
Most large law firms don’t have a technology problem. They have a plumbing problem. Decades of bolted-on systems, from document management to e-billing, create a labyrinth of disconnected data pipes. Our firm was no different. The core issue was the sheer volume of manual, non-billable labor sunk into repetitive tasks, specifically within M&A due diligence and large-scale contract analysis. The process was a predictable bottleneck.
A junior associate would receive a virtual data room (VDR) link containing thousands of documents. Their job was to manually open each PDF or DOCX file, identify key clauses like change of control or indemnification, and populate a spreadsheet. This work consumed hundreds of hours per deal, was prone to human error from fatigue, and taught associates very little about the practice of law. The firm billed for some of it, but the write-offs were substantial and partner oversight was a constant, draining exercise in quality control.
The Anatomy of Operational Drag
The situation created a negative feedback loop. Because the process was so manual, partners were conservative in their project bids, often underestimating the true labor cost. This led to razor-thin margins or outright losses on fixed-fee diligence projects. Associates burned out on tedious work, leading to higher turnover. The data captured in those painstakingly created spreadsheets was a dead asset. It sat in a project folder, never aggregated or analyzed for broader trends across deals. We were effectively re-learning the same lessons on every new engagement.
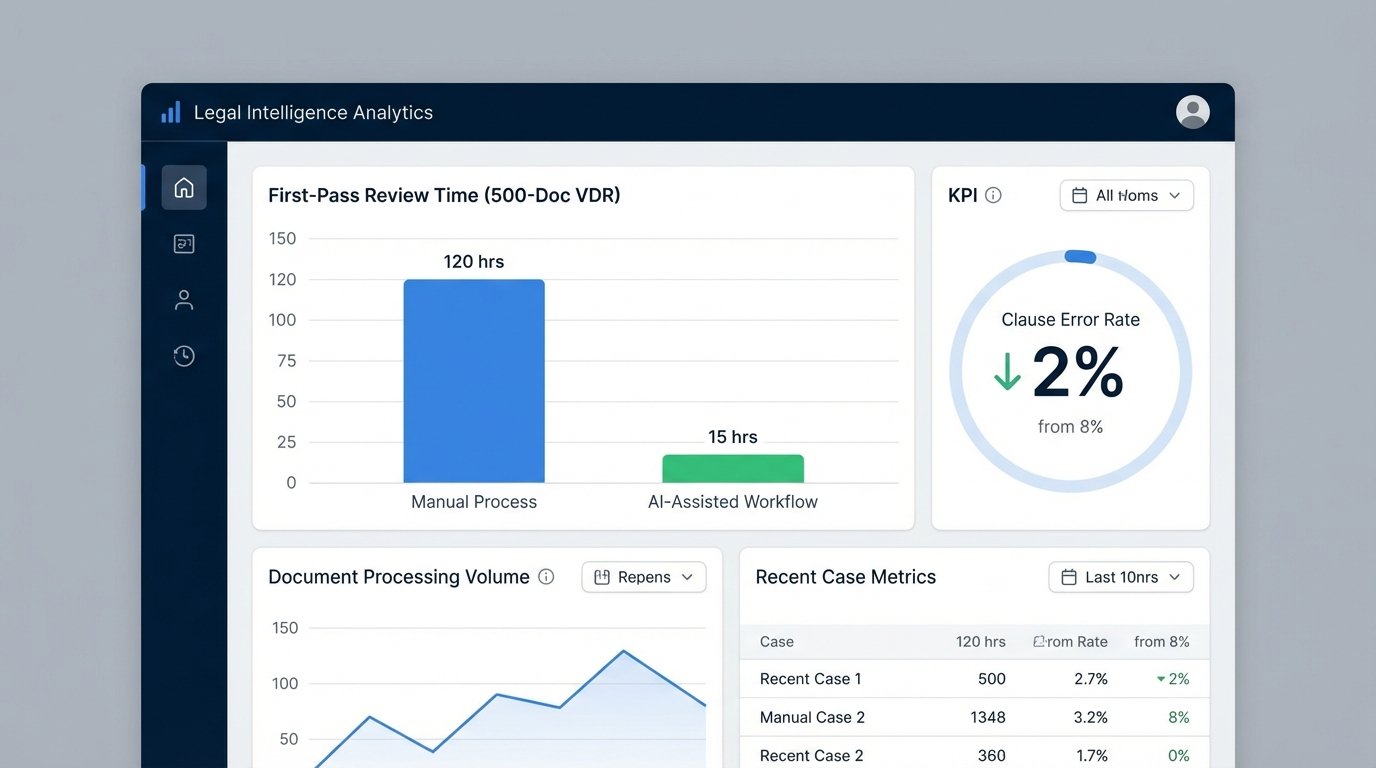
Our key performance indicators told a grim story. The average time to complete a first-pass review on a 500-document data room was 120 associate-hours. The error rate, defined as missed or incorrectly categorized clauses, hovered around 8% upon partner review. This wasn’t a failure of people. It was a failure of process architecture. We were asking skilled legal minds to perform the work of a script.
Initial Mandate: Find an “AI” Solution
The initial directive from the executive committee was predictably vague: “Investigate AI for contract review.” This kicked off a six-month bake-off between three major vendors in the space. The sales demos were impressive, full of slick user interfaces and promises of 99% accuracy. The reality of implementation, however, is where the marketing narrative collides with a firm’s legacy infrastructure.
We quickly established that the AI platform itself was only one piece of a much larger puzzle. The real challenge was getting the data *into* the platform and getting the structured output *out* and into our existing workflows. Our iManage DMS had a clunky, decade-old COM API. Our internal matter management system was a homegrown SQL database. The AI platform expected clean, RESTful API calls with JSON payloads. This is the technical gap where most legal automation projects die a slow death. It’s like trying to connect a modern firehose to a Roman aqueduct.
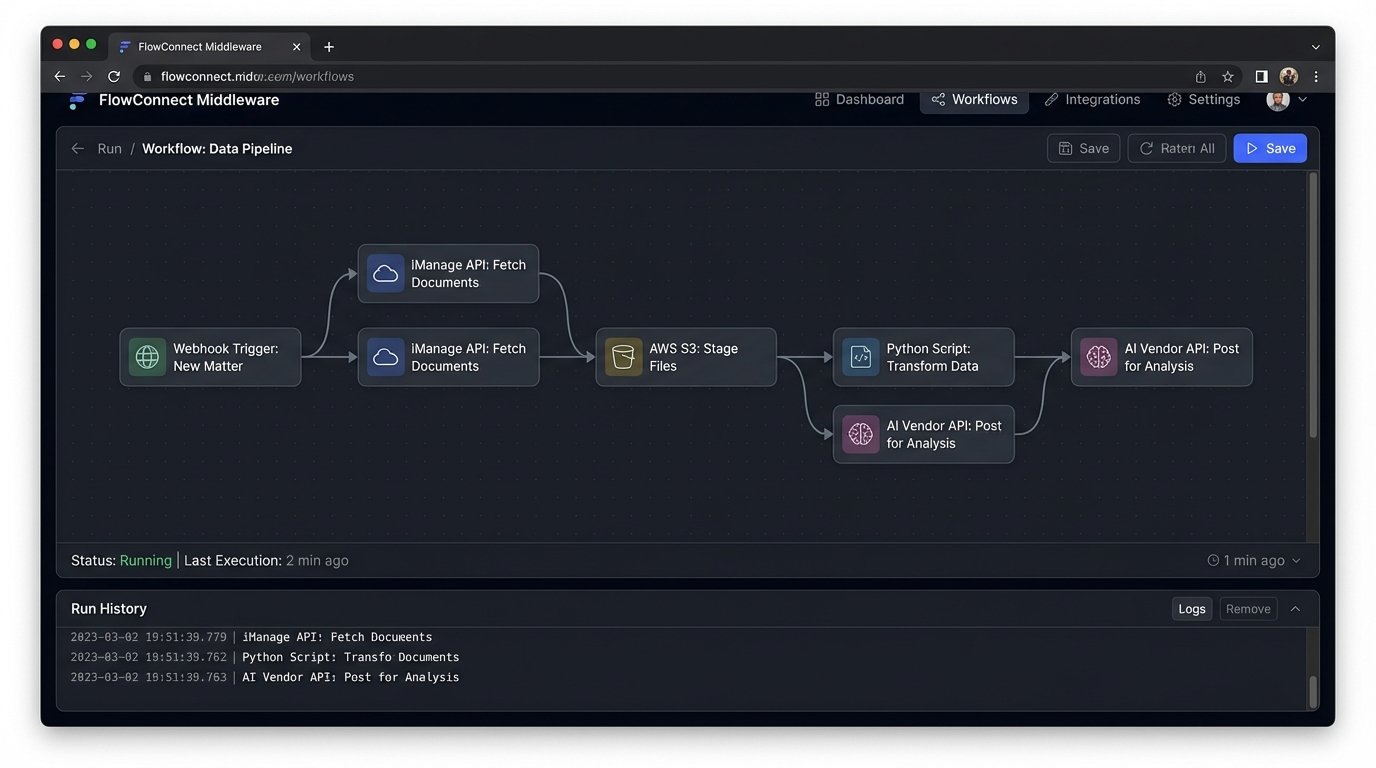
The solution couldn’t just be a new piece of software. It had to be an end-to-end workflow that bridged our old systems with the new. We needed to build the plumbing.
Architecture of the Bridge
We decided to build a lightweight middleware layer using Python and the FastAPI framework, hosted on an internal server. This service would act as a universal translator. It would expose a simple, internal-facing API that our own systems could talk to, and it would handle the complex logic of communicating with both the legacy DMS and the new AI vendor’s API.
The workflow was designed to be triggered by a simple action within our matter management system. When a partner designated a new matter for “Accelerated Review,” our system would fire a webhook to the middleware service. The process broke down into four distinct stages.
Stage 1: Document Ingestion and Staging
The first job of the middleware was to fetch the documents. This involved a series of painful API calls to the iManage COM API to pull documents based on a matter ID. The documents were temporarily staged in a secure AWS S3 bucket. We had to write custom logic to handle iManage’s peculiar authentication tokens and to recursively traverse its folder structures. It was slow and brittle, but it worked.
Once in S3, each document was assigned a unique ID. This ID became the primary key for its entire lifecycle through the automation process, ensuring we could track it from ingestion to final reporting.
Stage 2: Pre-Processing and OCR
Not all documents are created equal. Many were scanned PDFs with no text layer. Before sending anything to the AI platform, each document was routed through an optical character recognition (OCR) engine. We used AWS Textract for this. It performed well on clean, machine-printed text but struggled with grainy scans or documents with complex table structures. This was our first point of “logical friction.” We had to build a quality gate. If Textract returned a confidence score below 90% for a document, it was flagged for manual review and bypasses the AI analysis entirely. This prevented us from polluting the AI system with garbage data.
We also implemented a small Python script to strip out common junk text, like fax headers or confidentiality footers that appeared on every page. This small cleaning step slightly improved the signal-to-noise ratio for the AI model.
import re
def clean_document_text(text):
# Remove common fax headers and footers using regex
text = re.sub(r'FAX TO:.*', '', text, flags=re.IGNORECASE)
text = re.sub(r'CONFIDENTIALITY NOTICE:.*', '', text, flags=re.IGNORECASE)
# Normalize whitespace
text = ' '.join(text.split())
return text
# Example usage:
# raw_text = get_text_from_ocr(document_id)
# cleaned_text = clean_document_text(raw_text)
# post_to_ai_platform(document_id, cleaned_text)
This simple function became a critical part of the pipeline. It’s not sophisticated, but it demonstrates the kind of unglamorous, practical code required to make these systems function.
Stage 3: AI Analysis and Data Structuring
With a clean, text-based version of the document, the middleware service would then package it into a JSON payload and POST it to the AI vendor’s API endpoint. The AI platform would then do its job, identifying pre-trained clauses (Change of Control, Liability, Term, etc.) and custom-trained provisions specific to our practice area.
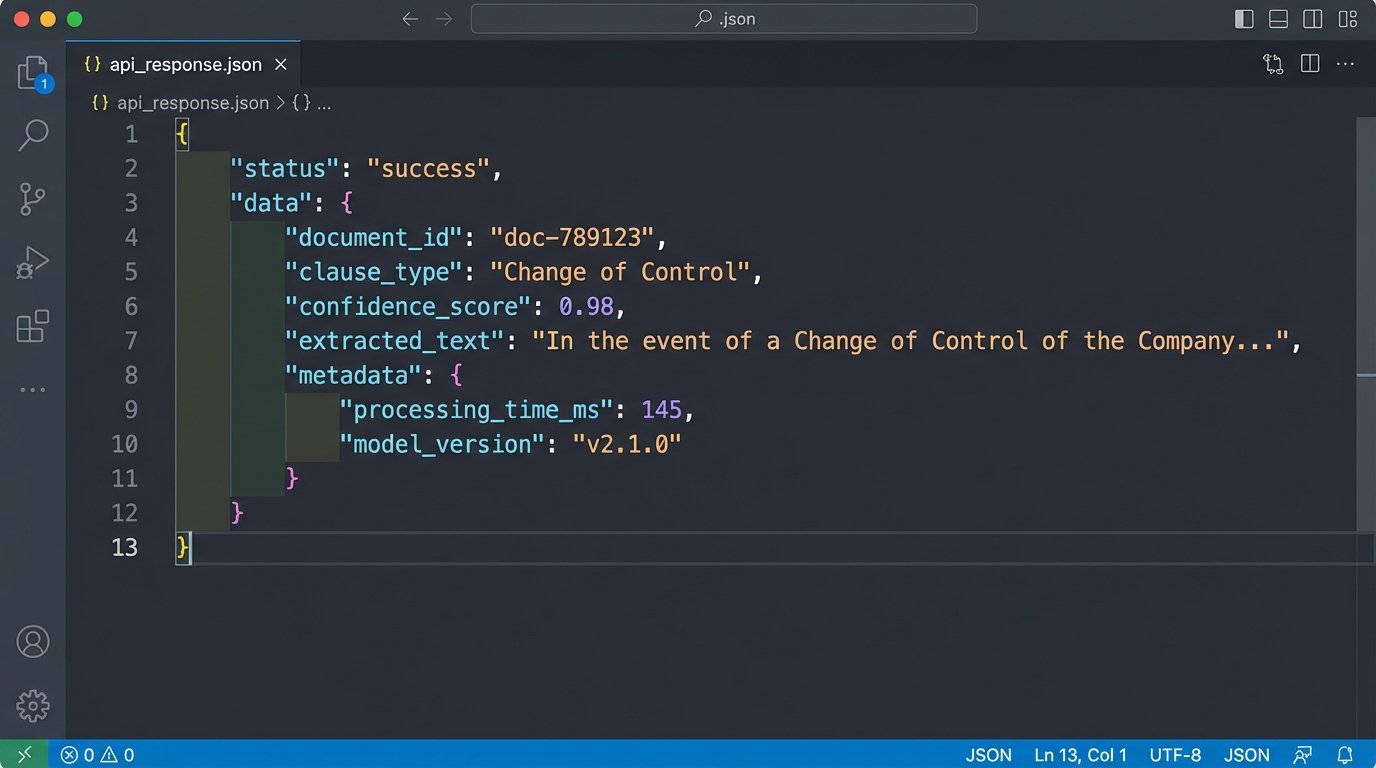
The response from the AI API wasn’t a simple “yes” or “no.” It was a rich JSON object containing the identified clause text, its location in the document, and a confidence score. This structured data was the gold we were mining for. Our middleware parsed this response and stored the structured data in a dedicated PostgreSQL database, linking it back to the document’s unique ID.
- Document ID: `doc-789123`
- Clause Type: `Change of Control`
- Confidence Score: `0.98`
- Extracted Text: `”In the event of a Change of Control of the Company, this Agreement shall…”`
- Page Number: `12`
Storing this data centrally was the most important architectural decision we made. It turned the output of individual reviews into a queryable, long-term firm asset.
Stage 4: Reporting and Human-in-the-Loop
The final step was to present the results to the legal team. The system did not simply email them a spreadsheet. Instead, we built a simple web-based dashboard. This dashboard listed all documents in the project and allowed associates to filter them. They could see all documents that contained a “Change of Control” clause or, more important, all documents where the AI did *not* find an expected clause.
This “human-in-the-loop” design was critical for adoption. The AI’s output was presented as a first draft, not a final answer. The associate’s job shifted from low-level text search to high-level validation. They reviewed the AI’s findings, corrected any misclassifications, and handled the documents that were flagged for manual review during the OCR stage. This approach kept the lawyers in control and built trust in the system.
Quantifiable Results and Second-Order Effects
After running the new system in parallel with the old manual process for three months, we collected the data. The results were stark. The average time for a first-pass review on a 500-document data room dropped from 120 hours to just 15 hours. That represents an 87.5% reduction in associate time.
The error rate also improved significantly. The AI-assisted workflow, with its human validation step, reduced the clause error rate from 8% to below 2%. The AI was more consistent than a tired human at 2 AM. It never missed a standard clause, and its failures were predictable. It struggled with poorly scanned documents or bizarrely formatted clauses, which were the exact items our quality gates were designed to catch and flag for human review.
The financial impact was direct. On fixed-fee arrangements, project profitability increased by an average of 40%. On hourly-billed matters, we could offer more competitive rates and still maintain our margins. The ROI on the software subscription and the internal development time for the middleware was achieved in just under seven months.
The Unexpected Cultural Shift
The biggest impact wasn’t on the balance sheet. It was on our people. Junior associates were no longer trapped in the digital equivalent of a salt mine. Their work shifted from finding needles in a haystack to analyzing the needles that the machine found for them. They spent more time thinking about the legal implications of a clause rather than just locating it. Partner review became faster and more focused, as they could trust the underlying data’s integrity.
The centralized database of contract clauses also became an invaluable resource. Practice group leaders could now run queries across thousands of agreements to identify market trends for specific provisions. It allowed us to provide data-backed advice to clients on what constituted a “standard” indemnification cap in their industry. We were no longer just practicing law. We were analyzing the data of law.
This project was not a simple software installation. It was a complex systems integration effort that required building the connective tissue between our past and our future. The work was difficult, and the internal politics of changing established workflows were even harder. But the result was a more efficient, more profitable, and frankly, a more intelligent way to operate.