
Most contract review automation projects fail. They don’t fail because the AI is incapable. They fail because the people implementing them think a software license is a substitute for a data strategy. They buy an expensive “solution” that promises to read contracts and are then shocked when it chokes on a poorly scanned PDF or misinterprets a badly worded indemnification clause. The tool gets blamed, the project is shelved, and everyone goes back to billing hours for work a well-structured script could handle.
The core of the problem is garbage in, garbage out. Automating contract review is not about buying the smartest AI. It is about building a rigid pipeline that forces unstructured junk into a predictable, machine-readable format. Only then can an AI model do its job without hallucinating a non-existent liability cap.
Prerequisites: Foundational Work Before You Write a Single Line of Code
Jumping straight to a vendor demo is a rookie mistake. Without a clearly defined scope and clean data, you are just automating chaos. Any tool you buy will be useless until you get your own house in order. This initial phase is 80% of the work and determines whether the project succeeds or crashes.
Define the Target Clauses
You cannot automate the review of “a contract.” You must target specific, high-value clauses that appear frequently. Start with low-hanging fruit like Non-Disclosure Agreements or standard Master Service Agreements. Create a definitive list of clauses to extract and analyze. Do not move forward until this is complete.
A typical target list for an MSA might include:
- Governing Law and Jurisdiction
- Limitation of Liability
- Indemnification
- Confidentiality
- Term and Termination
- Data Privacy and Security
For each clause, you must have a “playbook” position. This is your firm’s pre-approved, gold-standard language. The entire goal of the automation is to measure the deviation between the contract’s language and your playbook’s language. Without this baseline, any analysis is just noise.
The Data Ingestion Problem
Contracts arrive as a messy collection of DOCX files, scanned PDFs, and emails with embedded text. Your system must first wrestle this chaos into a uniform format. This pre-processing step is brutally tedious and where most of the engineering effort is spent. You will need a multi-stage pipeline to handle the various input formats.
Scanned PDFs require Optical Character Recognition (OCR) to extract raw text. The accuracy of this process is never 100%. Expect to deal with artifacts, misspelled words, and broken sentences. DOCX files are easier but can contain hidden formatting, tables, and tracked changes that will confuse a language model. Your first script should strip all this away, leaving only the clean, raw text of the agreement.
Building this pipeline is like setting up a water purification system. You are taking dirty water from multiple sources and running it through filters until it’s clean enough to drink. If you let contaminated data get to the model, you get poisoned results.

Model Selection: Black Box vs. Direct API
You have two main paths for the AI component. The first is buying a subscription to a legal-specific AI platform. These tools offer a polished user interface but operate as a black box. You have little control over the underlying model, its training data, or how it derives its conclusions. They are quick to deploy but expensive and inflexible.
The second path is using a general-purpose Large Language Model (LLM) like GPT-4 or Claude via its API. This approach gives you granular control over the process, from the prompts you send to how you structure the output. It is more work to set up but is cheaper at scale and allows you to build a system tailored to your exact needs. Fine-tuning an open-source model on your firm’s own documents is another option, but it is a capital-intensive project requiring specialized talent.
For most firms starting out, direct API access to a powerful, general-purpose model offers the best balance of control and capability. You are not locked into a vendor, and you can swap out the model backend as better ones become available.
The Build: A High-Level Architecture
With the prerequisites handled, the actual build can begin. This process involves three main steps: pre-processing the document, sending the text to a model for analysis, and then comparing the model’s output against your firm’s playbook.
Step 1: Document Pre-processing and Text Extraction
This is where the ingestion pipeline is built. The goal is to create a script that can take any contract file as input and produce a clean text file as output. Python is the standard tool for this, using libraries to handle different file types.
For PDF files, a library like `PyMuPDF` can extract text from digitally-native documents. For scanned images or image-based PDFs, you will need to integrate an OCR engine like Tesseract. For DOCX files, the `python-docx` library works well. The script should identify the file type and route it to the correct extractor.
Here is a simplified Python snippet showing text extraction from a PDF. Real-world code would need more robust error handling.
import fitz # PyMuPDF
def extract_text_from_pdf(pdf_path):
try:
doc = fitz.open(pdf_path)
full_text = ""
for page in doc:
full_text += page.get_text()
return full_text
except Exception as e:
print(f"Error processing {pdf_path}: {e}")
return None
# Usage
contract_text = extract_text_from_pdf("msa_agreement.pdf")
if contract_text:
# Next step: send to LLM API
pass
This code does not perform any cleaning. A production version would need to logic-check the output and strip headers, footers, page numbers, and other metadata that provides no value to the clause analysis.
Step 2: Clause Extraction with an LLM
Once you have the clean text, you send it to an LLM API. The key to getting reliable results is prompt engineering. You must give the model explicit instructions, telling it exactly which clauses to find and demanding the output in a structured format like JSON.
A poorly written prompt gets you a conversational, unusable paragraph. A well-structured prompt forces the model to act like a predictable API. Your prompt should include a clear instruction, the list of clauses to find, and the desired JSON schema for the response.
The goal is to get a response you can parse programmatically. The model should return an object where each key is a clause name and the value is the exact text of that clause from the contract. If a clause is not found, it should return a null value, not make something up.
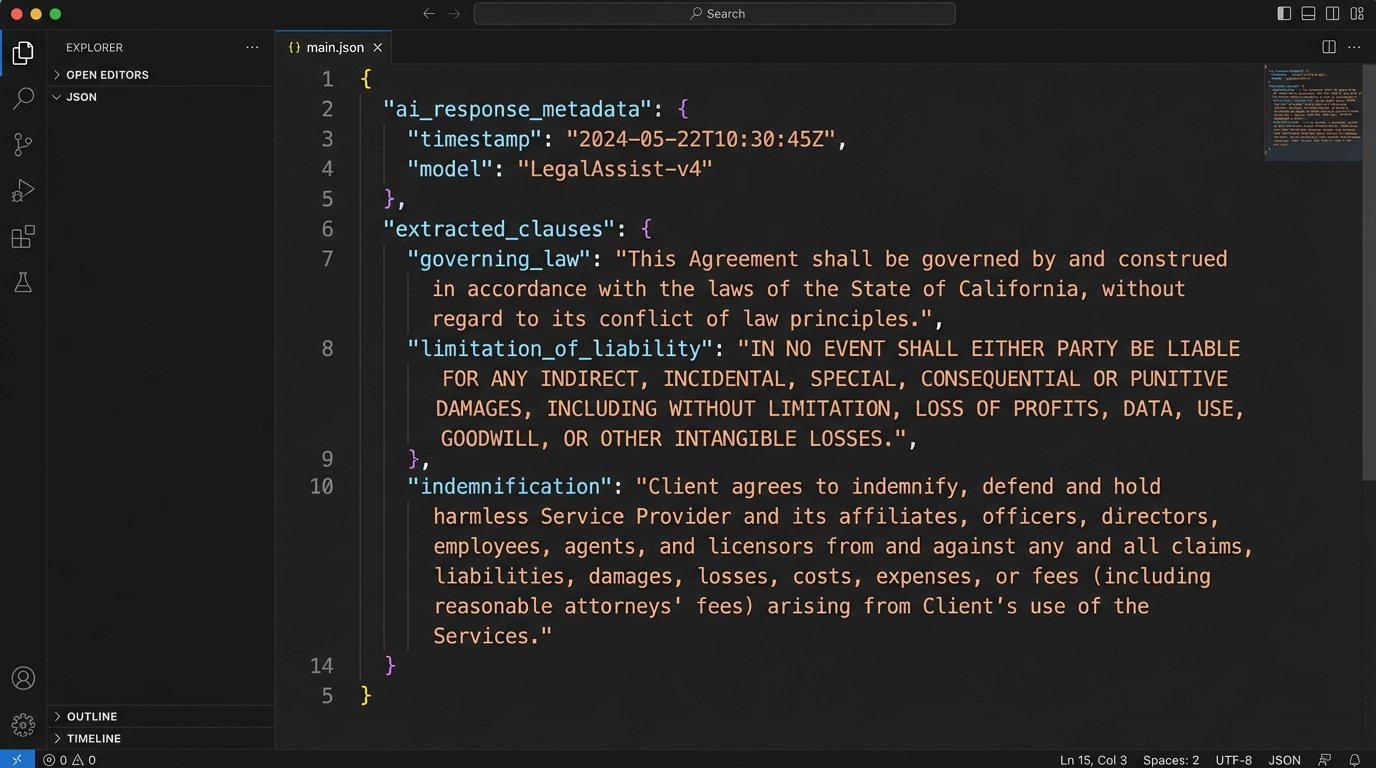
Step 3: Playbook Comparison and Risk Scoring
With the structured JSON response from the LLM, you now have the contract’s clauses isolated. The final step is to compare this extracted text against your firm’s approved playbook language for each clause. This comparison determines the risk level.
This can be a simple or complex process. A basic approach is to send both the extracted clause and your playbook clause back to the LLM in a new API call, asking it to identify and list the material differences. A more advanced method involves calculating semantic similarity scores using vector embeddings. This gives you a numerical score of how much the contract’s language deviates from your standard.
The output of this stage is a final risk report. You can use a simple traffic light system:
- Green: The clause matches the playbook language exactly or has only minor, acceptable deviations. No human review is needed.
- Yellow: The clause is present but deviates from the playbook in potentially significant ways. Flagged for mandatory human review.
- Red: The clause is missing entirely, or it contains language that is explicitly forbidden by the playbook (e.g., uncapped liability). This requires immediate senior attorney review.
This system doesn’t replace the lawyer. It directs their attention to the 10% of the document that actually requires their expertise, instead of having them waste time reading boilerplate.
Validation and Maintenance: The Job Is Never Done
Deploying the system is not the end of the project. A contract review tool that is not continuously monitored and validated is a malpractice risk waiting to happen. You must treat it as a dynamic system, not a static piece of software.
The Human-in-the-Loop Workflow
Every single output flagged as Yellow or Red must be reviewed by a human. This is non-negotiable. The true value of the system is creating a feedback loop from these human reviews. When an attorney corrects a misinterpretation by the AI, that correction should be logged and stored.
This logged data of AI failures and human corrections becomes the training data for the next version of your system. Over time, you can use this data to fine-tune a model specifically on your firm’s documents and review patterns, drastically improving its accuracy on the types of contracts you see most often.
Meaningful Performance Metrics
Vendor claims of “95% accuracy” are meaningless marketing fluff. Accuracy on what data? Under what conditions? You need to track metrics that have a direct impact on the firm’s operations and profitability.
Track these KPIs instead:
- Time to First Review: The average time from when a contract is received to when a lawyer has a risk-scored report. The goal is to get this down from hours or days to minutes.
- False Negative Rate: How often the system marks a high-risk clause as “Green.” This is your most important metric, as it represents pure risk. It should be as close to zero as possible.
- Human Review Time per Contract: Measure the time lawyers spend on AI-assisted reviews versus fully manual reviews. This demonstrates the direct efficiency gain.
Log every API call, every model response, and every human override. This audit trail is your defense if a contract reviewed by the system ever becomes the subject of a dispute.

Dealing with Model Drift and Edge Cases
Language and legal standards evolve. A model trained on contracts from five years ago may not understand new clauses related to generative AI usage or modern data privacy regulations. Its performance will degrade over time if it is not retrained. This is called model drift.
You must have a process for periodically re-evaluating and fine-tuning the model with new data from your human-in-the-loop workflow. This requires a budget and dedicated personnel. The automation is a living system, not a one-time purchase. It requires maintenance, feeding, and care, just like any other high-performance engine.