighbor lookup in a multi-dimensional space.
This is computationally expensive and is why these services are wallet-drainers. You are paying for the immense processing power required to index terabytes of legal text and serve queries in milliseconds.
API Access is Non-Negotiable
A slick user interface is a trap. It locks you into the vendor’s workflow and prevents any meaningful integration. Direct API access is the only way to chain these tools into your existing case management systems or build custom validation logic. Without it, you are stuck with a glorified search box that forces your attorneys to copy and paste text like it’s 1999.
You need endpoints for search, document retrieval, and ideally, summarization. The API response should be structured, predictable JSON, not a blob of HTML. Clean data is workable data.
Initial Configuration and API Interaction
Connecting to a legal AI API is functionally no different from connecting to any other web service. It’s a series of HTTP requests that require an authentication key. The complexity comes from structuring the query payload correctly and parsing the nested JSON response. The vendor’s documentation is your primary guide, assuming it wasn’t written five years ago and forgotten.
Your initial script should perform the most basic function: take a natural language query, send it to the search endpoint, and print the raw response. This confirms your credentials are valid and that you can reach the server. Do not build anything more complex until this basic connection is stable.
A Basic Python Query Example
Here is a stripped-down example using Python’s `requests` library to hit a hypothetical `/search` endpoint. This is the first block of any integration. It proves the pipe works before you try to pump anything meaningful through it.
import requests
import json
API_KEY = "your_secret_api_key_here"
API_ENDPOINT = "https://api.legalsearch.ai/v1/search"
QUERY = "What constitutes 'reasonable accommodation' under the ADA for remote work?"
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
payload = {
"query": QUERY,
"jurisdiction": "federal",
"max_results": 5,
"include_summary": True
}
try:
response = requests.post(API_ENDPOINT, headers=headers, json=payload)
response.raise_for_status() # This will raise an exception for HTTP error codes
results = response.json()
print(json.dumps(results, indent=2))
except requests.exceptions.HTTPError as errh:
print(f"Http Error: {errh}")
except requests.exceptions.ConnectionError as errc:
print(f"Error Connecting: {errc}")
except requests.exceptions.Timeout as errt:
print(f"Timeout Error: {errt}")
except requests.exceptions.RequestException as err:
print(f"Something Else Went Wrong: {err}")
This code does one thing. It sends a question and waits for an answer. The real work begins when you have to parse the `results` object, which is often a convoluted mess of nested dictionaries and lists.
The Hallucination Problem: Mandating a Validation Layer
The single greatest operational risk of these systems is their tendency to “hallucinate.” An LLM, when it cannot find a statistically probable answer in its training data, will invent one. It will generate entirely fictional case names, citations, and legal precedents with absolute confidence. An attorney relying on this output without verification is committing professional negligence.
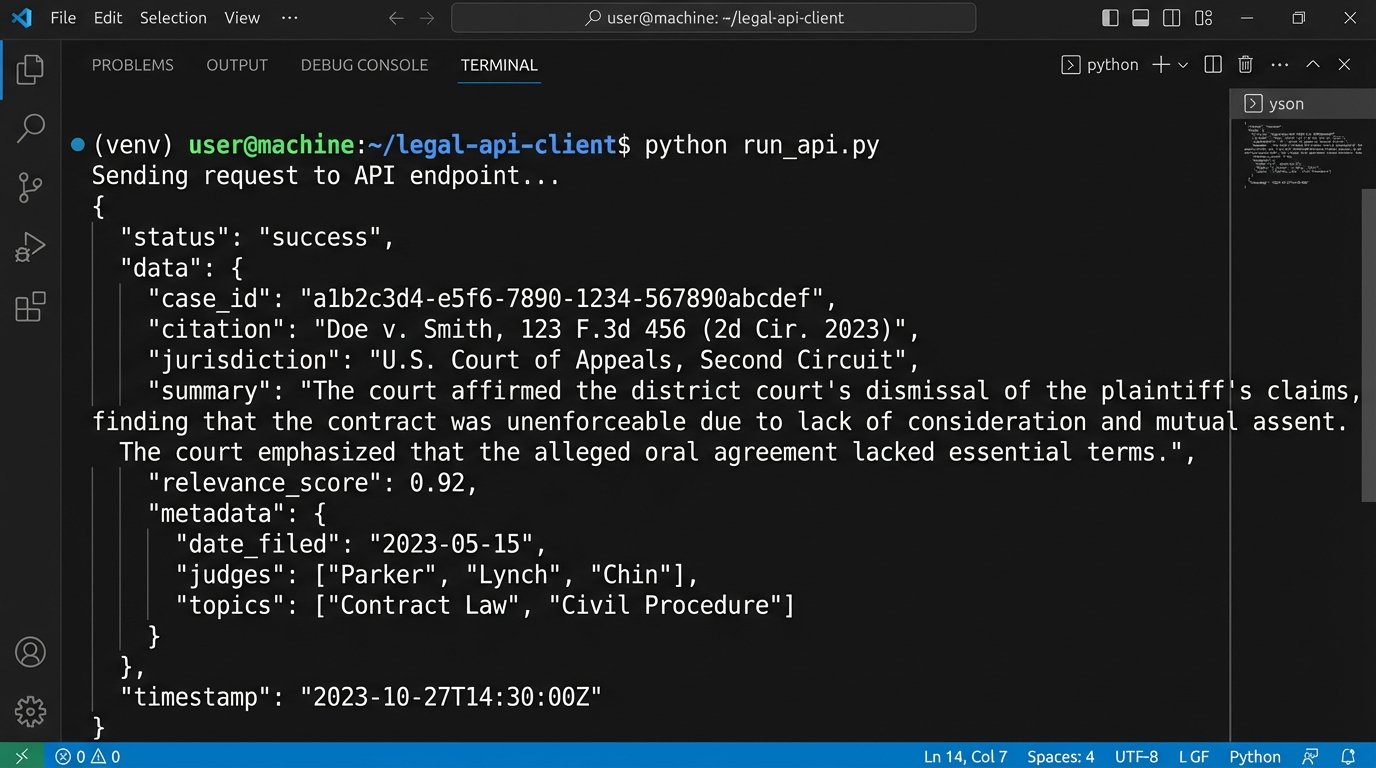
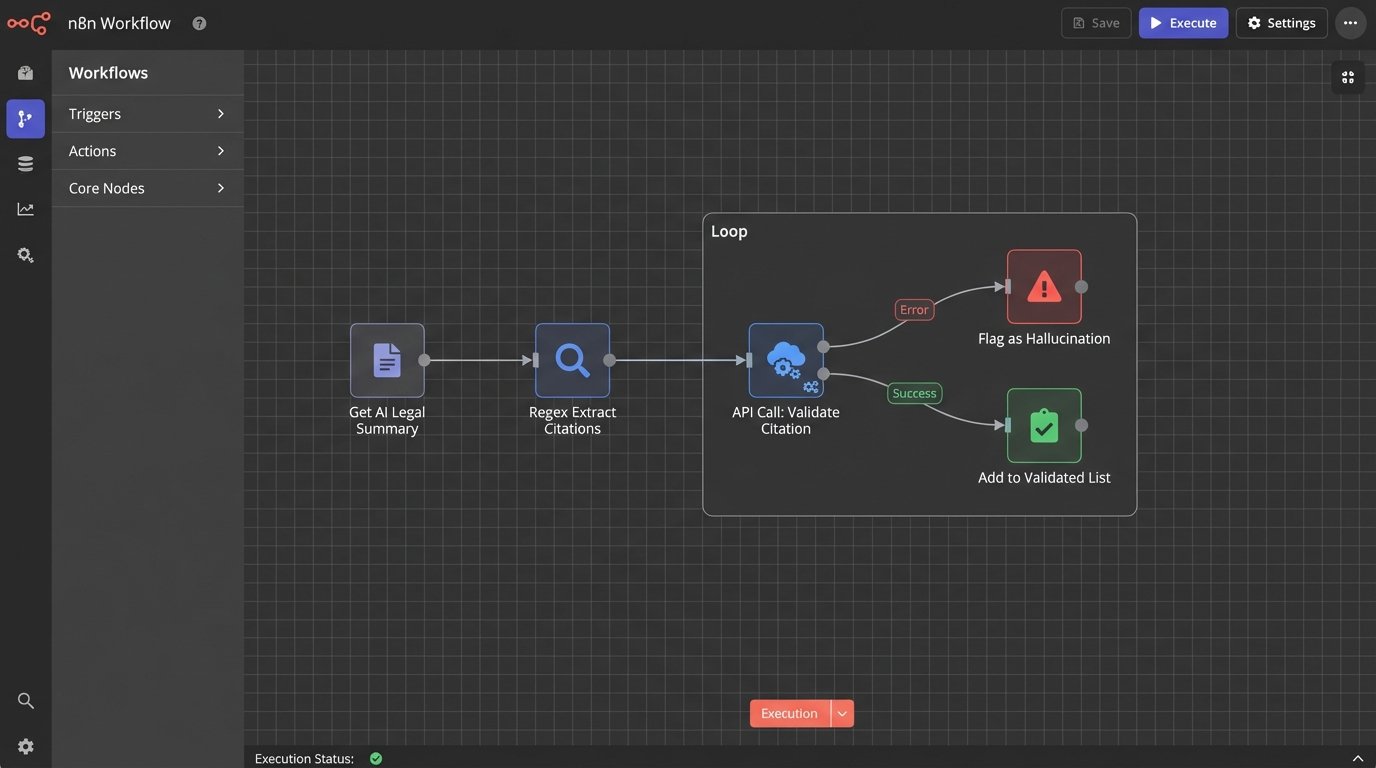
You cannot fix this at the model level. It is an inherent property of how LLMs function. You must fix it at the workflow level by building a mandatory, automated validation layer. This is not optional. It is the core of a responsible AI implementation.
The logic is straightforward. After receiving a response from the AI research tool, your system must automatically parse the text to extract every legal citation. Each extracted citation is then checked against a trusted, canonical source. This could be the API for Westlaw, LexisNexis, or a public repository like the Harvard Law School Caselaw Access Project. If the citation does not exist in the trusted source, it is flagged as a potential hallucination and stripped from the results shown to the end-user.
Building the Citation Extractor and Validator
Regular expressions are a crude but effective tool for pulling standard citation formats out of a block of text. You need to account for different reporter formats and court styles. A simple regex might look for a volume number, the reporter abbreviation, and a page number.
Here’s a basic function to extract citations matching a pattern like “123 F.3d 456”.
import re
def extract_citations(text_block):
# This is a simplified regex and should be expanded for production use
# to cover various reporter formats (U.S., S. Ct., etc.)
pattern = r'\b(\d+)\s+([A-Z][\.A-Za-z\d\s]+)\s+(\d+)\b'
found_citations = re.findall(pattern, text_block)
# Reformat for easier use, e.g., "123 F.3d 456"
formatted_citations = [f"{vol} {reporter.strip()} {page}" for vol, reporter, page in found_citations]
return formatted_citations
# Example usage:
ai_response_summary = """
The court in Smith v. Jones, 123 F.3d 456, established the precedent.
This was later challenged in Doe v. Roe, 456 U.S. 789. However, the
fictional case of Beta v. Alpha, 987 F.Supp.2d 654, is not a real case.
"""
citations = extract_citations(ai_response_summary)
print(citations)
# Expected output: ['123 F.3d 456', '456 U.S. 789', '987 F.Supp.2d 654']
Once you have this list, you loop through it, making an API call for each citation to your validation source. The response will be either the case data or a “not found” error. Any citation that returns an error gets flagged. This process introduces latency and additional cost, but it’s the only way to build a trustworthy system.
This is a brutal logic check. There is no middle ground.
Advanced Integration: From Raw Data to Case Management
Getting a validated list of relevant cases is only half the battle. The data is useless until it’s injected into the workflow of your legal teams. This means mapping the JSON output from the AI service to the specific fields in your firm’s Case Management System (CMS) or document management platform. This is a classic Extract, Transform, Load (ETL) problem.
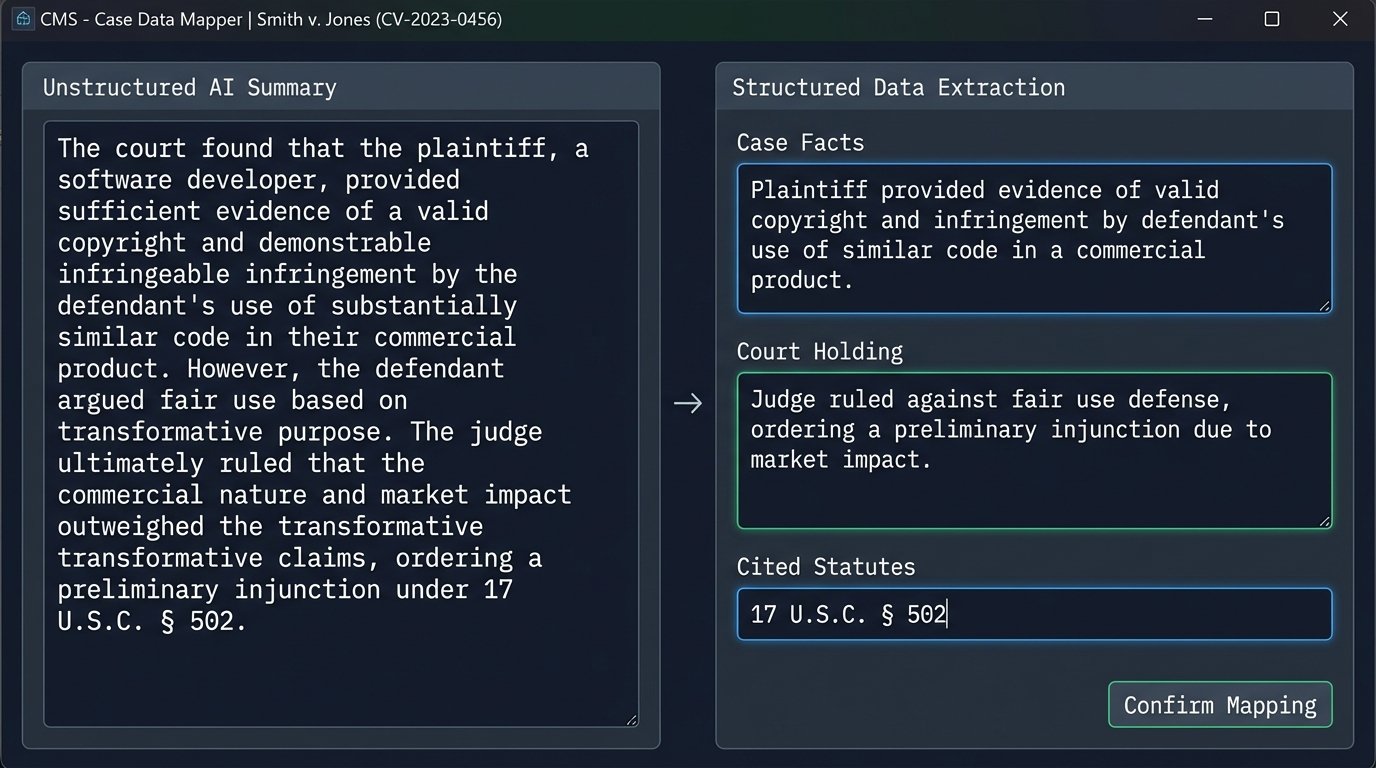
The transform stage is the most difficult. The AI will provide a case summary as a single, unstructured block of text. Your CMS, however, likely has discrete fields for “Facts,” “Holding,” “Legal Reasoning,” and “Disposition.” You cannot simply dump the AI summary into one of these fields. This requires a second AI call, a “re-parsing” step. You feed the summary to a powerful instruction-following model (like GPT-4) with a specific prompt.
Your prompt engineering becomes critical here. You must instruct the model to act as a paralegal, read the provided text, and return a JSON object with keys that exactly match your CMS schema. Trying to map a free-form LLM text block to a rigid SQL database schema is like trying to park a bus in a motorcycle spot. You have to chop it up first.
Structuring the Re-Parsing Prompt
A prompt for this task is not a simple question. It is a set of explicit instructions and constraints. You provide the raw text and specify the exact output format you require.
- Role: “You are an expert legal analyst.”
- Input: “Here is the summary of a legal case: {ai_summary_text}”
- Task: “Extract the key facts, the court’s final holding, and the primary legal statutes cited.”
- Format: “Return your response ONLY as a JSON object with the following keys: ‘caseFacts’, ‘courtHolding’, ‘citedStatutes’. The value for ‘citedStatutes’ must be a list of strings.”
This forces the model to structure its output, making the final mapping to your database a simple key-to-field operation. This adds another layer of API calls and potential failure points, but it is the only way to automate the data-entry part of the process.
Failure to do this results in attorneys having to manually dissect and categorize the AI’s output, defeating the entire purpose of the automation.
Final Logic Check: An Augment, Not an Oracle
The objective of this entire architecture is to reduce the time spent on the mechanical aspects of legal research. It’s about rapidly identifying a pool of potentially relevant cases and pre-processing them for human review. It does not, and cannot, replace expert analysis. The AI is a powerful tool for query expansion and summarization, but it has no understanding of legal strategy or nuance.
Over-reliance on these systems without a robust validation and integration framework is a critical mistake. The models will drift, the APIs will change, and the costs will fluctuate. Constant monitoring and a healthy dose of professional skepticism are required. Trust the process you build, not the black box you rent.