
Most conversations about automating legal research start with a slick sales demo and end with a disappointing trial. The core problem is not the technology. It is the flawed assumption that these tools are plug-and-play replacements for manual effort. They are not. True automation is an engineering discipline that forces you to dismantle, scrutinize, and then rebuild the research workflow from the ground up. It is about building a system, not just buying a subscription.
The goal is to create a repeatable and defensible data pipeline that ingests raw case law, validates its relevance, and injects it directly into your firm’s knowledge base. Anything less is just a faster way to find the same ten cases everyone else finds. This is not about speed. It is about creating a proprietary, structured dataset of legal precedent that gives you an analytical edge.
Groundwork: Scoping the Data and API Access
Before you write a single line of code, you must define the boundaries of your data sources. Relying solely on the web-based interfaces of legacy providers is a dead end for automation. Their value is in their curated datasets, but their interfaces are built for human interaction, not systematic data extraction. Scraping them is brittle and a violation of most terms of service. You will get your firm’s IP address banned.
Real automation demands programmatic access through an Application Programming Interface (API). This is the first and most critical vetting point for any research provider. If they do not offer a well-documented, stable API, they are not a serious option for integration. Look for providers that offer direct access to their corpus, not just a glorified search endpoint. The difference is significant. A search API gives you answers to questions. A data API gives you the raw material to find your own answers.
You must also rigorously define the jurisdictional and temporal scope. Do you need all federal appellate decisions from the last 20 years, or just decisions from the Southern District of New York related to securities fraud since the Dodd-Frank Act? Pulling the entire firehose of data is a wallet-drainer and creates a massive data engineering problem. Be precise. Your initial queries should be narrow, targeting the most valuable data first. You can always broaden the scope later. Starting too broad is a common and expensive mistake.
Step 1: Vet the Research Platform on Technical Merit
Evaluating AI research tools requires you to ignore the marketing slicks and go straight to the developer documentation. The quality of their API docs is a direct proxy for the quality of their engineering. If the documentation is vague, outdated, or lacks clear examples, walk away. Your engineers will waste hundreds of hours trying to reverse-engineer a system the provider could not be bothered to document.
Examine the API’s filtering and query capabilities. The key question is whether you can perform granular filtering on the server side before the data is sent to you. Forcing your system to download thousands of irrelevant cases just to filter them locally is grotesquely inefficient. It burns through your API quotas, increases network latency, and requires more powerful processing on your end. The API must allow you to filter by court, date range, judge, and ideally by legal topic or keyword directly in the request.

The data format returned by the API is another critical detail. JSON is the standard, but the structure of that JSON object is what matters. Is the case citation a simple string, or is it a structured object with fields for volume, reporter, and page number? Are headnotes provided as a block of text or as an array of discrete, classifiable legal points? Poorly structured data requires a huge amount of post-processing and parsing logic on your side, which introduces complexity and potential failure points.
Step 2: Engineer the Integration and Error Handling
The integration layer is the bridge between the external research API and your firm’s internal systems. It should be built as a standalone service, not tightly coupled to your case management system. This architectural choice is non-negotiable. It allows you to swap out the research provider in the future without a full rewrite. Think of it like building a standardized adapter plate so you can connect to different engines without re-engineering the entire vehicle chassis.
Your initial connection will likely be a simple script. A basic Python implementation using the `requests` library can handle the fundamentals of making an API call. The code will need to construct the request with the correct headers for authentication (usually an API key) and the query parameters that define your search.
import requests
import os
import time
API_KEY = os.environ.get("LEGAL_API_KEY")
API_ENDPOINT = "https://api.legalresearchprovider.com/v1/cases/search"
def fetch_case_data(jurisdiction, keyword):
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
params = {
"jurisdiction": jurisdiction,
"query": keyword,
"date_after": "2020-01-01"
}
max_retries = 3
for attempt in range(max_retries):
try:
response = requests.get(API_ENDPOINT, headers=headers, params=params, timeout=30)
response.raise_for_status() # Raises an HTTPError for bad responses (4xx or 5xx)
return response.json()
except requests.exceptions.HTTPError as e:
if e.response.status_code == 429: # Rate limit error
wait_time = 2 ** attempt # Exponential backoff
print(f"Rate limited. Retrying in {wait_time} seconds.")
time.sleep(wait_time)
else:
print(f"HTTP error occurred: {e}")
return None
except requests.exceptions.RequestException as e:
print(f"A network error occurred: {e}")
return None
print("Failed to fetch data after multiple retries.")
return None
# Example usage:
sdny_cases = fetch_case_data("sdny", "summary judgment standard")
if sdny_cases:
print(f"Found {len(sdny_cases.get('results', []))} cases.")
The sample code shows a critical component: error handling. APIs fail. They become unavailable, they change without notice, and they will absolutely rate-limit you if you make too many requests too quickly. Your code must anticipate this. The implementation of retry logic with exponential backoff is not optional. It is the minimum requirement for a production-grade system. A failure to fetch data should be a logged, controlled event, not a script-crashing exception that brings down the entire workflow.
Step 3: Parse, Structure, and Store the Data
The JSON payload you get back from the API is just a starting point. It is transient and unstructured for your purposes. You need to strip the critical information and load it into a permanent, structured database. This process, often called ETL (Extract, Transform, Load), is where raw data becomes a valuable asset.
Your script must parse the JSON, pulling out specific fields: case name, official citation, court, decision date, judges, and the core text or summary. During this transformation step, you should also normalize the data. For example, court names might come in various formats (“U.S. District Court for the Southern District of New York”, “SDNY”, “S.D.N.Y.”). You must standardize these to a single, consistent identifier to make querying reliable.
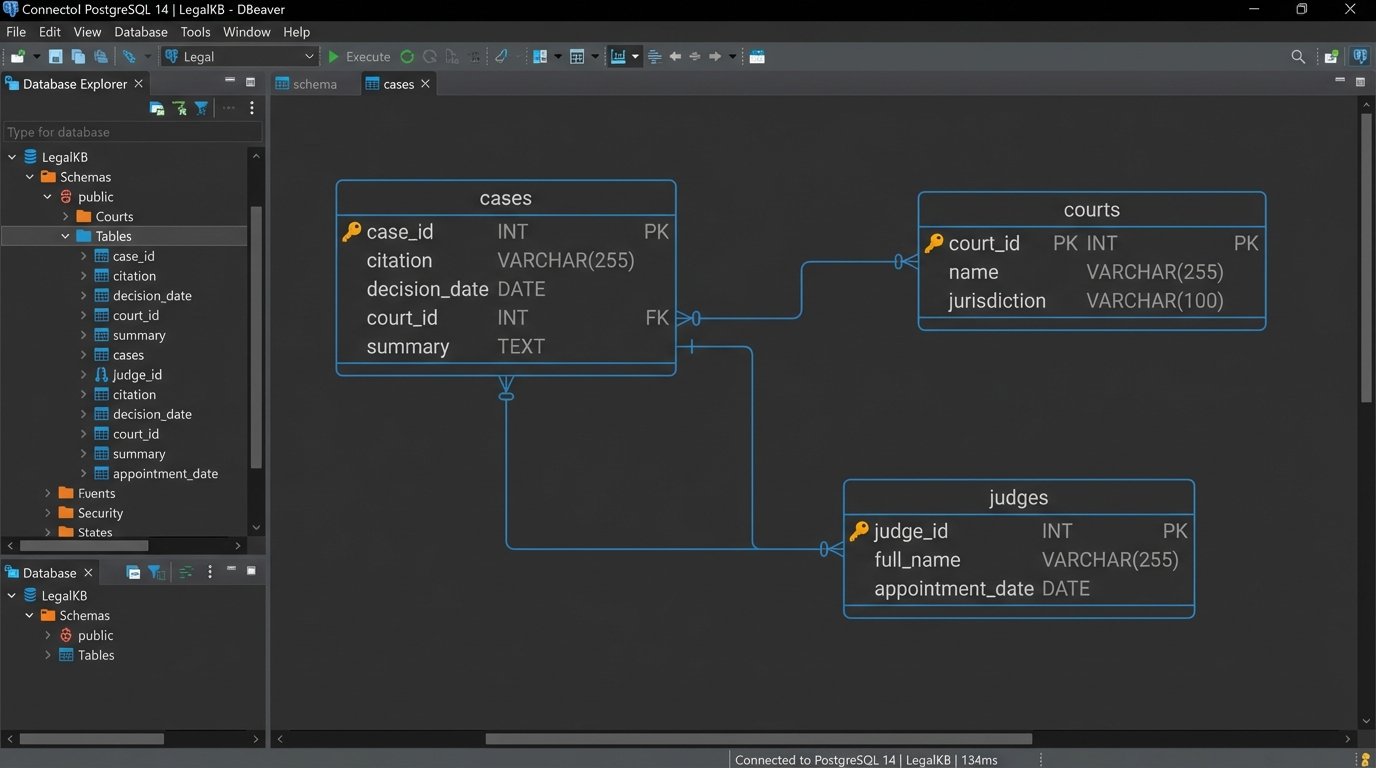
Resist the temptation to dump the raw JSON into a NoSQL document store like MongoDB. While it is fast to get started, it pushes the problem of structure downstream. You will pay for this convenience later with complex, slow, and difficult-to-maintain queries. A traditional relational database like PostgreSQL is almost always the better choice here. Define a clear schema with tables for cases, courts, judges, and jurisdictions. Enforcing structure at the database level ensures data integrity and makes complex analytical queries possible. Building this model is like laying the foundation for a skyscraper. It feels slow, but it’s the only way to build something tall and stable.
Step 4: Implement a Human-in-the-Loop Validation Layer
No AI is perfect. Large language models, which power many of these tools, can “hallucinate” facts and generate plausible but incorrect case citations. Relying on their output without verification is professional malpractice. Your automated system must include a validation step, and for critical applications, that step must involve a human.
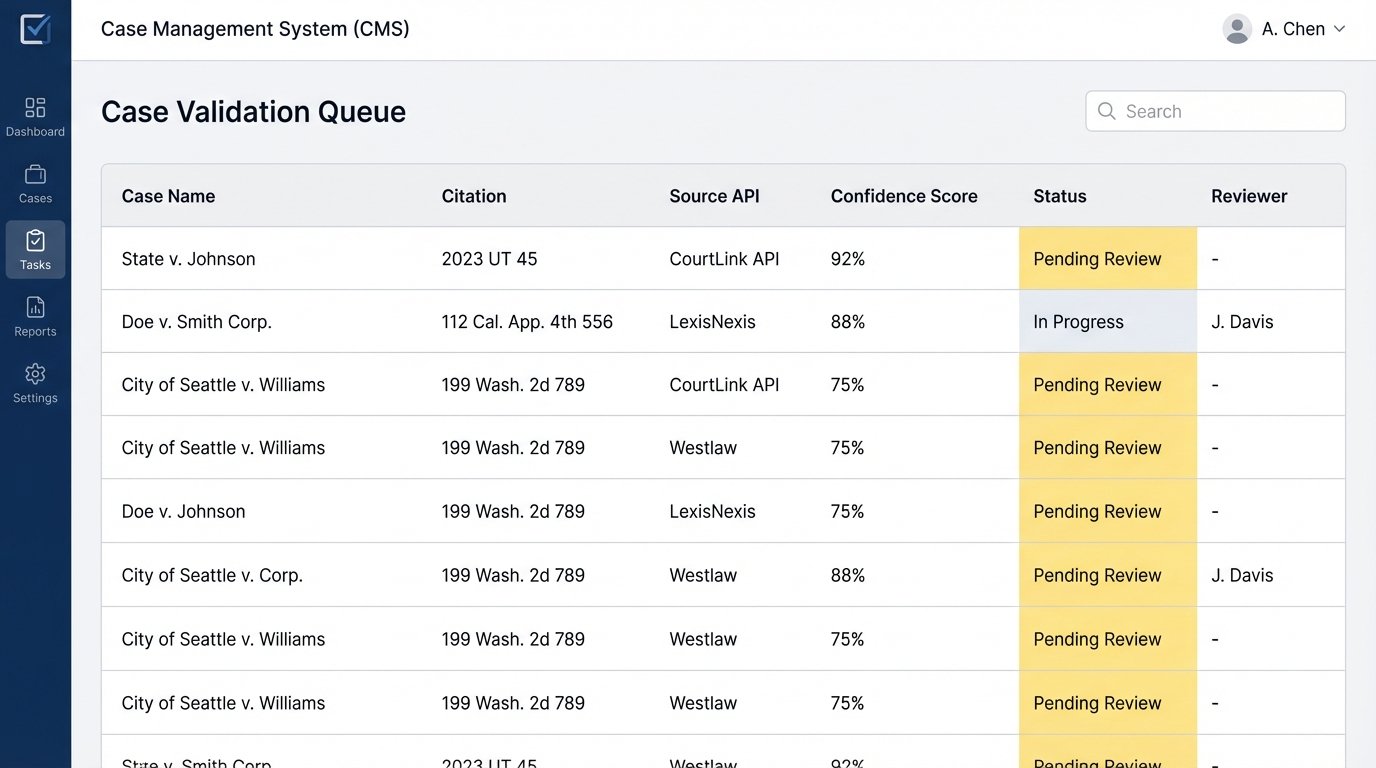
The system should be designed to flag results for review based on a confidence score or other heuristics. A case returned by the API with a non-standard citation format should automatically be routed to a paralegal’s work queue for verification. A case that is highly relevant to a query but is from an unexpected jurisdiction might also be flagged. This is not about manually re-doing the research. It is about a targeted review of exceptions.
You can automate parts of the validation. For example, you can write a service that takes a found citation and attempts to look it up on a free, reliable source like Google Scholar or the Caselaw Access Project to confirm its existence. This logic-check can significantly reduce the manual review load. The goal is to build a defensible workflow. When a partner asks where a specific case in a brief came from, the answer must be a clear audit trail from the API call, through the validation step, to the final document, not just “the AI found it.”
Step 5: Deploy and Integrate with Case Management
The final stage is to push this validated, structured data into the systems your lawyers use every day. This typically means integrating with your firm’s Case Management System (CMS) or document management system. This is often the most painful part of the project. Many legal-specific platforms have archaic, sluggish, and poorly documented APIs.
The integration should be a one-way push from your new case law database to the CMS. When a new, relevant case is validated, a background job should trigger. This job will format the case data to match the requirements of the CMS API and create a new entry linked to the relevant matter. For example, it might add a note to a case file with the citation and a link to the full text.
These integration jobs must be asynchronous. Do not run them in real-time as cases are found. The CMS API will be a bottleneck. Use a task queue like Celery with RabbitMQ or Redis to manage these jobs. This decouples the research system from the CMS. If the CMS goes down for maintenance, the research jobs will simply queue up and execute when it comes back online. Without this buffer, an outage in one system would cascade and break the entire pipeline.
From Automated Research to Legal Analytics
Completing this process does more than speed up research. It fundamentally changes its nature. You are no longer just finding answers. You are building a proprietary, structured database of case law tailored to your firm’s specific practice areas. This asset is the foundation for genuine legal analytics.
With this structured data, you can start to answer much more sophisticated questions. Which arguments are most successful before a particular judge? How have rulings on a specific statute evolved over the last five years in the Ninth Circuit? These are questions that cannot be answered with a simple search bar. They require a clean, normalized, and queryable dataset. Building the automation pipeline is the hard, necessary work to create that dataset. The efficiency gain in research is the immediate benefit, but the long-term strategic advantage comes from the data asset you create along the way.