
Most legal tech vendors pitch case law automation as a finished product. It is not. What they sell is a sophisticated keyword filter layered with basic natural language processing that identifies entities and sentiment. This approach fails to address the fundamental problem: a judicial opinion is a chaotic data source, and its value is locked behind unstructured prose. True automation isn’t about finding a document faster; it’s about systematically gutting that document for its logical components and making them machine-readable.
The core task is to convert narrative text into a structured dataset. Without this conversion, any “analysis” is just a high-speed skim reading exercise.
Deconstructing the “AI-Powered” Façade
Commercial legal research platforms market their automation heavily. They point to features that flag negative treatment or suggest related cases. Under the hood, these systems are executing fairly standard NLP tasks. They run named-entity recognition (NER) to find names of judges, courts, and companies. They apply topic modeling to categorize a case into legal subjects and sentiment analysis to guess if the tone is positive or negative toward a cited authority.
This is a good start, but it is dangerously superficial. A generic NLP model does not understand the difference between a holding and dicta. It cannot distinguish a core factual predicate from a hypothetical example used by the judge. The result is a system that presents information without the critical context required for legal strategy. You get a firehose of data with no pressure regulator.
The dependency on these black-box systems creates an operational risk. When the algorithm changes how it weighs factors or classifies a case, your research outputs change without warning or explanation. You cannot audit the logic, you cannot fine-tune the model for your specific practice area, and you are entirely reliant on the vendor’s development priorities. This is not a platform for serious analytical work.
It’s an expensive subscription for a slightly improved search bar.
The Real Target: Structured Legal Data
The objective of case law automation should be to transform an opinion from a block of text into a predictable data object. Every case should be processed and stored in a consistent format that allows for computational analysis, not just manual reading. The goal is to build a private, structured data asset from public, unstructured information.
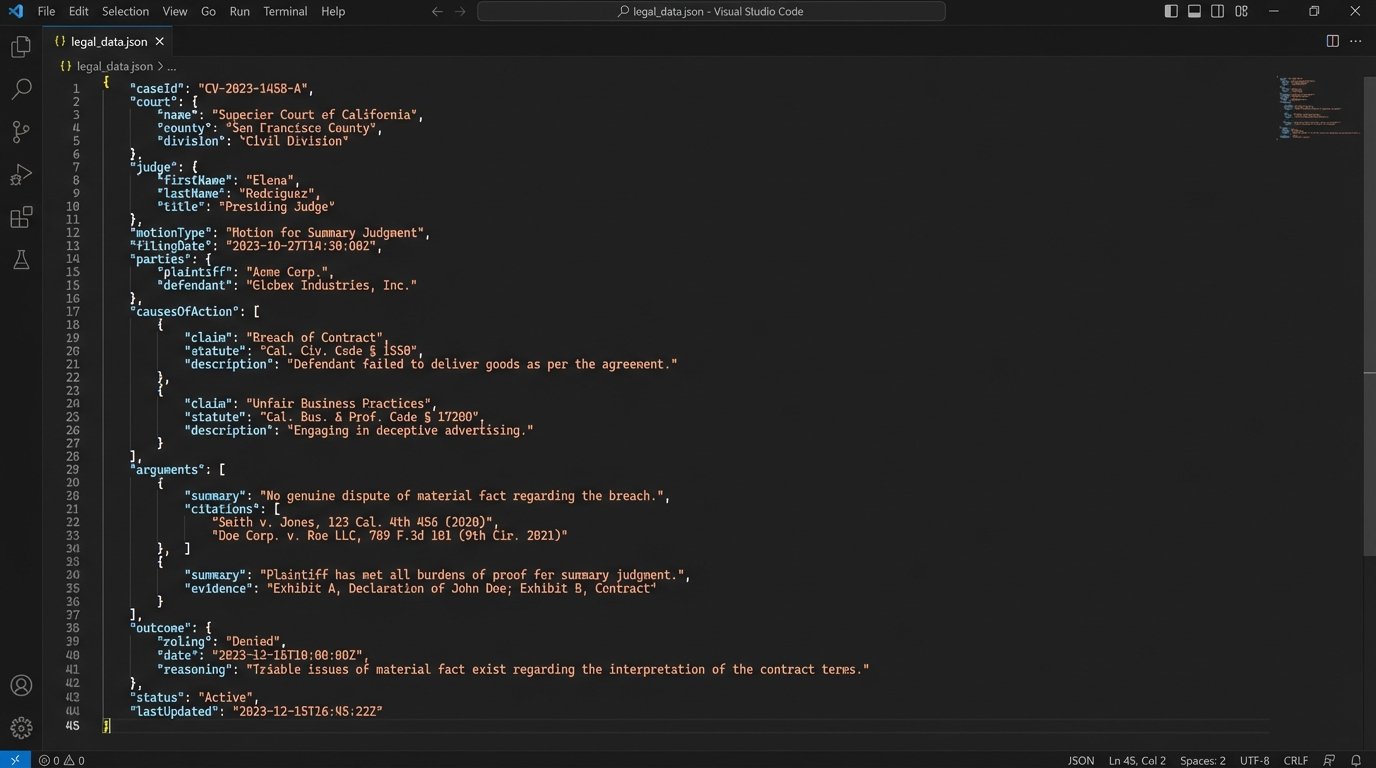
Consider a simple motion to dismiss. A useful data object would not just contain the full text. It would contain discrete fields for the alleged causes of action, the specific arguments for dismissal, the statutes cited by the moving party, the standards of review applied by the court, and a binary outcome field. This structured approach allows a litigation team to ask pointed questions.
An example JSON output for a single case might look something like this:
{
"caseId": "CV-2023-9876",
"court": "S.D.N.Y.",
"judge": "John A. Doe",
"motionType": "Motion to Dismiss",
"outcome": "Granted in part, Denied in part",
"causesOfAction": [
{"type": "Breach of Contract", "outcome": "Dismissed"},
{"type": "Fraud", "outcome": "Sustained"}
],
"arguments": [
{
"argument": "Failure to state a claim under Rule 12(b)(6)",
"target": "Breach of Contract",
"supportingCitations": ["Ashcroft v. Iqbal", "Bell Atlantic Corp. v. Twombly"]
},
{
"argument": "Failure to plead with particularity under Rule 9(b)",
"target": "Fraud",
"supportingCitations": []
}
],
"standardOfReview": "Plausibility Standard"
}
This is clean, queryable data. Multiplying this across thousands of relevant cases creates an analytical engine that no commercial vendor provides, because their business model is built on keeping the raw data just out of reach.
Forcing unstructured case text through a generic analysis tool is like trying to diagnose a patient’s circulatory system by looking at a blurry photograph. You might see the outline, but you miss the critical blockages and flow patterns. You need to inject a contrast dye, a structural agent, to see what is actually happening. That dye is a well-defined data schema.
A Functional Architecture for In-House Automation
Building this capability in-house is an engineering challenge, not a legal research one. It requires a disciplined approach to data pipelining and a clear understanding of the desired outputs. Relying on off-the-shelf software alone will lead to a dead end. A practical architecture consists of several distinct, sequential stages.
Stage 1: Ingestion and Normalization
The first step is acquiring the raw case text at scale. This can be accomplished through bulk data access from providers like the Caselaw Access Project, direct APIs from court systems where available, or carefully constructed web scrapers. The source is less important than the consistency of the acquisition process. The pipeline must be resilient to changes in source formatting and API availability.
Once acquired, the raw HTML or PDF documents must be brutalized into clean, plain text. This pre-processing stage is unglamorous but accounts for half the battle. It involves stripping all formatting, removing junk characters, correcting OCR errors where possible, and standardizing encoding. Each document is then segmented into logical sections like “Background,” “Analysis,” and “Conclusion,” using heuristic markers or simple machine learning classifiers. Failure to properly normalize the input guarantees failure downstream.
You cannot analyze noise.
Stage 2: Targeted Information Extraction
This is where the intelligence is built. Instead of using a generic NLP model, the focus is on creating a series of smaller, specialized extractors. For finding the judge’s name or the court, regular expressions (regex) are often faster and more reliable than a heavy NER model. A well-crafted regex pattern can pull structured citation data with near-perfect accuracy.
For more nuanced data points like the legal standard being applied or the specific holding, a fine-tuned language model is necessary. This does not mean building a foundational model from scratch. It means taking a pre-trained open-source model like one from the BERT family and further training it on a labeled dataset of legal text specific to your firm’s practice. Training a model to only identify the “standard of review” in summary judgment orders will produce far more accurate results than a general-purpose model attempting to understand the entire document.
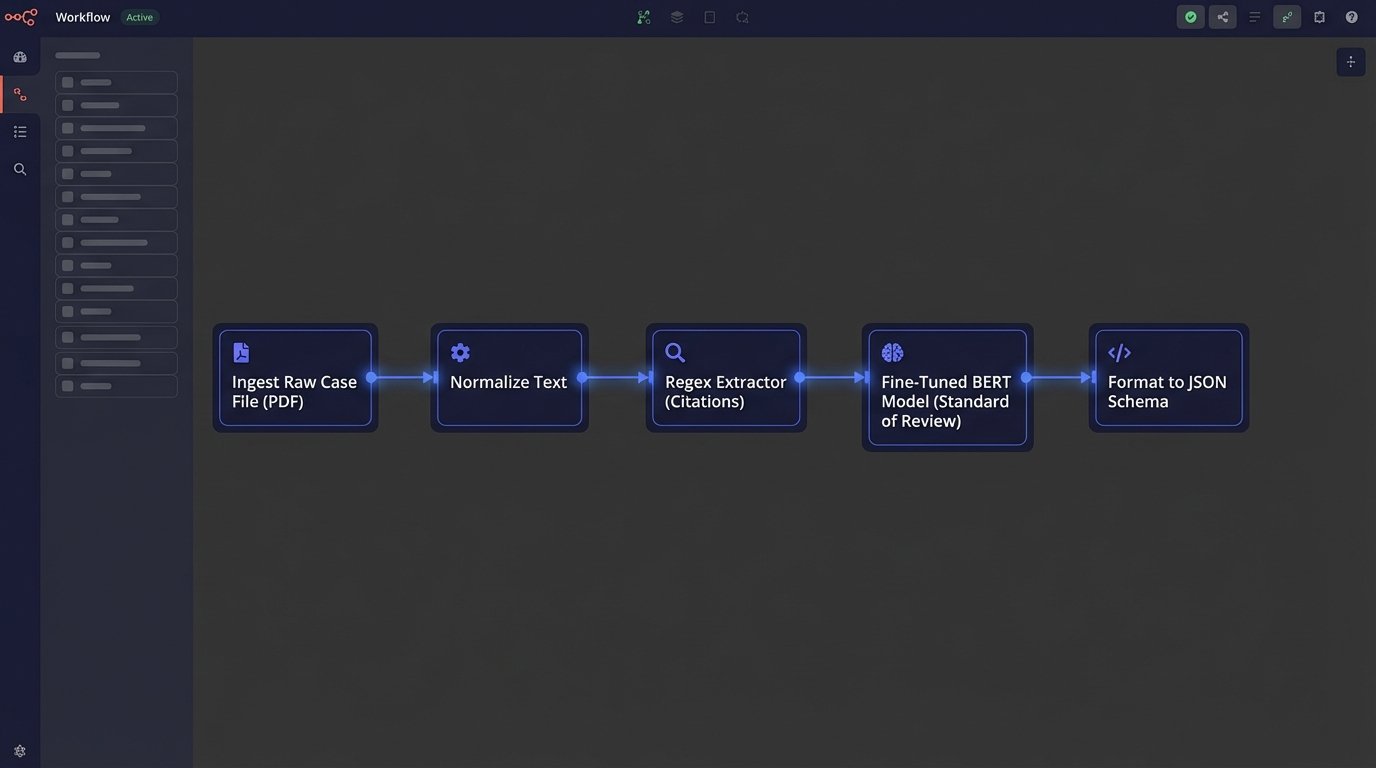
This targeted approach allows for modularity. As the firm’s needs evolve, new extractors can be built and bolted onto the pipeline without disturbing the existing components. It is an assembly line, not a magic box.
Stage 3: Structuring and Storage
The output of the extraction stage is a collection of identified data points. These points must be inserted into the predefined schema, like the JSON example shown earlier. A logic-check layer is critical here to validate the data. It checks for missing fields, confirms data types, and flags low-confidence extractions for manual review. This human-in-the-loop validation is not a weakness; it is a necessary quality control gate.
The final structured objects are loaded into a database suited for complex queries. A relational database like PostgreSQL is adequate for many use cases, but for text-heavy analysis and relevance ranking, a search engine like Elasticsearch is a superior choice. The storage system is not just a repository; it is the workbench where the actual analysis will take place.
The Analytical Payoff: Moving Beyond Search
With a critical mass of structured case data, the type of questions you can ask changes fundamentally. The work shifts from finding individual cases to identifying systemic patterns. This is the entire point of the exercise.
Litigation teams can run aggregate queries to model judicial behavior. For example, you can calculate the grant rate for motions to dismiss filed by a specific law firm before a particular judge over the last five years. You can identify which arguments are most frequently associated with successful outcomes on a specific cause of action. This moves strategy from anecdotal experience to data-driven probability.
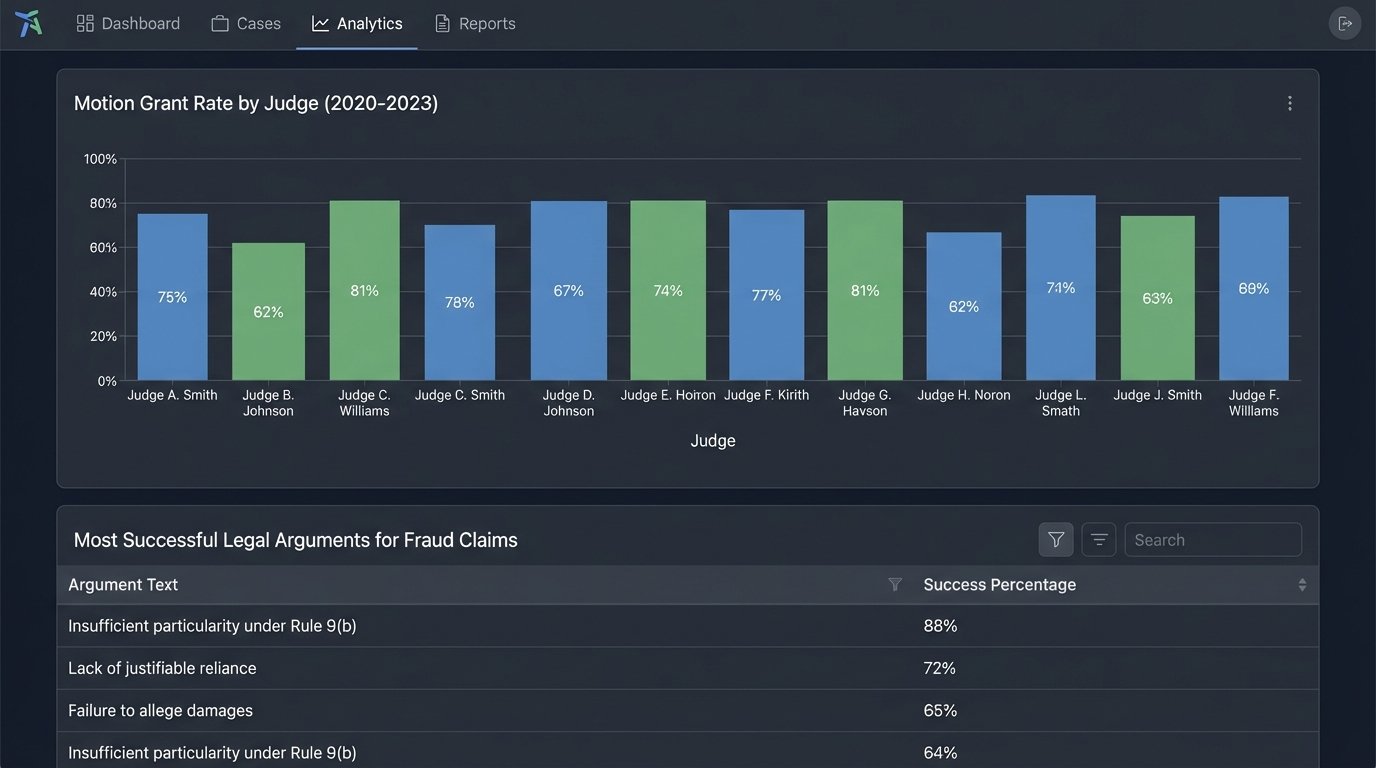
The system also enables proactive intelligence. An automated process can monitor new cases as they are published, process them through the pipeline, and alert lawyers to decisions that favorably or negatively impact their current matters. It can detect when a particular judge starts citing a new precedent or applying a different legal test, providing an early warning of a shift in the local legal environment.
This is about building a proprietary map of the legal terrain, not just buying a generic GPS that everyone else has.
Reality Check: The Cost of Control
This approach is not simple or cheap. Building and maintaining such a system requires a dedicated team with skills in data engineering, software development, and machine learning. It is a significant investment in technical infrastructure and talent.
Data quality is a persistent enemy. Court records are full of typos, formatting inconsistencies, and missing information. The pipeline must include robust error handling and data cleaning routines, and even then, some percentage of documents will require manual intervention. The principle of “garbage in, garbage out” is unforgiving.
The system is also a living entity. Legal language evolves, court websites change, and models require periodic retraining to avoid performance degradation. This is not a one-time project but an ongoing operational commitment. The cost-benefit analysis must account for this long-term maintenance burden against the high recurring fees and limitations of commercial vendors.
Firms must decide if they want to rent their analytical capabilities or own them. Renting is easier to start. Owning is harder to build but provides a durable competitive edge that cannot be replicated by a competitor with a credit card.