
The marketing departments of legal tech vendors want you to believe their AI is a thinking machine. It is not. It is a statistical engine that got very good at predicting the next word in a sequence, trained on a scraped copy of the internet and whatever legal corpora they could get their hands on. This process has no understanding of legislative intent, jurisdictional nuance, or the simple fact that a statute from 1982 might have been implicitly gutted by a series of appellate court decisions.
Accepting this reality is the first step. The AI is a brute-force instrument, a power tool for pattern matching at a scale no human team could replicate. The human lawyer is the strategist who interprets the output, identifies the subtle contradictions the machine missed, and applies the findings to a client’s actual problem. The showdown isn’t about replacement. It’s about defining a new, hybrid workflow where the machine does the grunt work of data retrieval and the human performs the high-value cognitive labor of legal reasoning.
Deconstructing the AI Query Pipeline
When an attorney types a natural language query into an AI research platform, what’s happening is not magic. The system first converts the query into a high-dimensional vector, a mathematical representation of its semantic meaning. It then runs a similarity search against a pre-indexed library of statutes, case law, and regulations that have also been converted into vectors. The platform returns the documents whose vectors are closest to the query vector in that multi-dimensional space. It’s a geometry problem, not a legal one.
The quality of this process is entirely dependent on the quality of the data ingestion pipeline. This is where most failures begin. Statutes are often locked in poorly formatted PDFs or archaic government websites. The optical character recognition (OCR) and parsing scripts used to strip this text are imperfect. They introduce errors, misinterpret section breaks, or fail to link a statute to its subsequent amendments. The AI then trains on this broken data, baking the errors directly into its model. The result is an answer that looks correct but might reference a subsection that the parser mangled.
A traditional Boolean search is explicit. You search for `(term A OR term B) AND “exact phrase C”`. You control the logic. An AI query is an abstraction. A simplified representation of what happens under the hood might look something like this in pseudo-code:
function get_relevant_statutes(natural_language_query, jurisdiction_filter):
query_vector = model.generate_embedding(natural_language_query)
candidate_docs = vector_db.find_similar(query_vector, limit=100)
filtered_docs = []
for doc in candidate_docs:
if doc.metadata['jurisdiction'] == jurisdiction_filter:
filtered_docs.append(doc)
# Re-rank based on secondary model or metadata like citation count
reranked_docs = reranker_model.process(filtered_docs, natural_language_query)
return reranked_docs[:10]
The system is making its own best guess about relevance. It gives you a plausible answer, but it hides the direct logical path from your query to the result. This is a problem when you need to defend your research methodology.
The False Promise of Pure Speed
The primary selling point for AI research is speed. It can scan the entire United States Code for concepts related to “data breach notification requirements for financial institutions” in seconds. A human doing that manually would take days and likely miss several key provisions. In this specific task, mass data identification across a huge corpus, the machine wins. It’s not even a contest.
This speed becomes a liability when precision is required. The AI is great at finding statutes. It is terrible at understanding the relationships between them. It might find a state-level privacy law but fail to flag a recently passed federal statute that preempts it. It might pull up a regulation but miss the administrative guidance document that completely changes its enforcement. The system returns a flat list of text snippets ranked by statistical relevance, stripped of the critical legal hierarchy that gives them meaning.
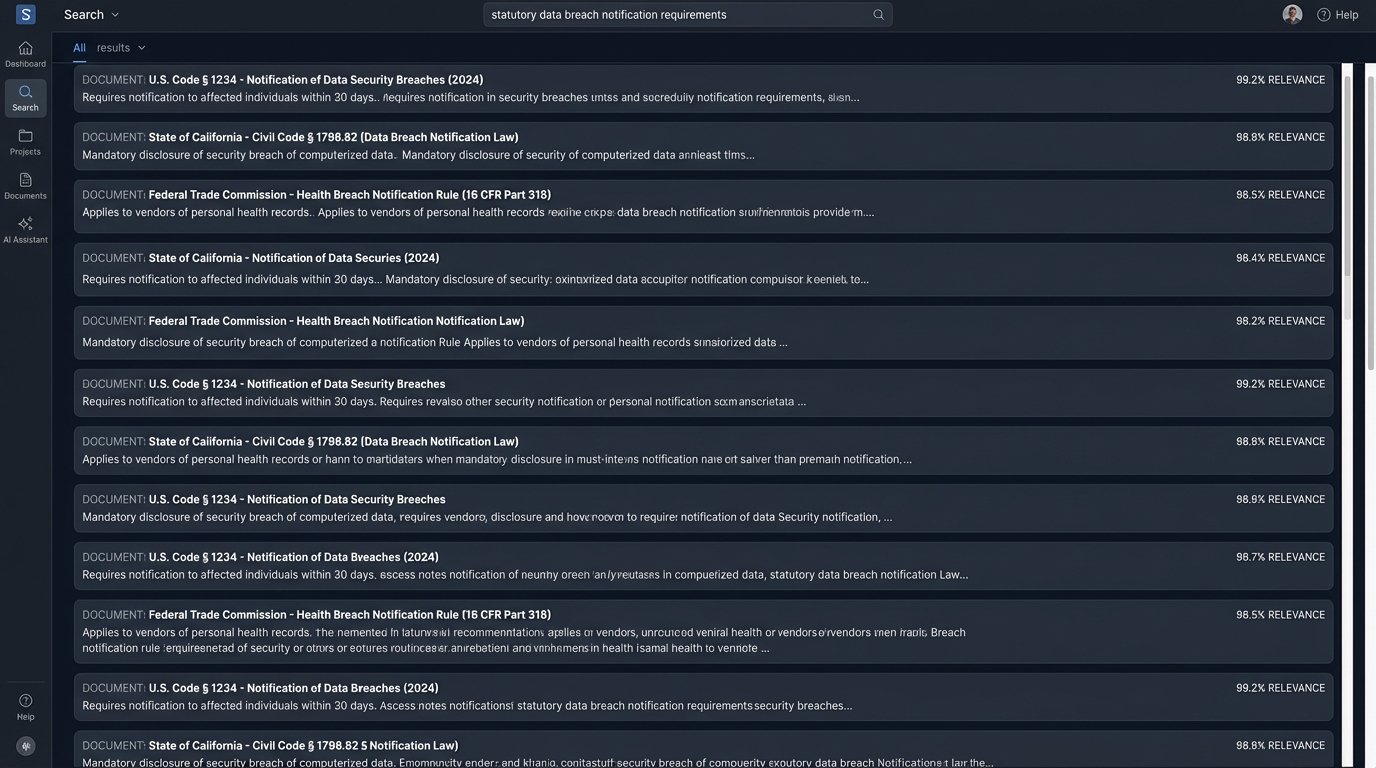
This is the core disconnect. The AI performs a task that looks like research but is actually just advanced information retrieval. It’s like using a massive electromagnet to find a needle in a haystack. You will find the needle, but you will also pull up every other piece of ferrous metal in the barn. The human lawyer’s job is to sort through the pile of scrap metal to confirm it’s the right needle and that it hasn’t rusted through.
Treating the AI’s initial output as a finished product is professional malpractice waiting to happen. It is a starting point, a broad-spectrum survey of the landscape. The real work of statutory research begins after the AI has delivered its raw, unverified data dump.
Managing the Hallucination Tax
The term “hallucination” is imprecise marketing speak for what is simply a model generating a statistically probable but factually incorrect output. Because these models are built to predict the next token, they can assemble sentences that are grammatically perfect and sound authoritative but cite non-existent legal cases or invent subsections of a statute. The model isn’t lying. It has no concept of truth. It is just completing a pattern based on its training data.
This creates a hidden “hallucination tax” on every AI-driven research project. You save time on the initial data pull, but you must now spend time rigorously verifying every single assertion, citation, and quote the AI provides. A human researcher might be slower, but their process has built-in validation. They read the source document. They follow the citation. The AI bypasses that, forcing the validation step to the end of the process where it is more costly to fix a foundational error.
Some platforms try to mitigate this with retrieval-augmented generation (RAG). In a RAG architecture, the AI doesn’t rely solely on its internal training. It first retrieves relevant source documents from a database and then uses those documents as the context to generate its answer. This reduces the frequency of pure fabrication and often provides direct source links. This is an improvement, but it is not a cure.
Common RAG Failure Points
- Poor Retrieval: If the initial retrieval step pulls the wrong documents, the generator will confidently synthesize an answer based on incorrect source material.
- Context Window Limits: The AI can only consider a finite amount of text at once. If the key nuance is on page 50 of a retrieved document but the context window only fits the first 20 pages, the nuance is lost.
- Synthesis Errors: Even with the right sources, the model can misinterpret or incorrectly summarize complex legal language. It might conflate two separate ideas from the source text into one erroneous statement.
The validation layer cannot be automated away. Every output must be traced back to its source document by a human with legal training. Any firm that blindly trusts AI-generated summaries is simply deferring risk, not eliminating it.
The Human as the Final Logic-Check
The most valuable work in legal research happens after the relevant text has been located. This is the domain of human expertise, and no current AI architecture can replicate it. The machine can find the words on the page, but the lawyer understands the world in which those words operate.
Consider the task of researching environmental compliance statutes for a new manufacturing plant. An AI can pull every federal and state regulation mentioning “industrial discharge” or “air quality permits.” It can even summarize the requirements. What it cannot do is apply that information to the client’s specific context. It doesn’t know the plant’s location relative to a protected wetland, the political climate of the local zoning board, or the client’s tolerance for litigation risk. A senior lawyer takes the raw statutory text and filters it through this complex, real-world context to produce actual legal advice.
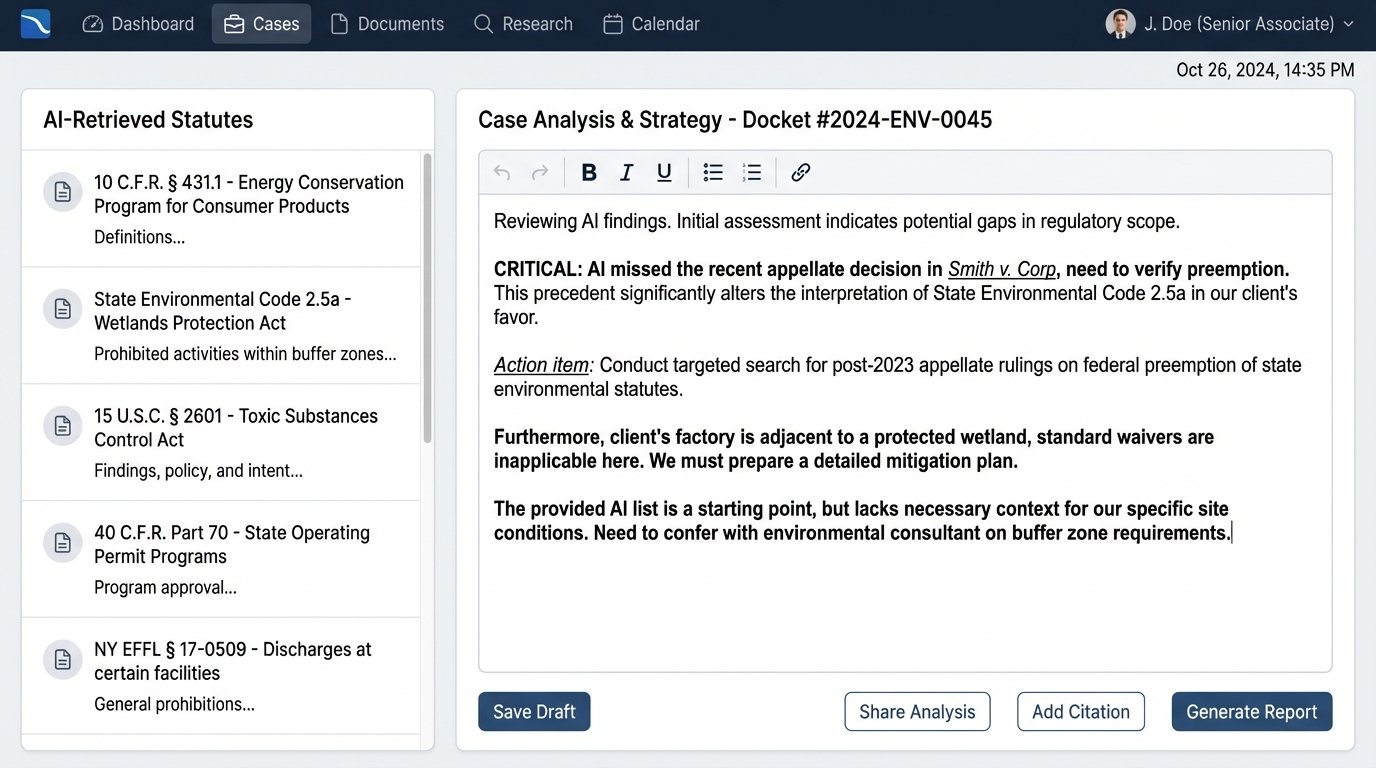
This requires a type of reasoning that models are not built for. It involves weighing conflicting priorities, understanding unwritten rules of practice before a specific regulatory agency, and making strategic judgments. For example, the statute may provide for a waiver under certain conditions. The AI can identify the waiver provision. The human lawyer can advise whether applying for that waiver is a good idea, based on their experience with how the agency scrutinizes such applications. This is not about information. It is about wisdom.
Using an AI for statutory research is like trying to build a house with only a nail gun. It’s incredibly fast at one specific task, but you still need a human to read the blueprint, measure the wood, and make sure the walls are plumb. Shoving a firehose of raw data through a needle of specific client needs is the fundamental job, and the AI only handles the firehose part.
Architecting a Hybrid Research Workflow
A functional and defensible workflow does not pit AI against humans. It leverages each for what it does best. It forces a clear separation between machine-driven data collection and human-driven analysis. A production-ready system for this looks less like a single magic button and more like a multi-stage assembly line.
Stage 1: AI-Powered Broad-Spectrum Scan
The process begins with an experienced attorney or paralegal crafting a series of detailed, natural language queries for the AI platform. The goal is not to get a final answer but to cast the widest possible net. You ask the system to find every statute, regulation, and administrative rule in selected jurisdictions related to the core legal question. The output is treated as raw intelligence, a high-volume data stream that is assumed to be noisy and partially inaccurate.
Stage 2: Human Triage and Keyword Refinement
A junior associate or a highly trained paralegal takes this raw output. Their job is to quickly strip the obvious junk. They scan the results for clearly irrelevant statutes and use their legal knowledge to identify the 20% of results that are likely to contain the answer. They may then take the most promising statutes and use traditional Boolean search in a tool like Westlaw or LexisNexis to drill down and find specific language, using the AI’s output as a highly effective finding aid rather than the source of truth.
Stage 3: Senior Counsel Validation and Strategic Application
This refined and narrowed list of verified statutes is then handed off to senior counsel. This is where the actual legal work begins. The lawyer is no longer wasting time on the mechanical task of finding the law. They are focused entirely on the high-value work of interpreting the law, applying it to the client’s facts, and developing a legal strategy. They read the full text of the statutes, analyze the relevant case law that interprets them, and synthesize it all into actionable advice. This final stage is non-negotiable and cannot be delegated to a machine.
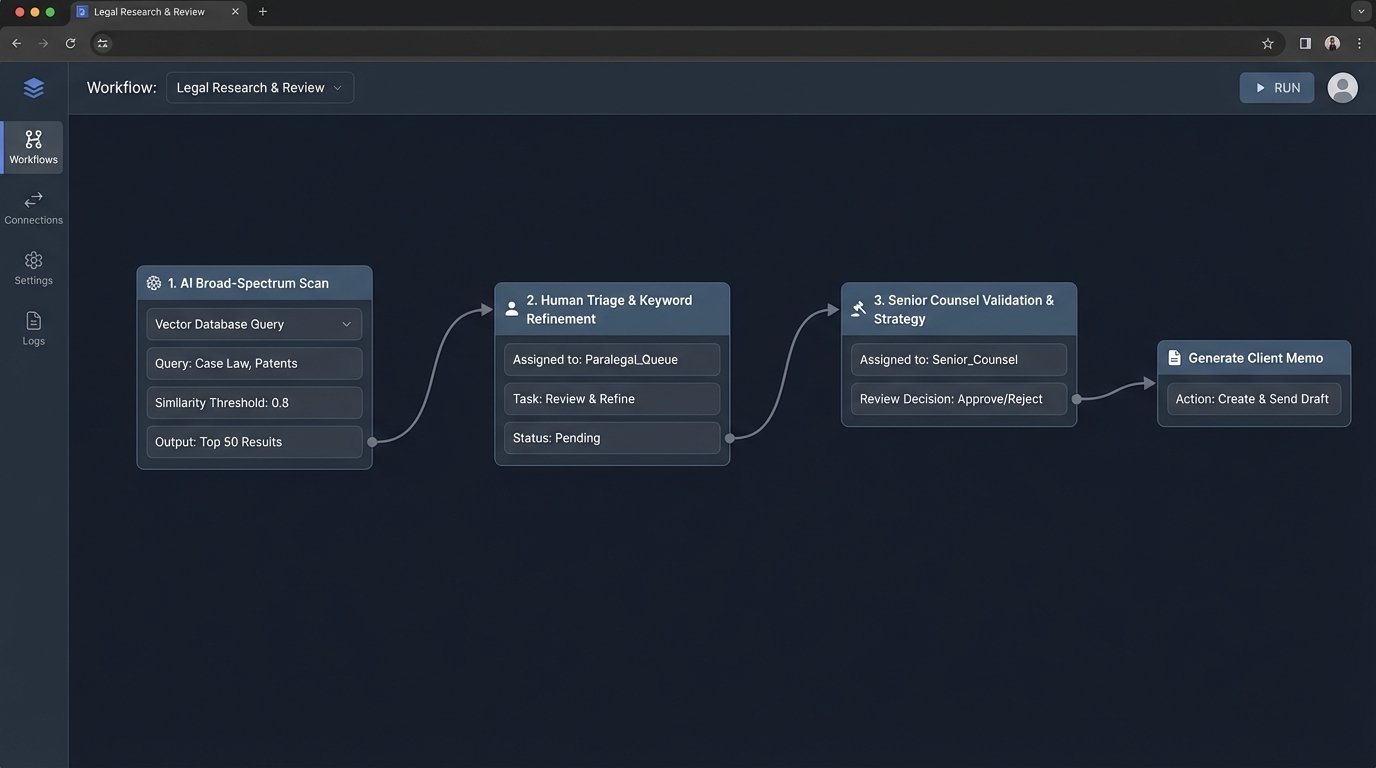
This staged approach maximizes efficiency without sacrificing accuracy. It uses the AI for its strength in processing massive datasets and reserves human brainpower for nuanced interpretation and strategic thought. It builds a defensible research trail, where each stage of filtering and validation can be documented. It’s not as sexy as the “AI does everything” pitch, but it works in a production environment where mistakes have real consequences.
The current generation of AI tools are powerful additions to the legal tech stack. They are not a replacement for the core cognitive skills of a lawyer. The firms that succeed will be those that instrument their workflows to leverage these tools for what they are: incredibly fast, slightly unreliable research assistants that require constant adult supervision. The real skill is not in writing the perfect prompt. It is in designing the human-centric system that validates, refines, and ultimately transforms the machine’s raw output into legal work product.