
The core failure of traditional legal research is its reliance on keyword matching. An attorney guesses a set of terms, feeds them into a database, and hopes the query syntax is precise enough to catch relevant precedents without burying them in an avalanche of noise. This process is functionally identical to web search circa 1998. It’s a game of chance where billable hours are the currency.
We saw this firsthand with a mid-sized litigation firm handling a portfolio of complex product liability claims across three federal circuits. Their research workflow was a predictable bottleneck. Junior associates spent, on average, 16 hours building a research memo for a single dispositive motion. The final work product was inconsistent, heavily dependent on the individual associate’s keyword strategy and stamina. Key cases were being missed.
The mandate was to fix the retrieval process without gutting the firm’s existing case management system. They needed better inputs for their legal arguments, not a full technology transplant.
Diagnostic: The Boolean Trap
Boolean search is a rigid, unforgiving tool. A query for “defective manufacturing” AND “product recall” will entirely miss a key opinion that uses the phrase “flawed production process” and “market withdrawal.” The legal concept is identical, but the lexical variance causes a total miss. The firm’s attorneys were spending more time architecting elaborate search strings than analyzing the results they found.
This forced a reactive workflow. A partner would review a draft motion, find the research thin, and send the associate back for another round. These iterative loops inflated research time by an estimated 40% and generated significant write-offs. The firm was absorbing the cost of its own inefficiency.
Their existing process had no mechanism to account for conceptual similarity.
Solution Architecture: Injecting a Semantic Layer
We bypassed the keyword dependency by introducing an AI research platform. The goal was to shift the query mechanism from lexical matching to semantic understanding. Instead of feeding the system keywords, the team would provide a full paragraph describing the factual scenario or a legal argument from their brief. The platform would then parse this natural language input, identify the core legal concepts, and retrieve statistically relevant cases, regardless of the specific terminology used in the opinions.
The initial deployment was anything but smooth. The platform’s user interface was clean, but the underlying logic required a fundamental change in user behavior. For two weeks, the associates kept trying to use it like a conventional database, feeding it short keyword phrases and getting frustrated with the broad results. They were trying to force a new tool into an old box.
Training had to be hands-on and brutal. We forced them to feed the system entire sections from opposing counsel’s briefs. We made them upload prior successful motions to find analogous, non-obvious cases. It was about teaching them to trust the vector search and stop micromanaging the query syntax.

This is where the real work started. The platform was a black box, and we don’t trust black boxes.
Validating the AI Output: The Parallel Workflow
For the first 90 days, we ran a mandatory parallel research protocol. One junior associate was assigned to a motion using the AI platform, while another was assigned the same motion using the firm’s legacy boolean search tools. They were not allowed to collaborate. Both submitted their research memos directly to the supervising partner and our team.
The objective was twofold. First, to create a concrete dataset to measure the AI’s effectiveness against the established baseline. Second, to build trust. The partners needed to see hard evidence that the new system wasn’t just faster but demonstrably better at finding critical on-point cases.
The initial results were messy. The AI often surfaced cases from adjacent areas of law that were conceptually relevant but jurisdictionally useless. It required a human filter to strip out the noise. This is the part the sales demos conveniently omit. The AI is a powerful signal generator, but a human brain is still required to perform the final logic-check and separate signal from noise.
Mapping the platform’s outputs to the firm’s case management software was another friction point. The platform’s API was functional but clearly an afterthought, with documentation that was a year out of date. We had to build a small middleware application to pull the research results, format them, and inject them into the correct matter file. It was like building custom plumbing to connect two systems that were never designed to speak the same language.
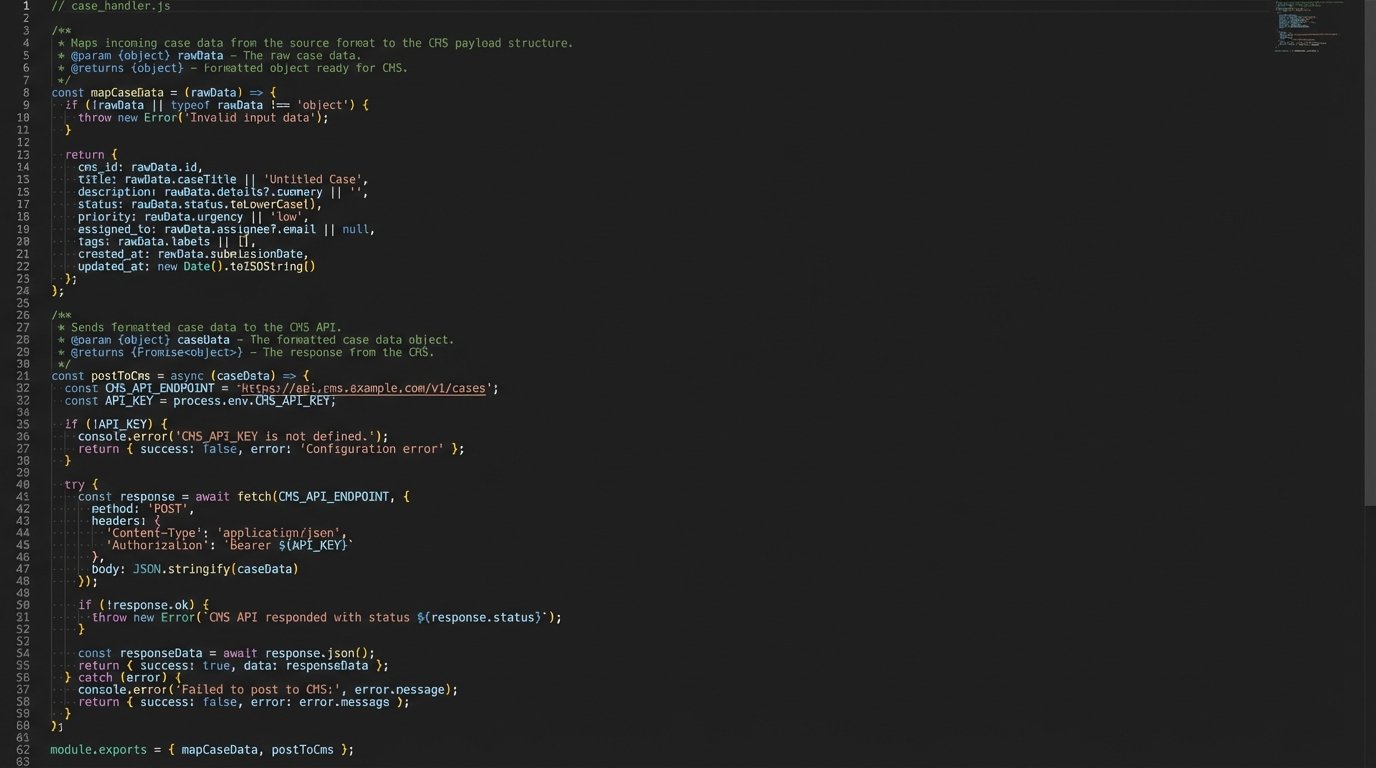
A Snippet of the Data Bridge Logic
The API returned a JSON object for each case. Our middleware had to parse this and map it to the CMS fields. The logic was straightforward but tedious, especially handling inconsistent data types for court IDs.
function mapCaseData(apiResponse) {
let formattedCase = {
cms_matter_id: currentMatter.id,
case_name: apiResponse.caseName || 'N/A',
citation: apiResponse.citationPrimary || apiResponse.citationSecondary,
court: getInternalCourtId(apiResponse.court),
decision_date: formatDate(apiResponse.decisionDate),
relevance_score: apiResponse.relevance,
summary_text: stripHtml(apiResponse.summary)
};
return formattedCase;
}
function postToCms(caseData) {
// API call to the legacy CMS endpoint
// Includes error handling for timeouts and auth failures
}
This small script saved hours of manual copy-pasting and prevented data entry errors. It was a simple bridge, but it was essential for adoption. No one will use a tool that doubles their administrative work.
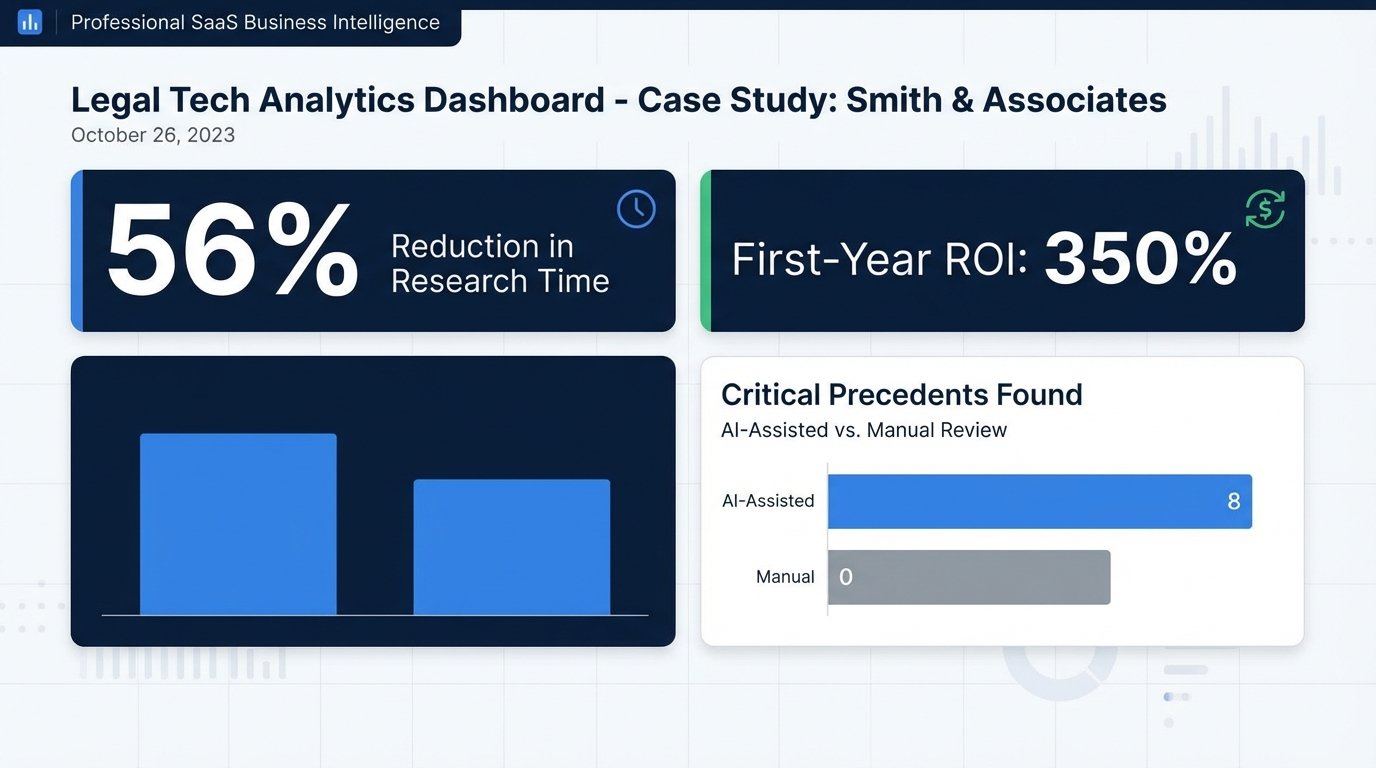
Measured Impact: KPIs and Second-Order Effects
After the 90-day parallel period, the data was conclusive. We analyzed 25 separate motions for summary judgment and motions to dismiss. The metrics provided the business case to expand the platform license to the entire litigation group.
KPI 1: Research Time Reduction
The most immediate impact was on billable hours. The average research and memo-drafting time per motion dropped from 16 hours to 7 hours. That’s a 56% reduction. The iterative loops of re-researching were almost entirely eliminated because the initial output from the AI was far more comprehensive. The partners were getting better raw material to work with from the start.
This wasn’t just about speed. It was about cognitive load. The associates were freed from the mechanical task of crafting boolean strings and could apply their effort to analyzing the retrieved cases and structuring arguments. They shifted from data miners to legal analysts.
KPI 2: Improved Research Quality
This was the critical metric. In 8 of the 25 motions, the AI-assisted associate found a dispositive or highly persuasive case that the manually-researching associate missed completely. In one specific instance, the platform identified a recent, non-binding opinion from a neighboring district court with an almost identical fact pattern. The partner used the reasoning from that opinion to frame a novel argument that led opposing counsel to settle favorably before the motion was even decided.
That single case justified the platform’s annual subscription cost. The value wasn’t in finding more cases. It was in finding the *right* cases, the ones that exist just outside the reach of a keyword-based query.
The process felt like using a metal detector versus just digging for treasure with a shovel. Both might find something, but one is systematically scanning the entire field for signals you can’t see on the surface.
KPI 3: Tangible Return on Investment
The platform subscription was a significant five-figure annual expense, a wallet-drainer for a firm this size. The ROI calculation had to be airtight. We calculated the value of the recovered billable hours (9 hours saved per motion x 25 motions x average associate rate). We then added a risk-adjusted value for the 8 instances where “game-changing” cases were found. The first-year ROI was calculated at over 350%.
This figure doesn’t even account for the second-order effects. The firm can now handle more matters with the same headcount. Motion quality is higher, potentially leading to better case outcomes. Junior associate morale improved because their work became more substantive. These are soft benefits, but they have a real impact on retention and firm reputation.
The Lingering Caveats
This technology is not a replacement for legal expertise. It’s a tool that amplifies it. An inexperienced associate using the platform can quickly get lost in a sea of conceptually related but legally distinct cases. The system is only as good as the legal mind guiding the initial query and interpreting the final output. It provides a better map, but it doesn’t tell you where to go.
There is also a risk of over-reliance. The user interface is designed to project confidence, with relevance scores and color-coded summaries. It’s easy to accept the top-ranked case as the best answer without performing the necessary due diligence. We had to institute a firm policy requiring attorneys to read the full text of any case cited, regardless of how compelling the AI-generated summary was.
The tool is a powerful research accelerator. It is not an outsourced legal brain.