
The core failure of most litigation prep is treating it as a clerical task. Teams throw paralegal hours at terabytes of unstructured data, hoping manual organization will somehow produce clarity. This approach doesn’t just invite human error, it builds inefficiency directly into the billable hour, a model that is becoming technically and financially indefensible. The real work is not in dragging files into folders. It is in building a logical pipeline that forces structure onto chaos from the moment a document is collected.
Litigation is no longer a matter of reviewing a few boxes of paper. A single custodian can produce data from a dozen sources. Trying to manage this influx with shared drives and manual Bates stamping is like trying to direct highway traffic with a handheld stop sign. It creates bottlenecks, corrupts metadata, and makes proving chain of custody a nightmare. Automation isn’t about replacing lawyers. It’s about building the infrastructure that prevents them from drowning in low-value work.
Deconstructing the Monolithic Platform Myth
Vendors sell the dream of a single platform to manage everything from ingestion to trial presentation. These monolithic systems are often wallet-drainers, built on legacy architecture with sluggish interfaces and punitive data egress fees. Their APIs, if they exist at all, are frequently poorly documented afterthoughts, forcing you into their closed ecosystem. The result is a rigid system that dictates your workflow instead of adapting to it.
A more resilient strategy involves a service-oriented approach. We build or connect small, specialized tools that do one thing well. A dedicated service for OCR and text extraction, another for PII detection, and a third for injecting structured data into a case management system. This modular architecture is more adaptable. When a better OCR engine comes along, we swap out one component, not migrate an entire platform.
The real power is in the connections we build between these services. The glue is custom scripts and API calls that bridge the gaps, allowing data to flow logically from one stage to the next without manual intervention. This moves the firm’s core intellectual property from a third-party vendor’s black box into code that the firm itself owns and controls. You stop renting your workflow and start owning it.
Stage One: Bruteforcing Document Ingestion and Organization
The ingestion point is the first and best place to impose order. Manual document review for categorization is a massive time sink. We can automate the initial pass by building a pipeline that performs several key operations on every single file received, regardless of its source.
First, the pipeline forces a consistent naming convention. It uses libraries like Apache Tika to extract metadata, such as creation date and author, and embeds that information directly into the filename. It then generates a unique hash (SHA-256) for each file to create an immutable digital fingerprint, which is critical for chain of custody arguments later. This simple step alone eliminates the ambiguity of “Final_Version_2_JohnDoe_edits.docx”.
A basic Python script can handle this renaming and hashing logic across thousands of documents in minutes. It iterates through a directory, extracts the necessary data, and reconstructs the filename and logs the hash. This is not complex code, but it is brutally effective.
import os
import hashlib
import re
from tika import parser
def process_document(filepath):
"""
Extracts date, hashes file, and renames it.
This is a simplified example. Production code needs robust error handling.
"""
BUFFER_SIZE = 65536
sha256 = hashlib.sha256()
with open(filepath, 'rb') as f:
while True:
data = f.read(BUFFER_SIZE)
if not data:
break
sha256.update(data)
file_hash = sha256.hexdigest()
# Extract text to find a date for naming
raw = parser.from_file(filepath)
content = raw.get('content', '')
date_match = re.search(r'(\d{4}-\d{2}-\d{2})', content)
doc_date = date_match.group(1) if date_match else 'NODATE'
original_name, original_ext = os.path.splitext(os.path.basename(filepath))
new_name = f"{doc_date}_{original_name}_{file_hash[:8]}{original_ext}"
# Logic to rename file would go here
print(f"Original: {filepath} -> New: {new_name}")
# os.rename(filepath, os.path.join(os.path.dirname(filepath), new_name))
# Example usage:
# process_document('/path/to/raw_docs/contract_draft.pdf')
This approach transforms a messy collection of source files into a logically sorted, verifiable dataset before a human ever reviews it. The process is deterministic and repeatable, which is more than can be said for manual organization.
The next step in the ingestion pipeline is automated content analysis. We can run scripts that flag documents containing specific keywords, privilege terms, or PII patterns like social security or credit card numbers. This creates an initial layer of issue coding and redaction flagging automatically. An associate’s time is better spent verifying the machine’s output than reading thousands of irrelevant documents to find the important ones.
Evidence Management is a Database Problem
Folders are a terrible way to manage evidence. A file system provides only one primary axis for organization: the folder hierarchy. Evidence, however, is multi-dimensional. A single email might be relevant to multiple custodians, several key case facts, and a specific deposition outline. Forcing it into a single folder location loses that rich context.
The solution is to stop thinking about files and start thinking about records. We treat our evidence repository as a structured database. Each piece of evidence, whether it’s a PDF, an email, or a video file, becomes a record in a central tracker table. This isn’t about storing the files themselves in the database, which is inefficient. It’s about storing the metadata and relationships around them. The file can live on a secure file server, but its life story lives in the database.
Building the Evidence Tracker Schema
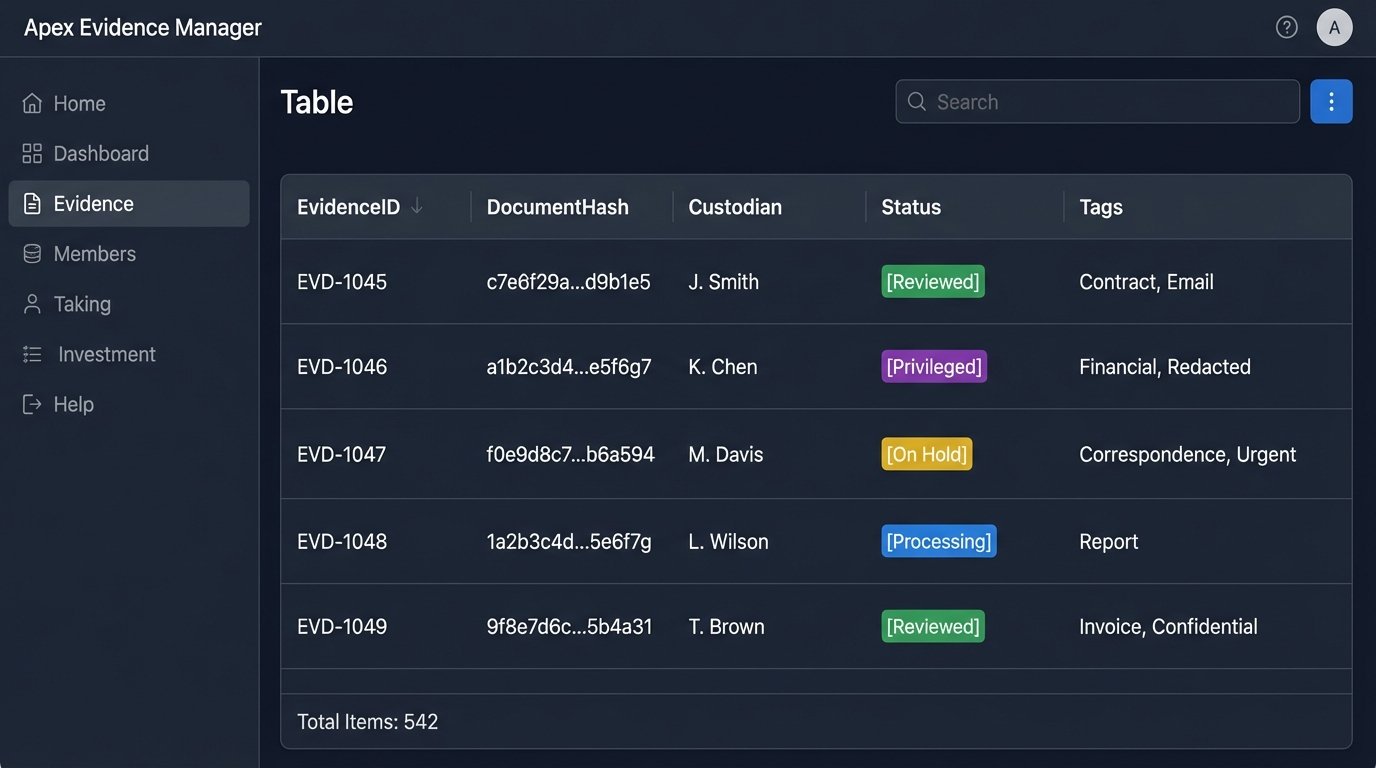
A robust evidence tracking schema is the foundation. We can build this in something as simple as PostgreSQL or as scalable as a document store like Elasticsearch. The key is the fields we track for each record.
- EvidenceID: A unique, system-generated primary key.
- DocumentHash: The SHA-256 hash generated during ingestion. This is our link back to the physical file and our guarantee of integrity.
- SourcePath: The original location of the file.
- Custodian: The person or entity from whom the evidence was collected.
- ExtractedText: A searchable copy of the document’s text content.
- Status: A field to track the review state (e.g., ‘Unreviewed’, ‘Reviewed’, ‘Privileged’).
- Tags: A flexible field, often an array, for linking the evidence to key facts, witnesses, or legal issues.
This database-centric approach makes complex queries trivial. We can instantly find all documents produced by a specific custodian that mention a certain project code and are tagged as relevant to a motion for summary judgment. Performing that same query across a folder-based system is a slow, manual, and error-prone process. It is the difference between having a searchable parts inventory and a junk drawer full of unlabeled hardware. You can find what you need in both, but one is orders of magnitude faster.
We then build simple APIs to interact with this database. When a review platform flags a document, a webhook can call our API to automatically update its status in our central tracker. This keeps the firm’s central evidence record synchronized without requiring manual data entry.
Generating First-Draft Chronologies and Timelines
Building a case chronology is one of the most labor-intensive parts of litigation prep. It involves associates reading through hundreds or thousands of documents to manually extract key dates, events, and actors. This work is ripe for automation, not for replacement, but for augmentation.
Using natural language processing (NLP) models, we can perform Named Entity Recognition (NER) on the extracted text of every document in our evidence database. These models are trained to identify and classify entities like people, organizations, locations, and dates. We can run this process as a batch operation across our entire dataset.
The output is a structured list of every date and event mentioned in every document. We can then script a process to sort these events chronologically, filter out duplicates, and present them as a draft timeline. An associate can then review this machine-generated draft, verify the context, and make corrections. The automation does the grueling 80% of the work, finding the potential events. The lawyer does the high-value 20%, applying legal judgment to determine their significance.
This requires a healthy skepticism. Off-the-shelf NER models can be confused by legal terminology or complex sentence structures. The system might incorrectly tag a company name or misinterpret a date format. The output always requires human validation. But a flawed first draft that is 80% correct is infinitely more valuable than a blank page.
Automating the Logistics of Scheduling
The back-and-forth email chains required to schedule a multi-party deposition are a perfect example of structured, repetitive work that machines excel at. This is a pure logistics problem that consumes an absurd amount of paralegal and attorney time.
We can build a service that hooks into calendar APIs like Microsoft Graph or Google Calendar. The service ingests the list of required attendees and their known email addresses. It then queries their calendars for blocks of free time that match the required duration of the meeting. This is a simple intersection problem on time-slot data.
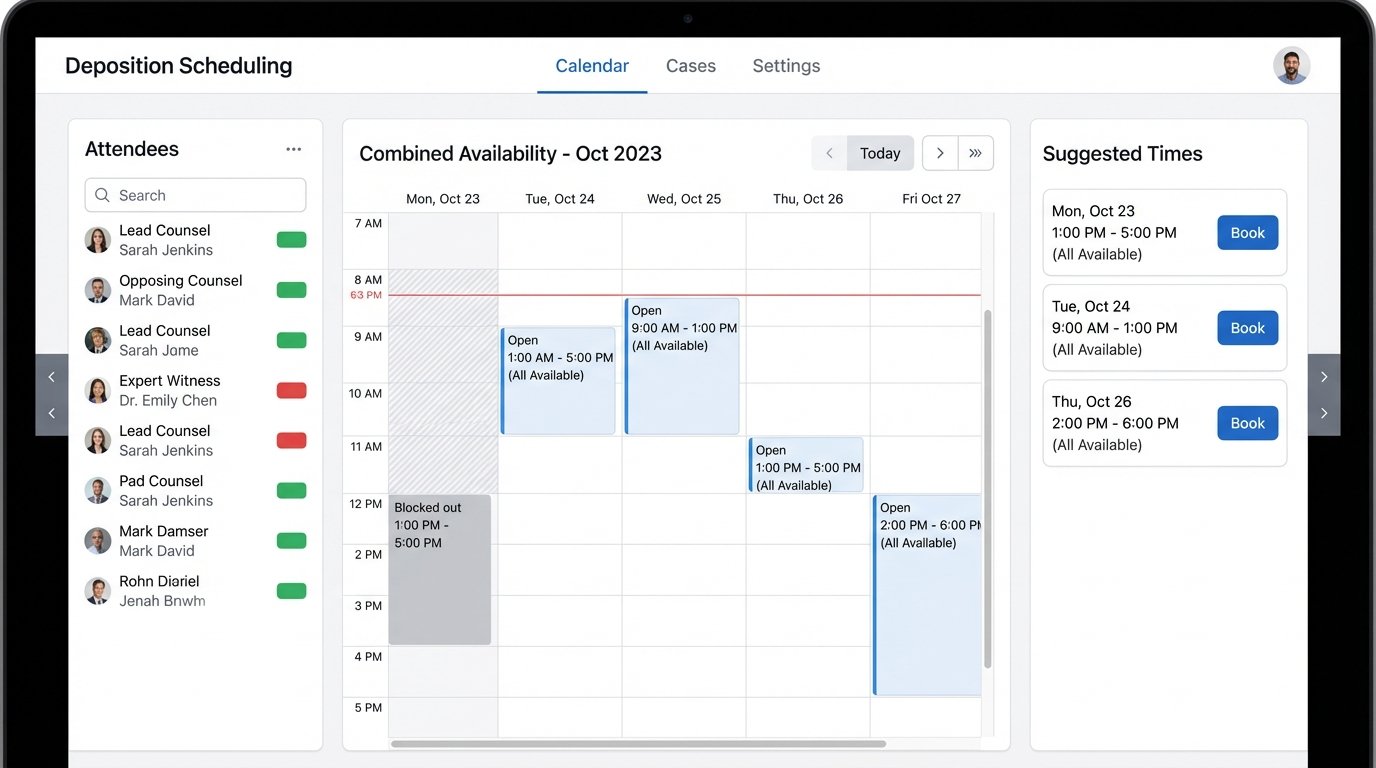
Once the service identifies a set of viable time slots, it can automatically generate and send a scheduling poll or a calendar invitation. The system can monitor responses and, once a consensus is reached or a majority accepts, it can send the final confirmation and book the corresponding resources like conference rooms or court reporters.
The main challenge is not the logic, but the permissions and error handling. You must securely manage API credentials and handle cases where a participant’s calendar is not shared or an out-of-office reply is received instead of an acceptance. The fallback must be a clean notification to a human operator to intervene. The goal is to handle the 90% of cases automatically and intelligently flag the exceptions for manual resolution.
Litigation automation is not a product you buy. It is a capability you build. It requires a shift in thinking from buying seats in a closed platform to owning the logical flow of your own data. The firms that make this shift will not just be more efficient. They will have a structural advantage, capable of handling data at a scale and speed that manual processes simply cannot match.