
Most conversations about AI in legal research are functionally useless. They orbit around vague promises of efficiency, powered by generic Large Language Models (LLMs) that treat a Supreme Court opinion and a Reddit post with the same semantic weight. The actual engineering happening behind the scenes is far more specific and confronts a brutal reality: legal data is a structured, adversarial mess. Anyone peddling a one-size-fits-all LLM wrapper as a solution is either naive or selling something.
The core problem is authority. A generative model, by its nature, synthesizes probable text. It does not verify truth. For legal work, where a single misplaced citation can torpedo a motion, this is a non-starter. The interesting work isn’t about making a chatbot that sounds like a lawyer. It’s about building systems that can reason over a corpus of verifiable legal documents, trace every assertion back to its source, and do it without hallucinating a fictional case law precedent.
Here are the technical shifts that actually matter.
Knowledge Graph Grounding
Vector search is the current default for semantic retrieval. It turns documents into numerical representations and finds the closest matches to a query. This is effective for finding conceptually similar documents but it has no inherent understanding of legal structure. It can’t distinguish a dissenting opinion from a majority holding if the language is similar. This approach creates a system that is directionally correct but factually unreliable.
A knowledge graph corrects this by storing information as a network of entities and relationships. We don’t just index text. We explicitly map entities like Judge Kavanaugh, relationships like authored, and other entities like Dobbs v. Jackson. This creates a queryable, logical structure of the legal world. You can ask questions that require reasoning, not just keyword matching: “Show me all cases authored by Judge Kavanaugh that cite Roe v. Wade and were later overturned.”
The emerging best practice is a hybrid model. A query first hits a vector database to find a set of semantically relevant documents. Then, the system uses the entities extracted from those documents to run a structured query against the knowledge graph. This forces the generative model to ground its response in the verifiable facts and relationships from the graph. It’s a logic check that prevents the model from inventing plausible but incorrect information.
Building and maintaining that graph is the expensive part.
The Data Ingestion Bottleneck
Populating a legal knowledge graph is a heavy data engineering lift. It requires sophisticated Named Entity Recognition (NER) models fine-tuned on legal text to correctly identify judges, courts, parties, statutes, and case citations. The process involves stripping text from court PDFs, running it through an NER pipeline, resolving entities (e.g., ensuring “J. Smith” and “Judge John Smith” map to the same node), and then loading these connections into a graph database like Neo4j.
Relying on vector search alone is like building a library where all the books are shredded into individual sentences and thrown into a pile. You can find sentences that feel right, but you’ve lost the binding, the chapter, and the author’s original intent. The graph rebuilds that structure, forcing the machine to read the book, not just the confetti.
This pipeline is brittle and requires constant monitoring. A minor change in court document formatting can break the parser, poisoning the data downstream. The upfront cost in development hours and computational resources is significant before a single query can be run. Many firms will opt to license access to a pre-built graph from a vendor rather than attempt this in-house.
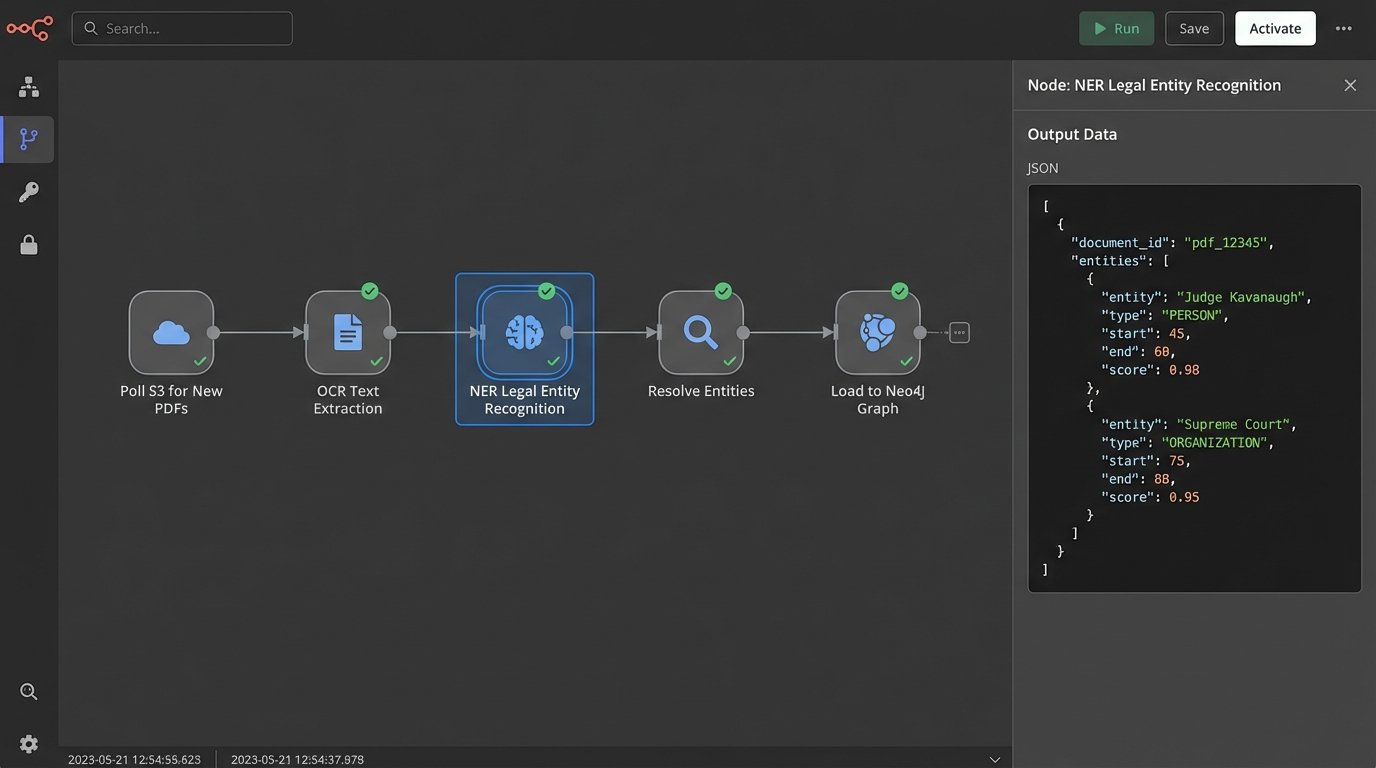
Multi-Modal Retrieval-Augmented Generation (RAG)
Legal research is not confined to text. Case files are a chaotic mix of PDFs, expert witness reports, deposition transcripts, photographs, financial statements, and emails. Standard RAG systems that only process text are blind to this critical information. The next phase of development is building systems that can ingest and reason across these different data types simultaneously.
A multi-modal system can answer a query like, “Summarize all communications from John Doe in November that mention Project X, and cross-reference any mentions with balance sheets from the same period.” To do this, the system needs a complex ingestion chain. It runs scanned documents through Optical Character Recognition (OCR), images through object detection models to identify relevant items, and audio files through transcription and diarization APIs to separate speakers.
Each piece of content is then converted into a vector embedding and stored with rich metadata. The metadata is key. It tags the content with its source, type, date, and any extracted entities. When a query comes in, the system retrieves a diverse set of source materials, text, image, and audio, before feeding it all into an LLM to synthesize a single, unified answer.
The real challenge is data normalization and the sheer cost of processing.
Architectural Hurdles
Building a multi-modal RAG pipeline requires orchestrating multiple specialized AI models. You need a document layout analysis model to handle complex PDFs, a transcription service for audio, and a vision model for images. Each step introduces potential for error. A bad OCR scan can lead to a factual error in the final summary. A mistranscribed name can break the link to other documents.
The compute cost is also a factor. Processing a one-hour audio deposition or a 500-page scanned document is orders of magnitude more expensive than processing a simple text file. Scaling this across an entire firm’s caseload requires a serious budget for cloud services. This isn’t something you can run on a spare server in the office. It demands a robust, scalable cloud architecture from the ground up.
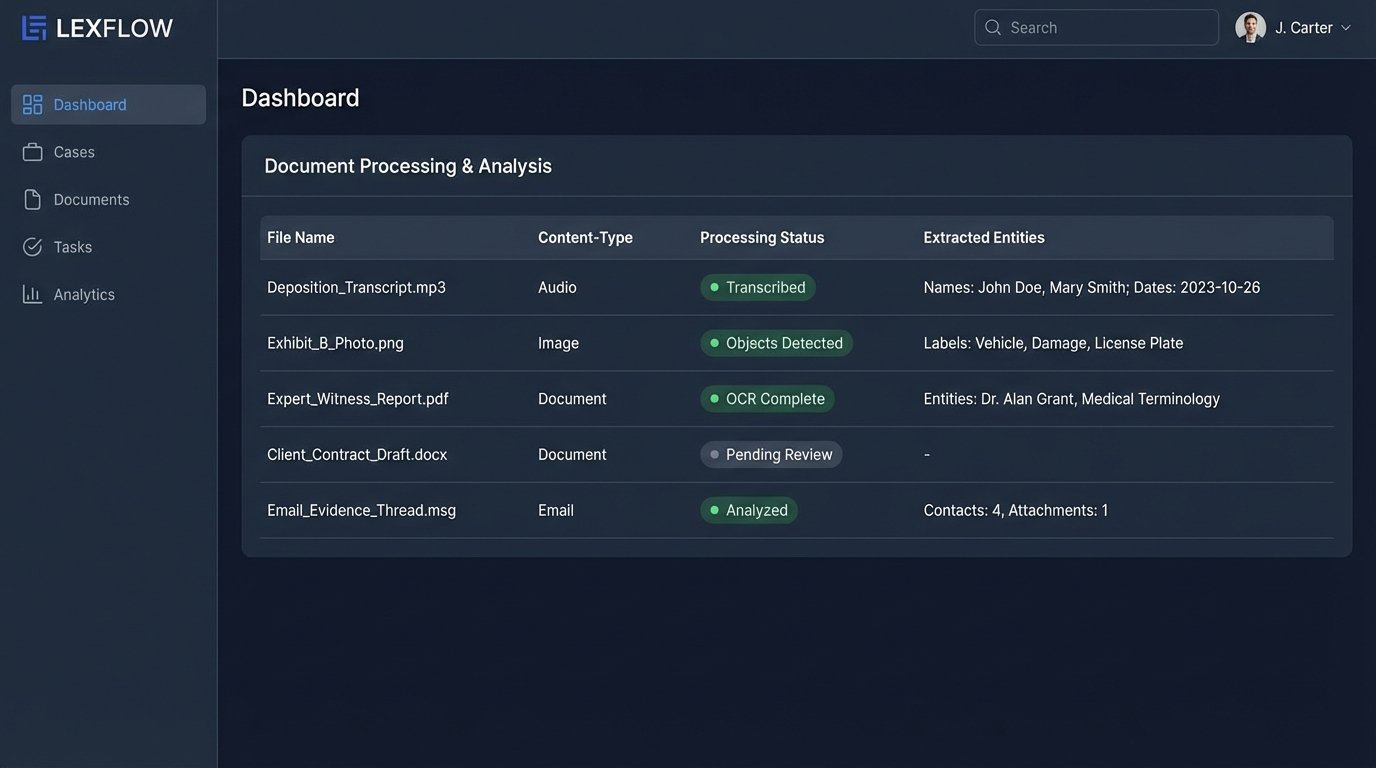
Agentic Workflows
The current generation of AI tools are passive. They respond to a single, specific prompt. Agentic workflows represent a move toward proactive, multi-step problem solving. An “agent” is an AI system given a high-level objective and the autonomy to break it down into a series of tasks, execute them, and learn from the results.
For example, instead of asking a researcher to “find cases related to defective airbags,” you task an agent with the objective: “Assess the litigation risk for our automotive client regarding the new ‘Model Z’ airbag recall.” The agent would then autonomously execute a plan. It might start by searching federal dockets for initial lawsuits, then expand to state courts, identify and retrieve key complaints and motions, summarize the legal arguments being used by plaintiffs, and finally generate a report synthesizing its findings, complete with citations.
These systems use an LLM as a reasoning engine to decide the “next best action.” The agent has access to a toolkit, which could include a web search API, a Westlaw or LexisNexis API, a document analysis function, and an internal document management system. It chains these tools together to achieve its goal.
Here’s a simplified JSON representation of a potential task list an agent might generate:
{
"objective": "Assess litigation risk for 'Model Z' airbag recall.",
"tasks": [
{
"id": 1,
"tool": "pacer_api_search",
"parameters": {
"query": "\"Model Z\" AND \"airbag\" AND \"defect\"",
"date_range": "last_180_days"
},
"status": "pending"
},
{
"id": 2,
"tool": "document_retrieval",
"parameters": {
"case_ids": "dependency_on_task_1"
},
"status": "pending"
},
{
"id": 3,
"tool": "summarize_and_extract_arguments",
"parameters": {
"documents": "dependency_on_task_2",
"keywords": ["negligence", "breach of warranty", "strict liability"]
},
"status": "pending"
},
{
"id": 4,
"tool": "generate_report",
"parameters": {
"synthesis_data": "dependency_on_task_3"
},
"status": "pending"
}
]
}
The primary risk here is control. An unconstrained agent can rapidly burn through expensive API calls or get stuck in a loop. Building effective guardrails and monitoring systems is critical to making these workflows practical. They must have clear stop conditions and human oversight checkpoints.
Predictive Analytics for Judicial Behavior
Early attempts at legal predictive analytics focused on crudely predicting case outcomes as win or lose. These models were often inaccurate and not particularly useful. The new trend is to focus on micro-predictions of judicial behavior based on a deep analysis of a judge’s complete written record.
These systems ingest every motion, order, and opinion a specific judge has ever written. Using NLP, they analyze patterns. How does this judge typically rule on a motion to dismiss in an intellectual property case? Which specific precedents do they cite most often when ruling on summary judgment? Is their language more favorable to plaintiffs or defendants in employment disputes? This is about quantifying judicial tendencies.
The output is not a prediction of the final case outcome. It is a probabilistic forecast of how a judge might respond to a specific legal argument or motion. For a litigator, this is gold. It informs strategy on which arguments to emphasize, which cases to cite, and even which motions are worth filing in the first place. It provides a data-driven edge to legal strategy that goes beyond anecdotal experience.
The catch is that this requires an immense, clean, and well-structured dataset of court documents, tagged by judge, case type, motion type, and outcome. Building this dataset is a slow, expensive process. Vendors who have already done this work will have a significant advantage.
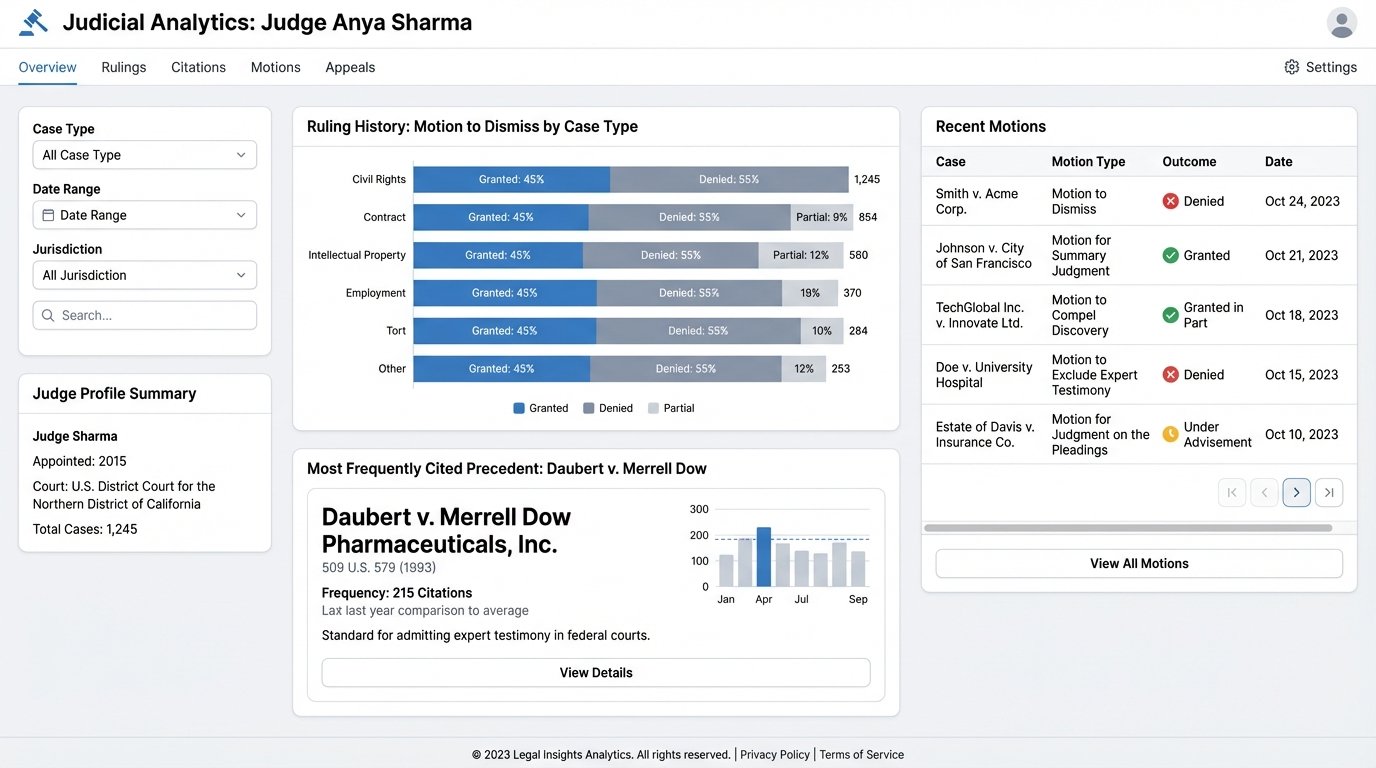
Real-Time Regulatory and Statutory Mapping
Staying current with changes in law and regulation is a massive manual effort. Existing alert services are typically based on simple keyword matches, resulting in a high volume of low-relevance noise. The forward-looking approach is to build a dynamic dependency graph that maps a firm’s active matters to the specific statutes and regulations that govern them.
When a new bill is passed or a section of the Code of Federal Regulations is amended, the system does not just send an alert. It performs an impact analysis. It identifies the specific textual change in the law, traverses the dependency graph to find all client matters that are linked to that section of code, and automatically routes an alert to the responsible attorneys. This system can answer the question: “How does this morning’s update to 17 CFR § 240.10b-5 affect our active securities litigation cases?”
This transforms compliance from a reactive, manual process into a proactive, automated one. It requires tight integration between the external legal data feeds and the firm’s internal case management system. The technical challenge is creating and maintaining the links in the graph. It’s a data synchronization problem that demands a robust data pipeline and a bulletproof ontology for classifying legal concepts.
These systems are complex to build and maintain. They are not simple plugins. They represent a fundamental shift in how a firm manages its data, but the payoff is a direct reduction in risk and manual labor.