
Most AI legal research platforms are just slick user interfaces wrapped around a generic large language model. They sell you on speed but hide the liability. The core engineering problem isn’t finding a tool that can summarize case law. The problem is building a validation framework that prevents a hallucinated citation from ending up in a federal court filing and getting you sanctioned. This isn’t about picking software. It’s about architecting a defensible workflow.
Before You Buy: Map Your Data and Define the Kill-Switch
The first meeting you should have about AI research tools isn’t a sales demo. It’s a data governance meeting with your InfoSec and compliance teams. You must determine exactly what class of information will be injected into these third-party systems. Is it client-confidential data? Is it subject to GDPR or other jurisdictional data residency rules? Most vendors will give you vague assurances about security, but you need to force them to provide specifics on their data handling policies, sub-processors, and whether your queries are used to train their models.
This process results in a simple, binary data classification policy. You need a hard rule that dictates what can and cannot be used as a prompt. For instance, specific client names, internal strategy memos, or unannounced M&A details should be on a permanent kill-list. Any engineer building an integration or any lawyer using the web UI must be trained on this boundary. The best AI tool is a brick if your CISO blocks its IP range on day two because of a data leak.
Platform Selection: Beyond the UI and Into the API
The web interface is a sales tool. The API is the engine. When vetting platforms, your primary focus should be on the programmatic access they provide, because that is how you will build scalable, repeatable, and verifiable workflows. A pretty dashboard that cannot be integrated into your existing systems is a dead end. Demand API documentation and a sandbox key before you sign any contract.
Criterion 1: Model Provenance and Fine-Tuning
You must ask vendors a direct question: “What is your base model, and on what specific corpus was it fine-tuned?” A platform built on a generic public model like GPT-4 will have broad knowledge but no specialized legal nuance. It is more prone to generating plausible but incorrect legal arguments. A superior platform will use a model that has been specifically and continuously fine-tuned on a curated corpus of case law, statutes, and secondary sources. If they can’t answer this question with specifics, they are likely just reselling a public API with a custom front-end.
The vendor’s answer tells you everything about their commitment to the legal domain versus just riding a technology trend.
Criterion 2: The API – Latency and Rate Limiting
An API that is slow or has draconian rate limits is a production bottleneck waiting to happen. Before committing, you need to benchmark it. Run a test script that sends a hundred different queries of varying complexity and measure the P95 latency. How long does it take to get a response for a simple citation check versus a complex multi-jurisdictional query? Check the rate limits. Can you run batch jobs to analyze an entire portfolio of cases overnight, or are you limited to a few queries per minute? These technical constraints will dictate how you can architect your automation. A sluggish API forces you into asynchronous job queues, adding complexity to your stack.
Criterion 3: Citation Integrity and Hallucination Mitigation
This is the single most important technical test. You have to actively try to make the tool lie. Feed it prompts with fake case names, subtly incorrect legal concepts, or ask it for precedents in nonsensical jurisdictions. A well-architected system should respond with an error, a clarification, or a statement of its limitations. A poorly designed system will hallucinate an answer, inventing case law to satisfy the prompt. The gold standard is a system that not only provides a summary but also links every single assertion back to a specific document, paragraph, or page number in its source material. This citation mapping is non-negotiable. Without it, you are just using a high-tech magic 8-ball.
Building the Validation Loop: Never Trust, Always Verify
An AI’s output is not a legal opinion. It is a statistically generated draft, a starting point for analysis. Accepting its output without independent verification is professional malpractice. Your firm must implement a mandatory human-in-the-loop protocol for every piece of AI-generated legal analysis that might be used in actual work product. The workflow is rigid: AI Generation leads to Expert Human Review which then requires Traditional Cross-Referencing.
The primary risk here is confirmation bias. An AI can produce an articulate, well-structured, and convincing argument that is completely wrong. A time-pressed associate might see the plausible answer they were hoping for and accept it without digging deeper. The validation workflow is a firebreak against this bias. It forces a secondary check using a completely different system, like your legacy Westlaw or LexisNexis subscription. Treating a raw AI output as fact is like pushing a developer’s first-pass code directly to production without a single unit test. It will eventually explode, and you’ll be the one cleaning up the mess at 3 AM.
Technical Verification: A Simple API Cross-Check
You can enforce this “trust but verify” model programmatically. Assume your AI research tool returns a structured JSON response containing its summary and a list of case citations. You can write a simple script to parse this output, extract the citations, and then automatically run a check against a trusted, independent legal data provider to confirm their existence and validity. This doesn’t replace human review, but it does automate the first layer of defense against blatant hallucinations.
Consider a scenario where the AI tool returns the following JSON after a query:
{
"query_id": "q-1a2b3c",
"summary": "The court found that the 'essential facilities' doctrine applies when a dominant firm controls a resource necessary for competition.",
"citations": [
{
"case_name": "MCI Communications Corp. v. AT&T Co.",
"citation_id": "708 F.2d 1081",
"relevance_score": 0.92
},
{
"case_name": "Fictional Case v. Imaginary Corp.",
"citation_id": "999 F.Supp.2d 123",
"relevance_score": 0.88
}
]
}
Our goal is to check if “999 F.Supp.2d 123” is a real case. We can write a Python script to hit an external verification service, like the CourtListener API, to do a quick sanity check.
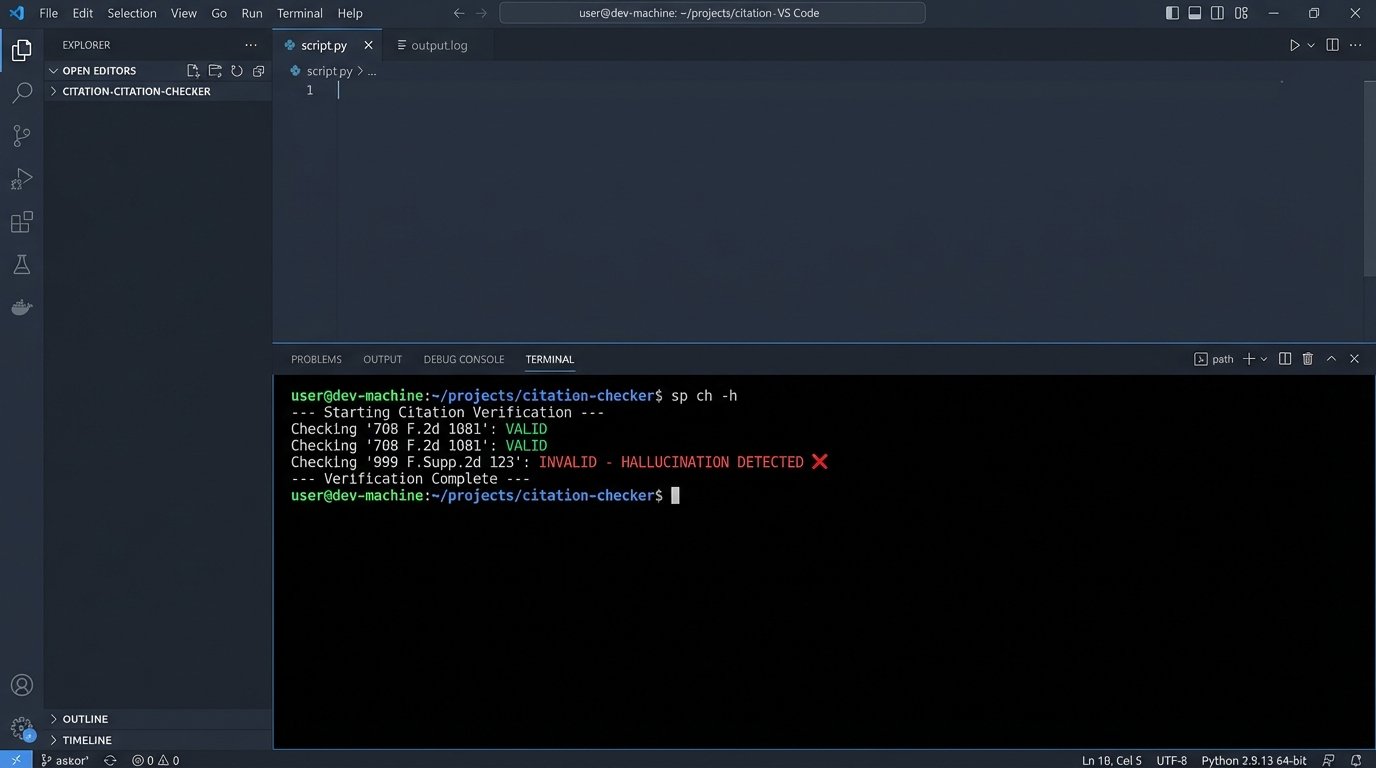
Here is a simplified Python script that demonstrates the logic. It parses the JSON, iterates through the citations, and makes a request to a hypothetical verification API endpoint.
import requests
import json
# Assume 'ai_response_json' is the JSON string from our AI tool
ai_response_json = """
{
"query_id": "q-1a2b3c",
"summary": "The court found that the 'essential facilities' doctrine applies...",
"citations": [
{"case_name": "MCI Communications Corp. v. AT&T Co.", "citation_id": "708 F.2d 1081"},
{"case_name": "Fictional Case v. Imaginary Corp.", "citation_id": "999 F.Supp.2d 123"}
]
}
"""
# The endpoint for our trusted, independent verification service
VERIFICATION_API_ENDPOINT = "https://api.trustedcourtdb.com/v1/citations/check"
API_KEY = "your_secret_api_key_here" # Never hardcode keys in production
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
def verify_citations(ai_response):
"""
Parses AI response and verifies each citation against an external API.
"""
try:
data = json.loads(ai_response)
citations_to_check = data.get("citations", [])
if not citations_to_check:
print("No citations found in the AI response.")
return
print("--- Starting Citation Verification ---")
for citation in citations_to_check:
citation_id = citation.get("citation_id")
if not citation_id:
continue
payload = {"citation": citation_id}
try:
response = requests.post(VERIFICATION_API_ENDPOINT, headers=headers, json=payload, timeout=10)
response.raise_for_status() # Raise an exception for bad status codes (4xx or 5xx)
result = response.json()
is_valid = result.get("isValid", False)
status = "VALID" if is_valid else "INVALID - HALLUCINATION DETECTED"
print(f"Checking '{citation_id}': {status}")
except requests.exceptions.RequestException as e:
print(f"Error checking '{citation_id}': API call failed - {e}")
print("--- Verification Complete ---")
except json.JSONDecodeError:
print("Error: Failed to decode AI response JSON.")
# Run the verification process
verify_citations(ai_response_json)
This script isn’t a silver bullet, but it’s a functional backstop. It automates the tedious first pass of verification and flags obvious fabrications before a human even sees them. Integrating this kind of logic-check directly into your workflow is a critical piece of engineering discipline.
Bridging to Legacy: The Unsexy Reality of Integration
A new AI tool doesn’t exist in a vacuum. It has to connect to your existing systems, most of which are probably monolithic, decade-old case management platforms with brittle, poorly documented APIs. The data formats will almost certainly be incompatible. Your shiny new AI tool will output clean, structured JSON, while your legacy CMS will only accept a convoluted XML schema defined in 2008.
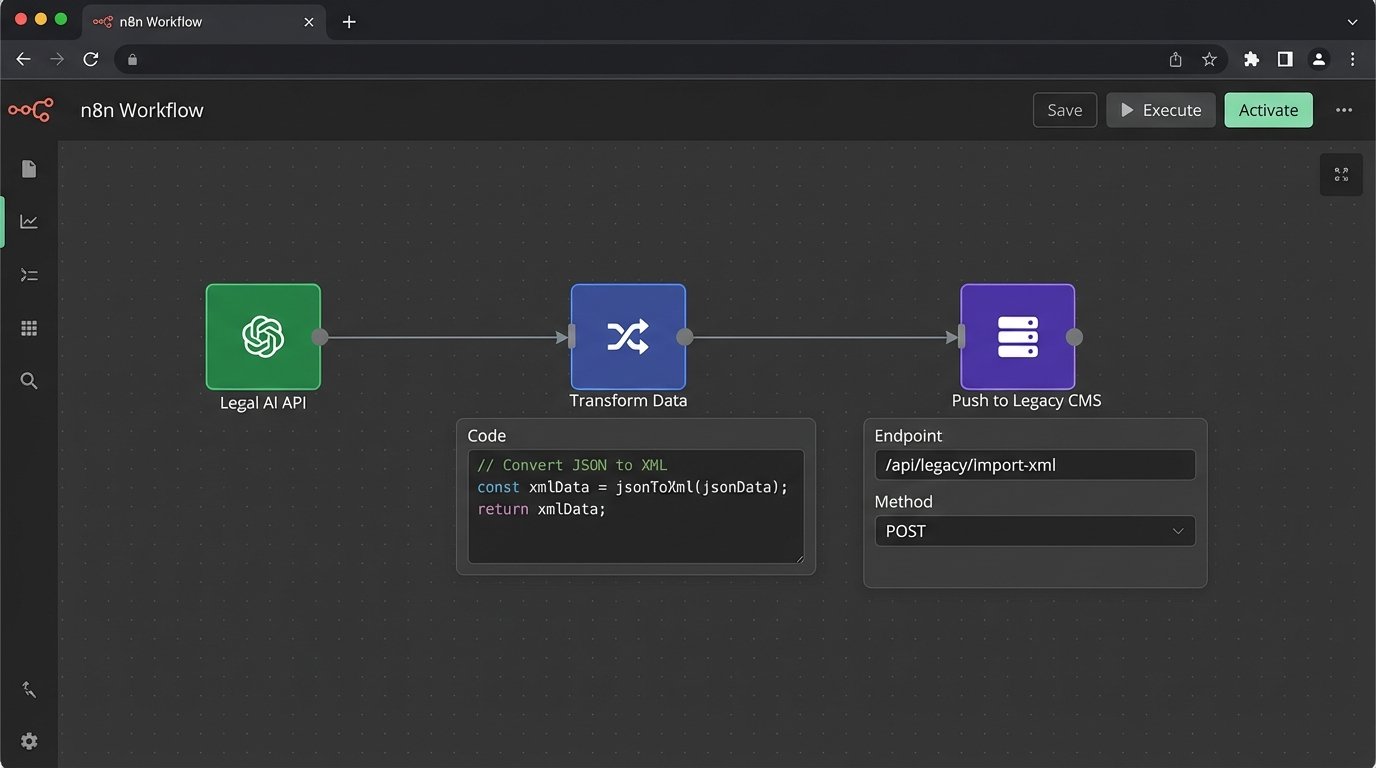
The solution is almost always a piece of custom middleware. This can be a small Python Flask app, a serverless function, or a dedicated integration platform service. Its sole job is to act as a translator. It ingests the JSON from the AI tool’s API, transforms the data into the required XML format, and then pushes it into the legacy system’s endpoint. This is not glamorous work. It’s the plumbing that makes the whole system functional. Expect to spend more time debugging the connection to your old system than you do working with the new AI.
These AI research tools are powerful statistical engines, not oracles. They generate probabilities, not truths. The real engineering task is not just to operate the tool, but to build the operational guardrails, the validation logic, and the integration bridges that make its output reliable and safe to use in a high-stakes legal environment. The first law firm to be publicly sanctioned for citing a hallucinated case will create a powerful lesson for everyone else. Your job is to architect a system that ensures it isn’t your firm.