
Most contract review automation platforms demo beautifully. They ingest a clean, typewritten PDF and, seconds later, spit out a perfect JSON object with dates, parties, and liability clauses neatly tagged. In production, this fantasy evaporates. You get a 78-page scanned lease agreement from 1993, complete with coffee stains, skewed text, and handwritten margin notes. The system chokes, and you are left with a garbage output that is worse than manual review.
Success isn’t about buying the fanciest AI. It is about building a resilient data pipeline that anticipates and handles the chaos of real-world legal documents.
Garbage In, Garbage Out: The OCR and Pre-Processing Wall
The single greatest point of failure in any contract review automation is the initial text extraction. Before any sophisticated Natural Language Processing (NLP) model can even look at the document, you must convert it into clean, machine-readable text. This step is brutish, unglamorous, and absolutely critical. If your Optical Character Recognition (OCR) engine misinterprets “indemnify” as “indemnify,” your entire downstream analysis is compromised.
Your first decision is the OCR engine itself. Cloud-based services from AWS Textract or Google Vision API offer powerful, pre-trained models that handle complex layouts. They are wallet-drainers at scale. Open-source tools like Tesseract are free but require significant configuration and pre-processing logic to produce usable results on low-quality scans. You must force image correction logic, such as deskewing and binarization, before feeding the document to the engine. This is not optional.
Trying to feed a multi-column, scanned PDF with handwritten notes into a generic NLP model is like trying to pour concrete through a coffee filter. The structure gets destroyed, and you are left with a useless mess.
Post-OCR cleanup is another mandatory gate. You have to strip out irrelevant artifacts like page numbers, headers, and footers. These elements introduce noise that confuses clause detection models. Regular expressions are your blunt instrument here. A simple regex can find and nullify most “Page X of Y” patterns, but complex headers with titles or dates require more specific rules. Build a library of these cleaning rules. It will become your most valuable asset.
Structuring Unstructured Text
Once you have a wall of cleaned text, you need to reconstruct the document’s logical structure. An NLP model does not inherently understand sections, clauses, sub-clauses, and exhibits. You must inject this structural context. The most reliable method involves parsing the document for hierarchical numbering and lettering schemes (e.g., “Article 1,” “Section 1.1,” “(a),” “(i)”).
This parsing logic is fragile. A typo in the numbering, like “Section 2.3” followed by “Section 2.5,” can break a simple incremental parser. Your code must be defensive, capable of identifying these gaps and either flagging the document for manual review or attempting to infer the correct structure. This process is about building a fault-tolerant system, not a perfect one.
Model Selection: The Off-the-Shelf vs. Fine-Tuning Dilemma
With clean, structured text, you can finally approach the AI component. The market is flooded with vendors offering pre-trained models for extracting common contract provisions: termination clauses, governing law, limitation of liability. These generic models provide a good baseline and can accelerate initial deployment. They are trained on a massive, generalized corpus of legal documents.
Their primary weakness is specificity. A generic model might identify a “Limitation of Liability” clause, but it will likely fail to extract a nuanced, industry-specific “Consequential Damages Waiver” that is unique to your firm’s M&A playbook. These models lack the context of your specific operational needs. Relying solely on a generic model is a recipe for mediocre results.
Fine-tuning is the process of taking a pre-trained model and further training it on your own curated dataset of contracts. This adapts the model to your specific language, clause variations, and extraction targets. The process is resource-intensive. You need a labeled dataset, which means paralegals or junior associates must manually tag hundreds or thousands of example contracts. This is a significant upfront cost in both time and money.
The labeling process must be ruthlessly consistent. If one paralegal tags a sentence as “Confidentiality” and another tags a nearly identical sentence as “NDA Provision,” you are injecting ambiguity into your training data, which directly degrades model performance.
Building a Training Dataset
A minimal viable training dataset for fine-tuning a single entity (like “Effective Date”) requires at least 100 to 200 high-quality examples. For complex clause detection, this number climbs into the thousands. The data needs to be structured properly, often in a simple JSON format that pairs the text with the labeled entities.
Consider this simplified structure for training a Named Entity Recognition (NER) model to find the “Governing Law” jurisdiction:
{
"training_data": [
{
"text": "This Agreement shall be governed by and construed in accordance with the laws of the State of Delaware.",
"entities": [
[83, 100, "JURISDICTION"]
]
},
{
"text": "The validity, interpretation, and performance of this contract are controlled by the laws of New York.",
"entities": [
82, 91, "JURISDICTION"
]
}
]
}
The `entities` array specifies the start and end character offsets of the text span being labeled. This precision is non-negotiable for the model to learn the correct patterns. Building this dataset is a project in itself. Do not underestimate the effort.
Confidence Scoring and the Human-in-the-Loop Imperative
No AI model for contract review is 100% accurate. Anyone who tells you otherwise is selling you a product, not a solution. The only way to deploy this technology safely is to build a workflow that accounts for uncertainty. Every prediction the model makes, whether it is an extracted date or a classified clause, must be accompanied by a confidence score.
A confidence score is a probabilistic measure (typically 0.0 to 1.0) of how certain the model is about its prediction. Your system must be built around a threshold. For example, any extraction with a confidence score below 0.90 is automatically flagged for human review. Any extraction above that threshold might be accepted automatically. The threshold itself is a business decision, balancing risk against efficiency.
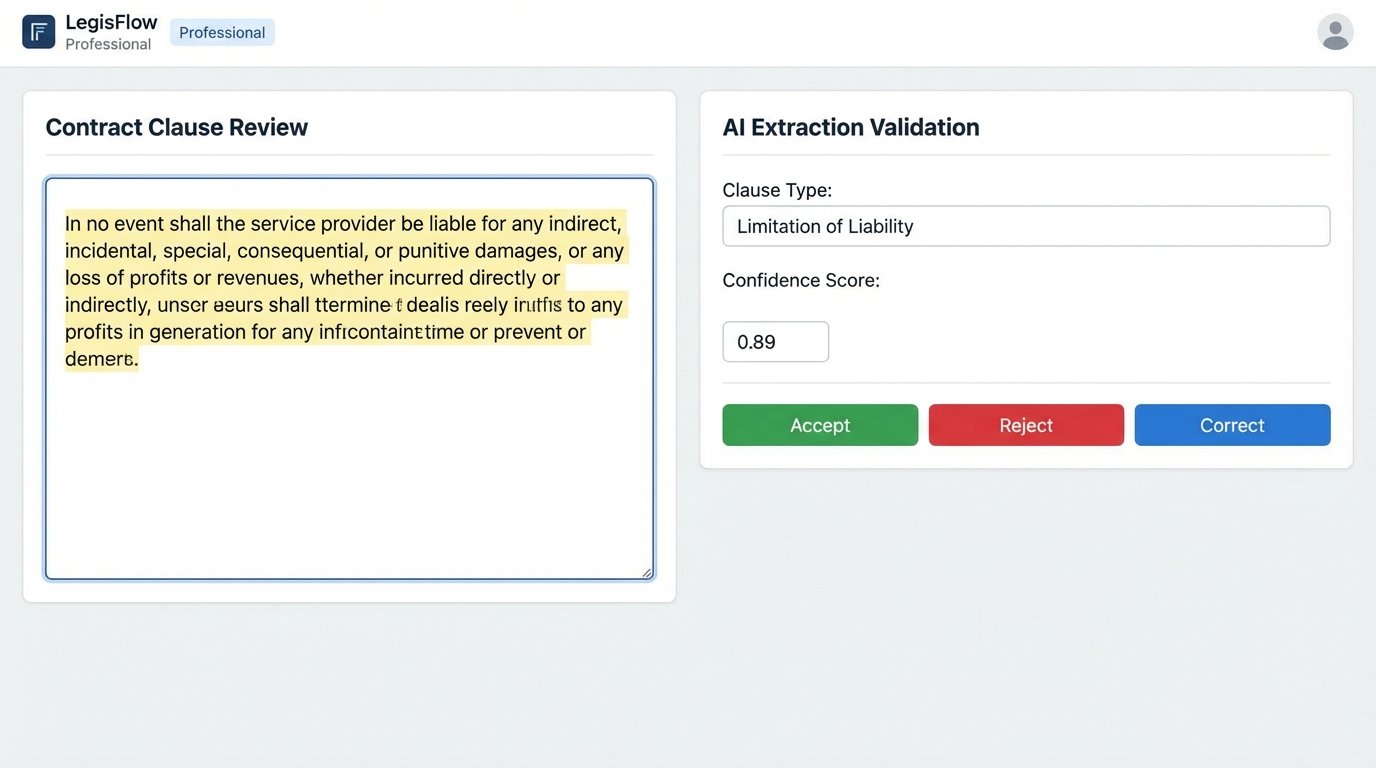
This “human-in-the-loop” (HITL) architecture is not a sign of failure. It is a sign of a mature, production-ready system. The interface for this review process needs to be brutally efficient. It should present the original document text, highlight the model’s extraction, show the confidence score, and provide a simple interface for the user to accept, reject, or correct the data. Every correction a user makes is valuable. These corrections should be fed back into a dataset to be used for future model retraining, creating a virtuous cycle of improvement.
A workflow without a human-in-the-loop for low-confidence scores is a time bomb. It is not a question of if it will inject bad data into your CLM, but when, and how much it will cost to clean up the resulting mess.
Integration and Data Validation: The Final Mile
Extracting data is useless if it does not go anywhere. The final stage of automation is integrating the validated output with other systems of record, typically a Contract Lifecycle Management (CLM) platform, a matter management system, or a simple database. This integration is often done via APIs, and legacy legal tech APIs are notoriously sluggish and poorly documented.
Before you push any data into a destination system, you must run a final validation layer. Does the extracted “Effective Date” conform to the ISO 8601 date format required by the CLM’s database schema? Is the extracted “Contract Value” a valid float or integer, or did the OCR accidentally interpret a comma as a period? These post-processing checks are the last line of defense against data corruption.
The integration logic must also handle API failures. What happens if the CLM endpoint is down for maintenance? The automation should not simply fail. A robust system will queue the data and implement a retry mechanism with exponential backoff to attempt the push again later. You must build for failure, because in the world of enterprise systems, failure is a certainty.
Monitoring and Model Drift
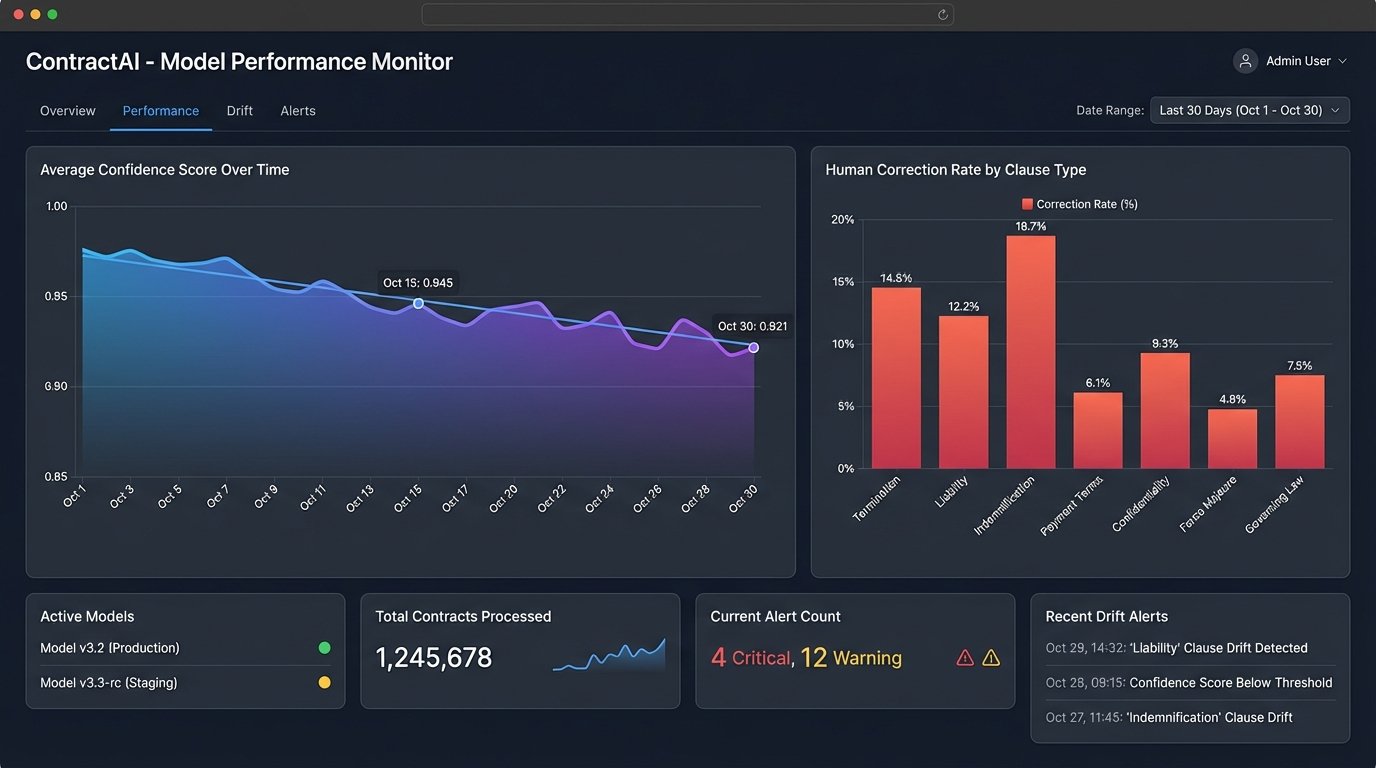
Deployment is not the end of the project. It is the beginning of the maintenance phase. Models decay over time. The language in contracts evolves, new clause types emerge, and the patterns your model was trained on become less relevant. This phenomenon is known as model drift, and it leads to a slow, silent degradation in performance.
The only way to combat drift is to monitor the model’s performance continuously. Track key metrics. What is the average confidence score for extractions this month compared to last? What is the rate at which human reviewers are correcting the model’s output? A rising correction rate is a clear signal that the model needs to be retrained with new, recent data. A contract review automation system is not a static application. It is a living system that requires ongoing care and feeding to remain effective.