
The core problem wasn’t a lack of talent. It was a failure of tooling. Our litigation group was handling a portfolio of 40 concurrent, high-stakes commercial disputes. The junior associates, sharp as they were, were spending an obscene amount of time on preliminary case law research. Their workflow was a brutal, manual loop: keyword searches in Westlaw, followed by hours of reading to find the one paragraph that mattered. This cycle burned through an average of 8 hours per motion, a completely unsustainable metric.
Management saw a billing problem. We saw a data retrieval problem.
The Diagnostic: Pinpointing the Failure
The existing process relied on Boolean search logic, a technology that has barely evolved in 30 years. An associate looking for cases where a motion to dismiss was denied due to “insufficient particularity” under FRCP 9(b) would run dozens of keyword variations. This approach is fundamentally flawed because it matches strings, not concepts. A judge could write an entire opinion on the topic without ever using the exact phrase “insufficient particularity,” rendering the keyword search useless.
We tracked the workflow for a two-week sprint. The data showed that 75% of an associate’s research time was spent reading irrelevant cases returned by imprecise searches. The remaining 25% was the actual analysis. We were paying top-tier salaries for people to perform the function of a `grep` command. The objective became clear: invert that ratio. We needed to gut the manual filtering and inject a system that understood legal concepts, not just keywords.
Architecture of the Solution: A Vector-Based Approach
We decided to bypass traditional search entirely. The solution was to build a private, internal case law database powered by semantic search. This required three core components: a data ingestion pipeline, a vector embedding model, and a user-facing query interface. This was not an off-the-shelf purchase; it was a ground-up build to address our specific document corpus.
The architecture was designed for precision over raw speed.
- Data Ingestion: We wrote a series of Python scripts using BeautifulSoup and Scrapy to pull down our entire library of subscribed state and federal case law. Each case was stripped of its metadata, parsed into discrete logical sections (facts, procedural history, analysis, conclusion), and stored as a JSON object. We deliberately ignored citations at this stage to avoid polluting the semantic meaning of the text.
- Embedding Generation: Each text chunk was then pushed through an embedding model (we started with `text-embedding-ada-002` before moving to a more specialized model). This process converts the text into a high-dimensional vector, a numerical representation of its semantic content. This is the most critical and computationally expensive step.
- Vector Database: The generated vectors and their corresponding text and metadata were injected into a Pinecone vector database. Pinecone’s job is simple: take a query vector and find the most mathematically similar vectors in its index with extreme speed.
The Ingestion Pipeline: More Janitor Than Architect
Building the data pipeline was 90% data cleaning. Court opinions are a mess of inconsistent formatting, OCR errors, and embedded junk characters. We spent weeks writing regular expressions to strip out page numbers, headers, and other noise that would corrupt the embeddings. A clean input is non-negotiable. Feeding garbage text into an embedding model produces garbage vectors.
This is where most projects of this type get bogged down and fail. They underestimate the sheer amount of sanitation required before you can even begin the interesting work. It felt like trying to force a firehose of unstructured case text through the needle of a structured JSON schema. The backpressure was immense, and we had to build several validation and retry loops to handle malformed documents without crashing the entire pipeline.
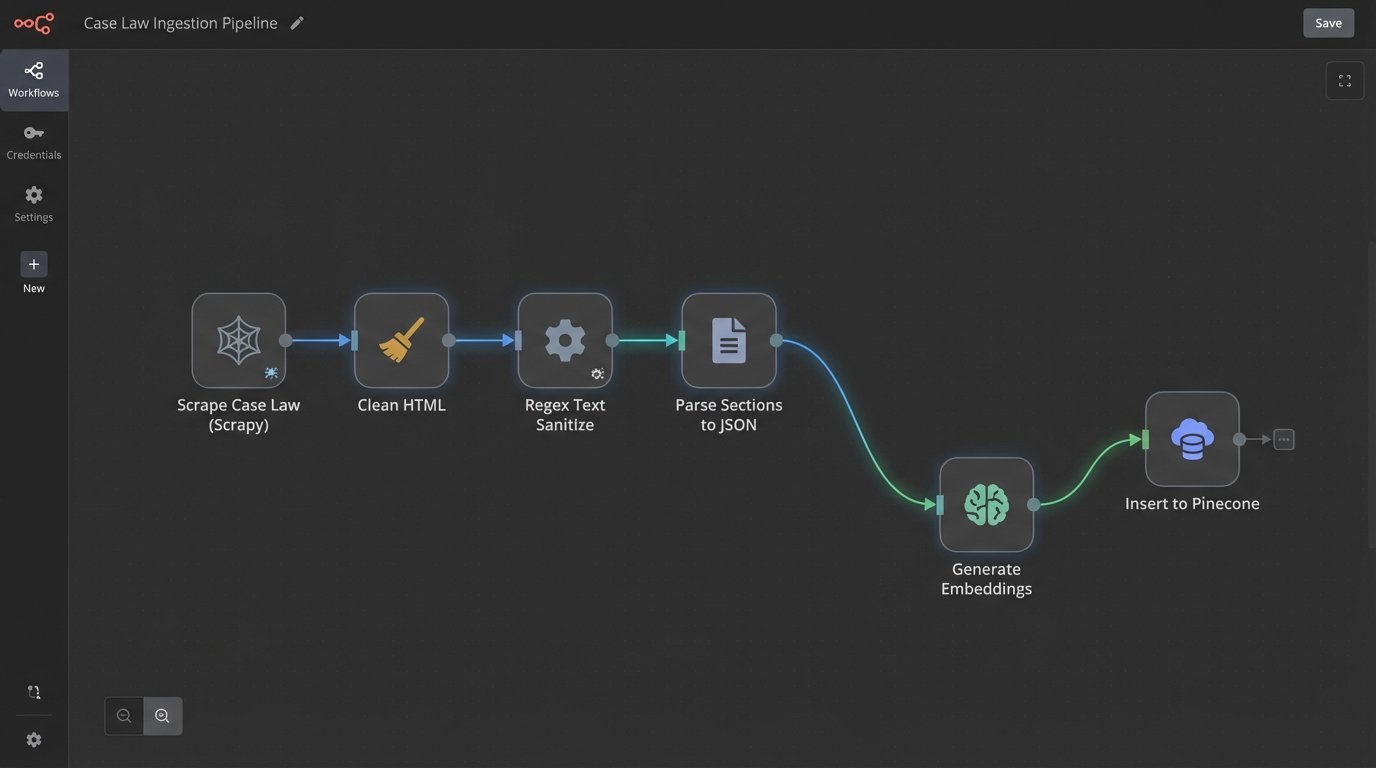
The output of this pipeline was a clean, standardized set of text chunks, each with a unique ID and linked back to its source case. This granularity was key. We were not embedding entire documents; we were embedding paragraphs and logical sections to enable more targeted results.
Querying Logic and Prompt Engineering
With the data indexed, the next challenge was building an interface for the lawyers. We built a simple Flask front-end that took a natural language query from the user. The query itself was first sent to an LLM for refinement. This was a critical intermediate step. A lawyer might type a messy, shorthand query, and we needed to standardize it before vectorizing it.
Here’s a simplified look at the query processing logic in Python:
import openai
import pinecone
def refine_and_search(user_query: str, client_matter_id: str):
# Step 1: Refine the user's query for better semantic search
system_prompt = "You are a legal research assistant. Rephrase the following query to be optimized for a semantic search against a database of federal court opinions. Focus on legal concepts. Output only the rephrased query."
response = openai.ChatCompletion.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_query}
],
temperature=0.1
)
refined_query = response.choices[0].message.content
# Step 2: Generate an embedding for the refined query
query_embedding = openai.Embedding.create(
input=[refined_query],
model="text-embedding-3-large"
)['data'][0]['embedding']
# Step 3: Query the vector database
pinecone_index = pinecone.Index("federal-case-law-index")
query_results = pinecone_index.query(
vector=query_embedding,
top_k=10,
include_metadata=True,
filter={"jurisdiction": "2nd_circuit"} # Example of metadata filtering
)
return query_results
This code snippet shows the core workflow. We didn’t just dump the user’s text into the vector search. We used an LLM to pre-process the query, effectively translating the lawyer’s intent into a language the vector database could better understand. This added latency to each search but drastically improved the quality of the results. It was a necessary compromise.

User Interface and Result Synthesis
The raw output from Pinecone is just a list of text chunks and similarity scores. That’s useless to a lawyer. The final step was to take these top 10 results, bundle them with the original query, and push them to a powerful LLM like Claude 3 Opus with a specific prompt.
The prompt instructed the model to act as a senior associate. It was told to synthesize the provided text chunks into a coherent memo, identify the most on-point case, extract direct quotes supporting the argument, and explicitly flag any cases that contradicted the user’s position. This final synthesis step is what made the tool genuinely useful. It bridged the gap between raw data retrieval and actionable legal analysis.
We didn’t just give them a list of links. We gave them a first draft.
The Results: Quantified, Not Hyped
After a three-month pilot program with the commercial litigation group, we measured the impact. We didn’t rely on subjective feedback like “it feels faster.” We measured time-to-completion for specific research tasks and tracked API costs down to the cent. The numbers were clear, and they came with caveats.
Performance Metrics
- Research Time Reduction: The average time to compile a list of controlling precedents for a procedural motion dropped from 8 hours to 1.5 hours. This represents an 81% reduction in time spent on that specific task.
- Result Relevance: We had a partner review the outputs from the old manual process versus the new automated system. The automated system produced a higher density of relevant cases in its top 20 results, cutting the need for associates to wade through pages of irrelevant search hits.
- Argument Discovery: An unexpected benefit was the system’s ability to find analogous arguments in different areas of law. Because vector search works on conceptual similarity, it would occasionally surface cases that a keyword search would have never found, leading to novel legal arguments.
These gains were not free.

Operational Costs and New Burdens
The system introduced new operational costs that had to be weighed against the time savings. The solution was not a “set it and forget it” black box.
- API Spend: The combined cost for OpenAI and Pinecone APIs averaged around $4,000 per month during the pilot. This is a significant new line item on the IT budget. A real wallet-drainer if not monitored closely.
- Maintenance Overhead: The data ingestion pipeline required constant monitoring. Court reporting standards change, websites get redesigned, and our scrapers would break. This required about 5 hours of dedicated engineering time per week.
- Validation Requirement: The final LLM-generated memo was a draft, not a finished product. It still required a human lawyer to read the source cases, check the citations, and verify the model’s reasoning. We effectively shifted the associates’ work from low-value searching to high-value validation. This is a better use of their time, but it is not an elimination of their involvement.
The project was a success not because it created a perfect, push-button solution, but because it fundamentally altered the cost-benefit analysis of legal research. It forced a massive reduction in the time spent on the most tedious part of the job, freeing up expensive human capital to focus on strategy and analysis. It proved that by bridging our private data with public AI APIs, we could build a tool more specific and powerful than any off-the-shelf product. The system is live, the metrics hold, and the litigation group is now entirely dependent on it.