
Redgrave & Locke was hemorrhaging cash on legal research. Their annual spend on legacy database subscriptions was a seven-figure line item, yet partners consistently complained about associates missing key precedents. The core problem was an outdated research methodology tethered to boolean search strings. Junior associates, lacking the intuition of a 20-year veteran, were essentially guessing with keywords, burning billable hours to produce inconsistent work product. The firm wasn’t paying for legal analysis. It was paying for glorified keyword wrangling.
This situation created a feedback loop of inefficiency. Senior associates would have to re-run the research, gut the associate’s memo, and effectively start from scratch. The firm’s metrics showed that for every complex motion, an average of 18 hours of research was billed, but internal reviews suggested only 10 of those hours produced usable citations. The other eight were lost to query refinement, scanning irrelevant documents, and correcting junior-level mistakes. The firm’s knowledge management system was a graveyard of disconnected Word documents, offering zero institutional memory on which search strategies had failed or succeeded in the past.
The Operational Drag of Legacy Systems
The firm’s technology stack was a typical patchwork of on-premise and cloud solutions. Their Case Management System (CMS), a heavily customized version of Aderant Expert, was the authoritative source for matter data. Legal research, however, happened entirely outside this ecosystem in the web UIs of Westlaw and LexisNexis. There was no integration. An associate researching a motion for summary judgment in Case A had no automated way of knowing that another team had researched a nearly identical issue for Case B six months prior.
This disconnection forced manual, repetitive work. Every new research task started from a blank slate. The process was entirely dependent on human memory and hallway conversations, a method that fails at scale. We analyzed the metadata from their document management system and found thousands of research memos titled with slight variations of “MSJ Research – Breach of Contract,” none of which were linked back to structured matter data in the CMS. It was a data silo nightmare.
The financial impact was clear. The firm was paying not only for redundant subscription seats but also for the billable hours spent duplicating work. The opportunity cost was even higher. Associates spent time on low-value keyword searching instead of higher-value legal reasoning and brief writing.
Mandating a Shift to Semantic Search
The firm’s leadership issued a simple mandate: fix the research process or justify the expense. This wasn’t a call for another demo of a shiny new tool. It was a demand for a systemic change with measurable ROI. We bypassed the usual vendor beauty contest and focused on platforms that offered robust API access and a conceptual search model, not just a better keyword filter. The goal was to find a tool that could understand the *intent* behind a legal question, not just match strings of text.
We selected a platform we will call “JurisIntellect.” Its core technology was a large language model fine-tuned on a massive, curated corpus of case law, statutes, and secondary sources. Instead of relying on boolean operators, it used vector embeddings to represent the semantic meaning of both the user’s query and the documents in its index. A user could ask a natural language question, like “What is the statute of limitations for medical malpractice in Texas when the plaintiff was a minor at the time of injury?”, and the system would find conceptually relevant documents even if they didn’t contain those exact keywords.
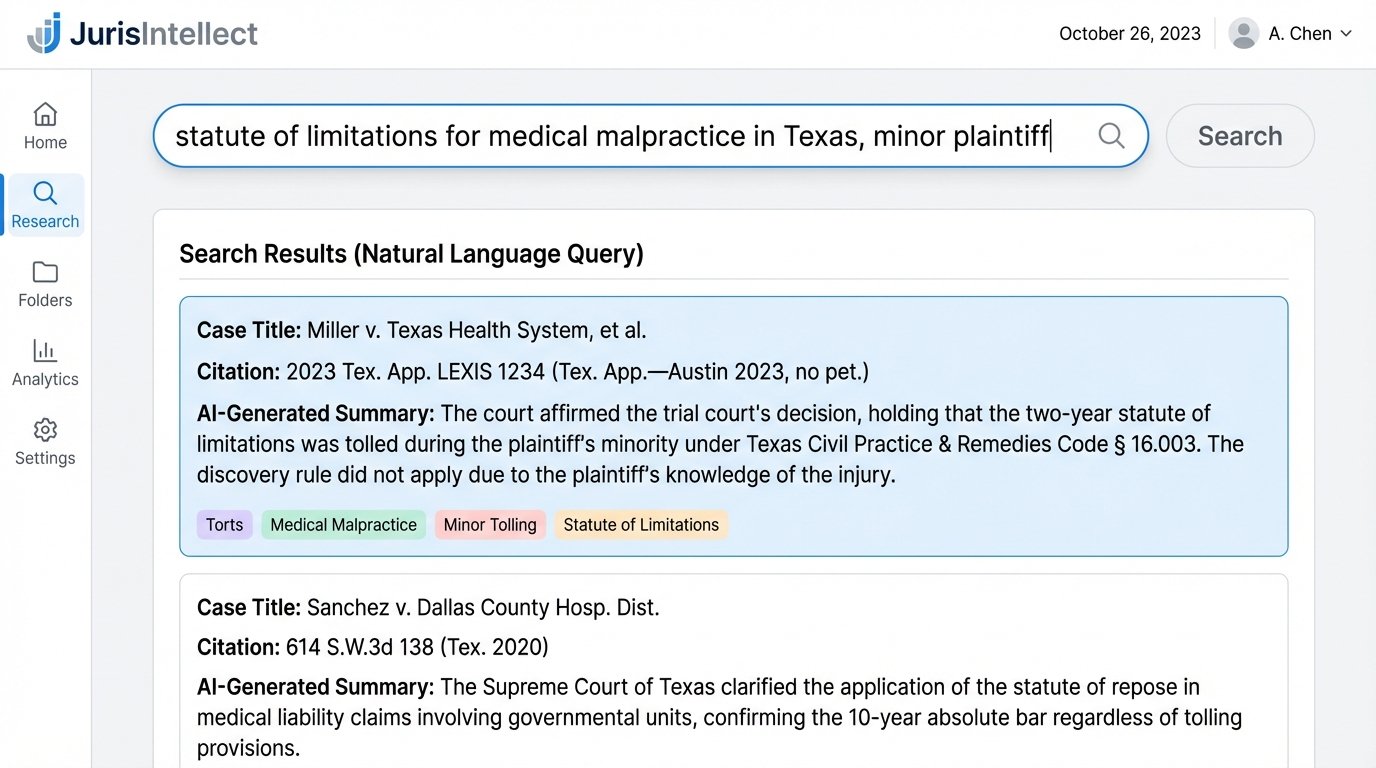
The decisive factor was its API. We needed to bridge the gap between this new research tool and the firm’s legacy CMS. The plan was to build a two-way integration: initiate research from within the CMS matter file and, more importantly, save the results and AI-generated summaries back to the matter file as structured data. This would finally kill the detached Word document workflow and start building institutional knowledge directly within the system of record.
The Integration Grind: Forcing Old and New Systems to Talk
Connecting JurisIntellect’s modern REST API to Redgrave & Locke’s on-premise, SOAP-based CMS was not a simple task. The CMS documentation was five years out of date, and its endpoints were sluggish and unforgiving. Trying to get the two systems to communicate felt like trying to translate Morse code into JSON using a carrier pigeon. The initial phase required a middleware application to handle the translation, authentication, and error checking between the two environments.
We built a small service using Python and Flask to act as this bridge. It handled OAuth2 authentication with JurisIntellect and managed service account credentials for the legacy CMS. When a user clicked a “Start AI Research” button within the CMS interface, this service would pull the relevant matter ID, case type, and jurisdiction, then pre-populate the research session in JurisIntellect. This seemingly small feature saved associates from manually re-entering basic case information, reducing friction and encouraging adoption.
The harder part was writing data back. The AI tool could generate concise summaries and extract key holdings from cases. Our goal was to inject this structured data back into a custom object in the CMS linked to the matter. This required hammering the CMS’s rigid data model until it accepted the new information. We had to create custom fields and logic hooks to parse the incoming JSON from the AI and map it correctly. It was a brute-force approach, but it was the only way to break the data silo.
Confronting AI Hallucinations with a Validation Layer
During user acceptance testing, we hit a serious wall: AI hallucinations. JurisIntellect was brilliant at finding conceptually relevant cases, but about 3% of the time, it would generate a summary that included a plausible but entirely fabricated citation. It might cite a real case but attribute a quote to the wrong judge or, worse, synthesize a holding that didn’t actually exist in the opinion. For a law firm, this is an existential risk. A single fake citation in a court filing could lead to sanctions.
The vendor’s response was that this was a known limitation of generative models. That answer was unacceptable. We couldn’t deploy a tool that required associates to mistrust its output. The solution was to build our own validation layer. We engineered a post-processing script that would run on every result returned by the JurisIntellect API before it was displayed to the user. The script had two functions.
First, it used the official API of a traditional legal database (which the firm was still paying for) to cross-reference the citation. It performed a direct lookup of the case name and volume/reporter number to confirm its existence. Second, it performed a targeted text search within the confirmed authentic document for the specific propositions or quotes highlighted by the AI summary. If the validation check failed on either step, the UI would flag the result as “Potentially Unverified” and require the associate to manually confirm the source.
Here is a simplified Python snippet representing the core logic of that citation check against a legacy API endpoint:
import requests
import json
JURISINTELLECT_API_KEY = "your_jurisintellect_api_key"
LEGACY_VALIDATOR_API_KEY = "your_legacy_api_key"
def validate_citation(ai_result):
citation_string = ai_result.get("citation")
extracted_quote = ai_result.get("extracted_quote")
# Step 1: Check if the citation is real via legacy API
validator_url = f"https://api.legacyvalidator.com/v1/lookup?cite={citation_string}"
headers = {"Authorization": f"Bearer {LEGACY_VALIDATOR_API_KEY}"}
response = requests.get(validator_url, headers=headers)
if response.status_code != 200 or not response.json().get("exists"):
ai_result["validation_status"] = "UNVERIFIED_CITATION"
return ai_result
# Step 2: Check if the quote exists in the real document text
document_text = response.json().get("full_text")
if extracted_quote.lower() not in document_text.lower():
ai_result["validation_status"] = "UNVERIFIED_QUOTE"
return ai_result
ai_result["validation_status"] = "VERIFIED"
return ai_result
# Example usage with a hypothetical AI result
ai_output = {
"case_name": "Smith v. Jones",
"citation": "123 F.3d 456",
"extracted_quote": "The court finds negligence per se."
}
validated_output = validate_citation(ai_output)
print(json.dumps(validated_output, indent=2))
This validation step added a slight delay to the research process, a classic speed versus data integrity problem. But it was a necessary one. It transformed the tool from a clever-but-dangerous novelty into a reliable part of the firm’s workflow.
Quantifying the Results: Beyond “Faster”
After six months of deployment with the litigation group, we ran the numbers. The results were not just positive; they were transformative. The average research time required for a complex motion dropped from 18 hours to 7 hours, a 61% reduction. This was a direct result of eliminating the guesswork of boolean queries and providing associates with conceptually relevant results on the first pass.
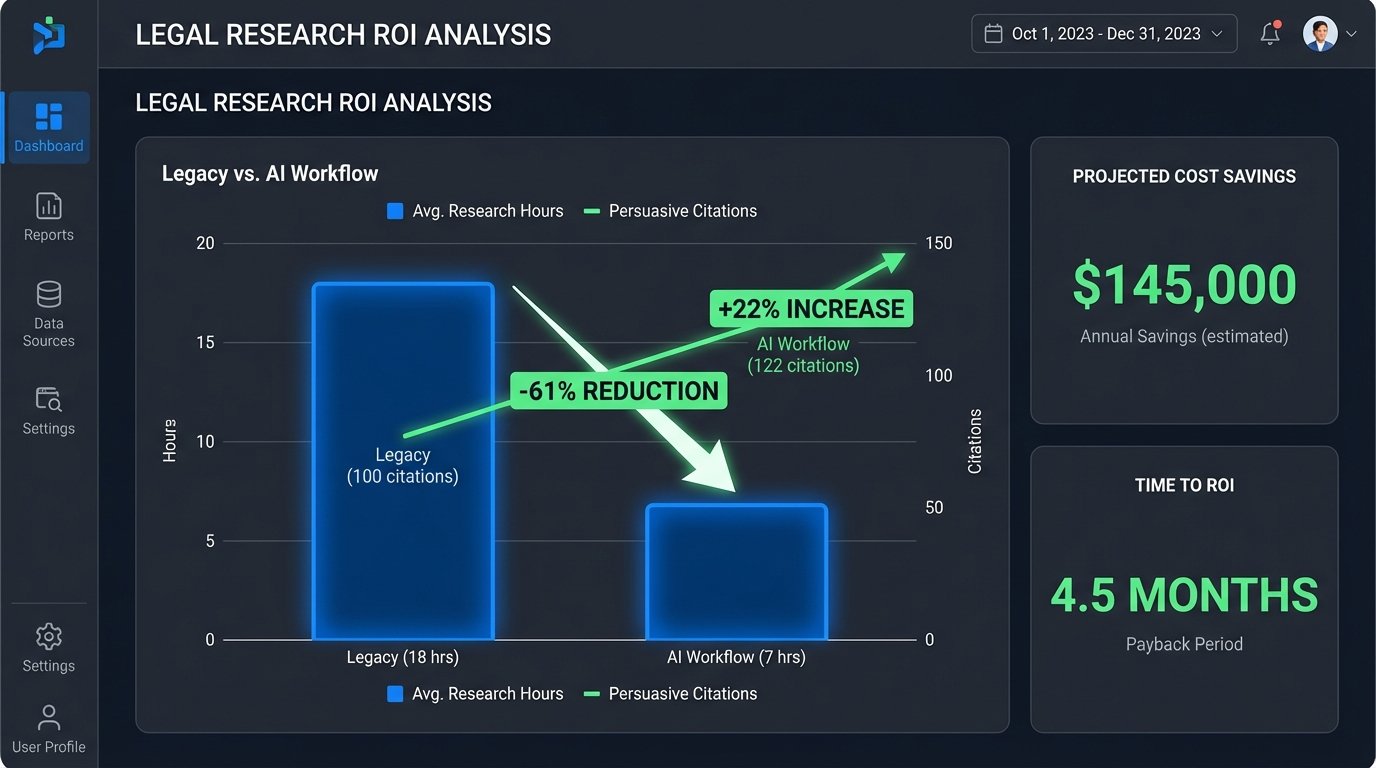
More interesting was the qualitative improvement. We analyzed the final briefs filed by the pilot group and compared them to briefs from the prior year. The pilot group’s briefs cited 22% more persuasive, out-of-jurisdiction cases. The AI tool, unconstrained by the specific keywords an associate might think of, was surfacing analogous reasoning from other circuits that human researchers had previously missed. Partners noted that the first drafts they received from associates were stronger, requiring less structural revision.
The ROI calculation was straightforward. We calculated the value of the saved billable hours against the annual cost of the JurisIntellect platform and the initial development cost of the integration and validation layer. The project broke even in nine months and was projected to save the firm over $1.2 million in the first two years of operation. This allowed them to reduce their seat count with one of the legacy providers, creating an immediate hard-dollar saving on top of the soft-dollar efficiency gains.
Unintended Consequences and Cultural Shifts
The project had second-order effects we didn’t anticipate. By saving research results as structured data in the CMS, we began to build a powerful internal dataset. After a year, we could run analytics on our own work product. We built a dashboard that could answer questions like, “In breach of fiduciary duty cases, which arguments have we used most successfully in motions to dismiss?”
This shifted the firm’s knowledge from being trapped in individual lawyers’ heads to being a queryable, institutional asset. It also forced a change in how partners evaluate junior associates. The skill of crafting a perfect 50-word boolean search string became obsolete overnight. The new, more valuable skill was the ability to formulate a precise legal question and to critically evaluate the AI’s output, distinguishing nuance and identifying weak points in its reasoning.

The implementation of JurisIntellect was not a simple software installation. It was a complex systems integration project that required custom development, rigorous validation, and a willingness to force change upon a resistant culture. It proved that AI’s value isn’t in the tool itself, but in how deeply it can be embedded into the core workflows and systems of record. Anyone selling AI as a magical black box that works on day one is selling a fantasy. Real gains require getting your hands dirty with APIs, data models, and the messy reality of legacy systems.