
A five-attorney personal injury firm was burning through 25 billable hours a week on client intake. Their process was a tangle of web form emails, manual data entry into their case management system, and copy-pasting information into retainer agreements. The error rate for addresses and phone numbers was approaching 15 percent, forcing rework and creating client friction before the first consultation was even complete. This wasn’t a workflow. It was a liability bleeding cash and credibility.
The problem was systemic. The firm viewed technology as a collection of disconnected buckets. A WordPress site for marketing, Outlook for communication, a cloud-based CMS for record-keeping, and Microsoft Word for document creation. There were no bridges between these systems, forcing paralegals to become expensive, error-prone human APIs. Each new potential client triggered a 45-minute manual routine that was both mind-numbing for the staff and a direct drag on firm profitability.
Diagnostic: Mapping the Failure Points
Before architecting a solution, we had to chart the existing process to identify every point of failure. The sequence was brutally inefficient. It began with a potential client submitting a generic contact form on the firm’s website. This action generated an unstructured email sent to a general intake inbox. A paralegal was then tasked with monitoring this inbox, parsing the email content, and manually keying every piece of data into their CMS, a popular but aging platform with a notoriously sluggish web interface.
This initial data entry was the primary bottleneck. Names, dates, and incident descriptions were transferred by hand. Once the contact record was created in the CMS, the paralegal had to create a new matter and link it to the contact. Finally, they would open a Word template for the engagement agreement, copy the client’s name and address from the CMS, and paste it into the document. The final PDF was then manually attached to an email and sent to the client. Every step was a potential point of failure, from typos in the address field to attaching the wrong client’s agreement to an email.
The core issue was the lack of a structured data pipeline. Unstructured email is a terrible medium for initiating a structured legal process. It lacks validation, formatting, and the metadata required to drive automation. We confirmed that the average time from web form submission to a sent engagement letter was four hours, with the direct manual labor accounting for 45 minutes of that time. This delay was long enough for a potential client to contact and retain a competitor.
Quantifying the Inefficiency
We attached hard numbers to the pain. With an average of 30 new intakes per month, the firm was losing approximately 22.5 hours of paralegal time to this specific task alone. At a conservative blended rate, this represented a significant operational drain. The 15 percent error rate meant that for roughly 4-5 clients each month, a paralegal had to spend additional time correcting records, reissuing documents, and managing the client communication around the error. The firm was paying its skilled paralegals to perform low-value, high-risk data entry.
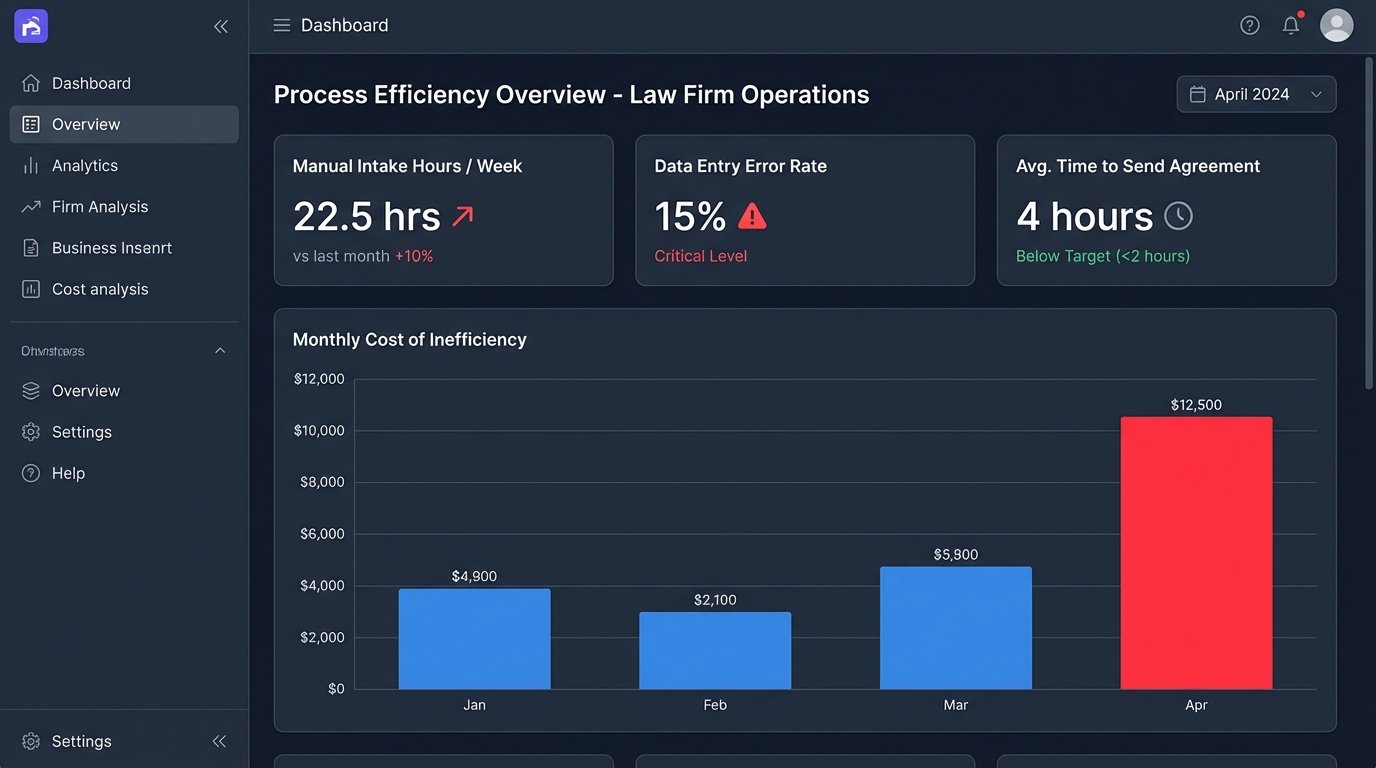
This quantitative analysis was critical. It shifted the conversation from “our intake is slow” to “our intake process costs us X amount per year and creates Y number of correctable errors.” It framed automation not as a luxury or a technical experiment, but as a direct solution to a quantifiable business problem.
The Architecture: A Central Orchestration Layer
Gutting the manual workflow required a central system to catch, process, and route data. We built this using a standard integration platform that acts as an orchestration layer, connecting the firm’s website directly to its internal systems via APIs. The goal was to ensure that a human would not touch the data until it was validated, formatted, and securely stored within the CMS, with all initial documents and tasks already created.
The new process is triggered by a webhook, not an email. We replaced the old contact form with a more intelligent tool capable of sending a structured data payload to a specific endpoint URL. When a potential client hits submit, the form sends a clean JSON object to our automation workflow. This single event kicks off a precise, sequential chain of actions that executes in under two minutes.
The Automated Sequence
The workflow is built on a series of discrete, logic-checked steps:
- Data Reception and Sanitization: The webhook catches the JSON payload from the web form. The first step is to strip any garbage characters and force standard formatting on critical fields. Phone numbers are converted to E.164 format, states are converted to two-letter abbreviations, and email addresses are checked for valid structure.
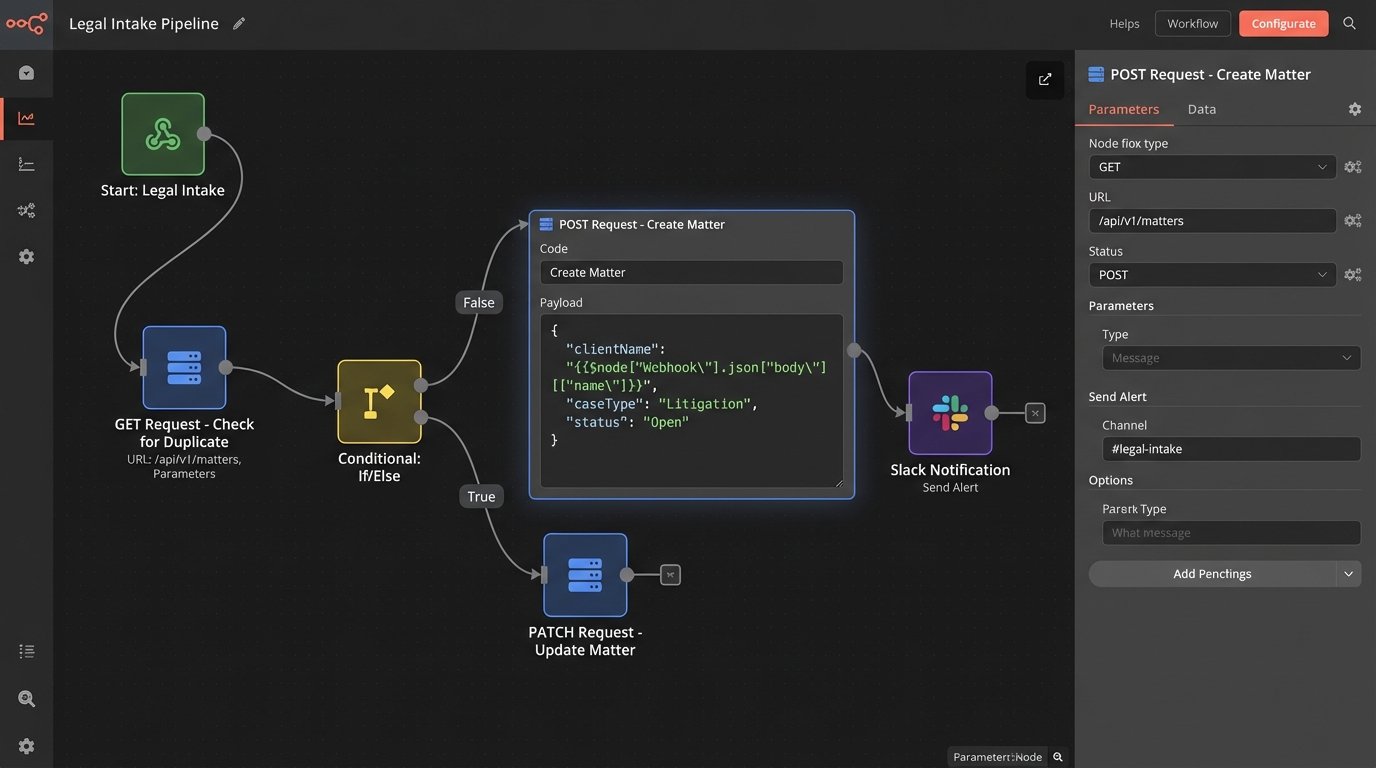
- Duplicate Check: The system executes an API GET request to the firm’s CMS, searching for an existing contact with a matching email address. This is a critical step to prevent creating duplicate client records, a common source of data corruption in law firms. The logic is simple: if a contact exists, use its unique ID for all subsequent steps. If not, proceed to create one.
- Conditional Pathing: The workflow now splits. If a duplicate was found, it proceeds down a path to create a new matter and associate it with the existing contact ID. If no duplicate was found, it first executes a POST request to create the new contact, captures the new contact ID from the API response, and then proceeds to create the matter.
- Matter Creation: Using the contact ID, the workflow makes another POST request to the CMS API to create a new matter. It populates the matter with the case type, description of the incident, and date of occurrence, all pulled directly from the initial form submission. A simplified version of that API call’s body looks something like this:
{
"matter": {
"client_id": "con_123456789ABCDEF",
"display_number": "PI-2024-08-15-JONES",
"description": "Motor vehicle accident on 2024-08-15. Client was rear-ended at intersection of Main St and 1st Ave.",
"status": "Pending",
"practice_area": "Personal Injury",
"custom_fields": {
"incident_location": "Main St and 1st Ave",
"police_report_filed": true
}
}
}
- Document Generation and Storage: With the matter now existing in the CMS, the workflow sends the sanitized data to a document generation service. This service injects the data into a pre-approved retainer agreement template, generates a PDF, and saves it to a designated folder in the firm’s cloud storage, using a standardized naming convention.
- Finalization and Notification: The final API call attaches the newly generated document directly to the matter record within the CMS. Simultaneously, a notification is posted to a dedicated Slack channel for the intake team. This message includes the client’s name, a summary of their case, and a deep link directly to the new matter in the CMS. A paralegal can now review the complete, accurate record and send the prepared agreement with one click.
Implementation Hurdles and Realities
The architecture on paper was clean. The reality of implementation was not. The firm’s cloud CMS had an API, but the documentation was five years out of date and contained multiple inaccuracies. We discovered through trial and error that the endpoint for creating matters would fail silently if certain non-mandatory fields were formatted incorrectly. There were no useful error messages, just a generic “400 Bad Request” response that forced us to debug by systematically removing fields from the payload until the call succeeded.
Treating the CMS API as a simple data bucket is a mistake. It’s more like a temperamental gearbox; you have to shift data in at the right speed and in the right sequence, or the whole thing grinds to a halt. We had to build in a 2-second delay between creating the contact and creating the matter because the CMS database had replication lag. A request to create a matter for a contact ID that was only milliseconds old would fail because the database replica serving the “matters” endpoint hadn’t yet registered the new contact.
Mapping the form fields to the CMS custom fields was another source of friction. The firm had dozens of custom fields, many of them legacy fields with ambiguous names. We had to conduct a full audit with the paralegals to determine which fields were still in use and establish a definitive mapping schema. This forced the firm to confront years of data hygiene neglect. We ultimately deprecated half of their custom fields and standardized the intake form to only capture what was legally and operationally necessary for the initial client onboarding.
The Measured Results
The operational impact was immediate and stark. The 45 minutes of manual labor per intake was reduced to under three minutes of a paralegal reviewing the auto-generated record and document. The four-hour delay from submission to client contact was cut to less than 15 minutes on average. This acceleration had a direct impact on the firm’s conversion rate, as they were now the first to respond with a formal engagement document.
The numbers provided a clear picture of the ROI. We eliminated the 22.5 hours of manual data entry per month. This did not result in a headcount reduction. It resulted in the firm’s three paralegals being freed to focus on higher-value, billable work: drafting discovery requests, communicating with existing clients, and supporting attorneys in case preparation. The firm was able to absorb a 20 percent increase in case volume over the next six months without increasing administrative staff.
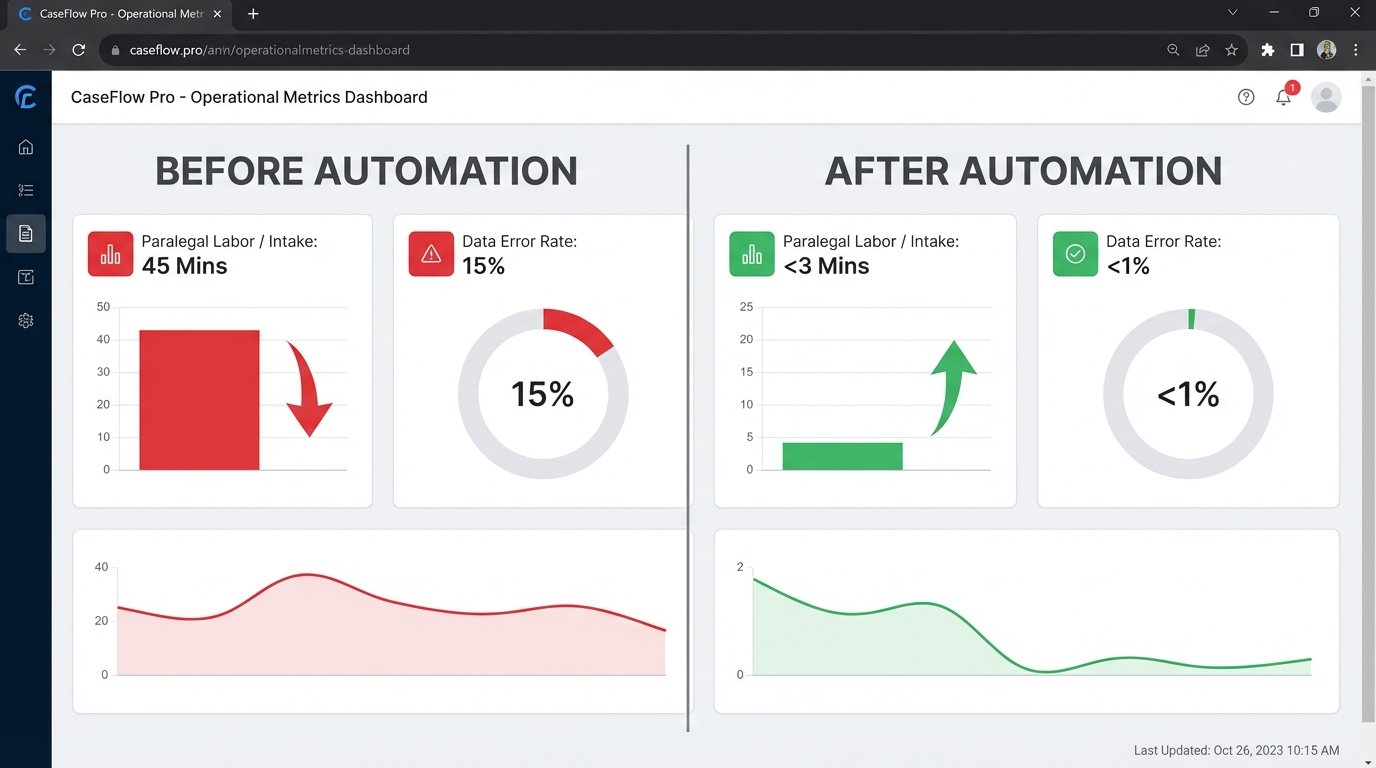
Data accuracy improved dramatically. By forcing structured data entry at the source (the web form) and eliminating manual transcription, the data entry error rate dropped from 15 percent to below 1 percent. This one percent accounts for client-side errors in the initial submission. The reduction in rework and the improved data quality had a cascading effect, making subsequent reporting and case management more reliable. The firm could now generate accurate reports on case sources and types without a manual data cleanup process.
This project was not about adding a flashy piece of technology. It was about re-engineering a core business process by forcing systems to communicate directly. The initial build required a focused effort to overcome technical debt and poor API documentation, but the resulting system created a durable, scalable foundation for the firm’s growth.