
The manual churn of case law research is a known bottleneck. Associates burn billable hours sifting through thousands of irrelevant search results, a brute-force approach that invites human error and inflates client costs. The common sales pitch is to inject automation as a panacea. This narrative is simplistic and technically dishonest. Effective automation is not a plug-and-play product, but a deliberately engineered architecture designed to pre-process massive datasets before a human ever sees them. The objective is not to find the “perfect” case, but to systematically eliminate the provably wrong ones.
Deconstructing the Research Workflow for Automation
A typical research task breaks down into distinct, machine-addressable stages. We start by mapping the human process to a set of automatable functions. The first step is querying, which is little more than dispatching keyword searches to various legal data providers. The real engineering challenge begins with what happens next: filtering, validation, and structuring the returned data into something a lawyer can actually use without wanting to throw their laptop across the room.
Query Aggregation: Beyond the Single API Call
Relying on a single provider’s API is a strategic error. Each service has its own indexing biases and content gaps. A robust system must abstract the query layer, acting as a broker that sends a single user query to multiple endpoints simultaneously. We build wrappers for APIs from providers like Thomson Reuters, LexisNexis, and others, creating a unified interface. This parallel execution fetches a wider dataset and provides a hedge against any single provider’s temporary service degradation or incomplete records.
The system’s job is to take a generic query, translate it into the specific syntax required by each target API, and then manage the asynchronous responses. Failure to handle this translation and response management correctly results in a system that is both slow and unreliable. It is the foundational layer upon which everything else is built.
Intelligent Filtering: The Rules Engine Core
Once the raw data is ingested, the filtering begins. Basic filtering by jurisdiction or date is trivial. The complex part is implementing nuanced legal logic. For instance, filtering for cases that are binding precedent versus merely persuasive requires a system that understands court hierarchies. This is not a task for a long chain of `if/else` statements hardcoded into the application. That approach creates a maintenance nightmare.
We inject a rules engine to handle this logic. The engine ingests case metadata as facts and applies a configurable set of rules to either accept or reject a case. A rule might look like this: “IF `case.jurisdiction` is ‘Ninth Circuit’ AND `case.court_level` is ‘Appellate’ AND `query.jurisdiction` is ‘California’, THEN `case.precedent_level` is ‘Binding’.” This separates the legal logic from the application code, allowing legal operations teams to fine-tune the filtering criteria without requiring a new software deployment. The goal is to empower the experts to modify the system’s behavior directly.
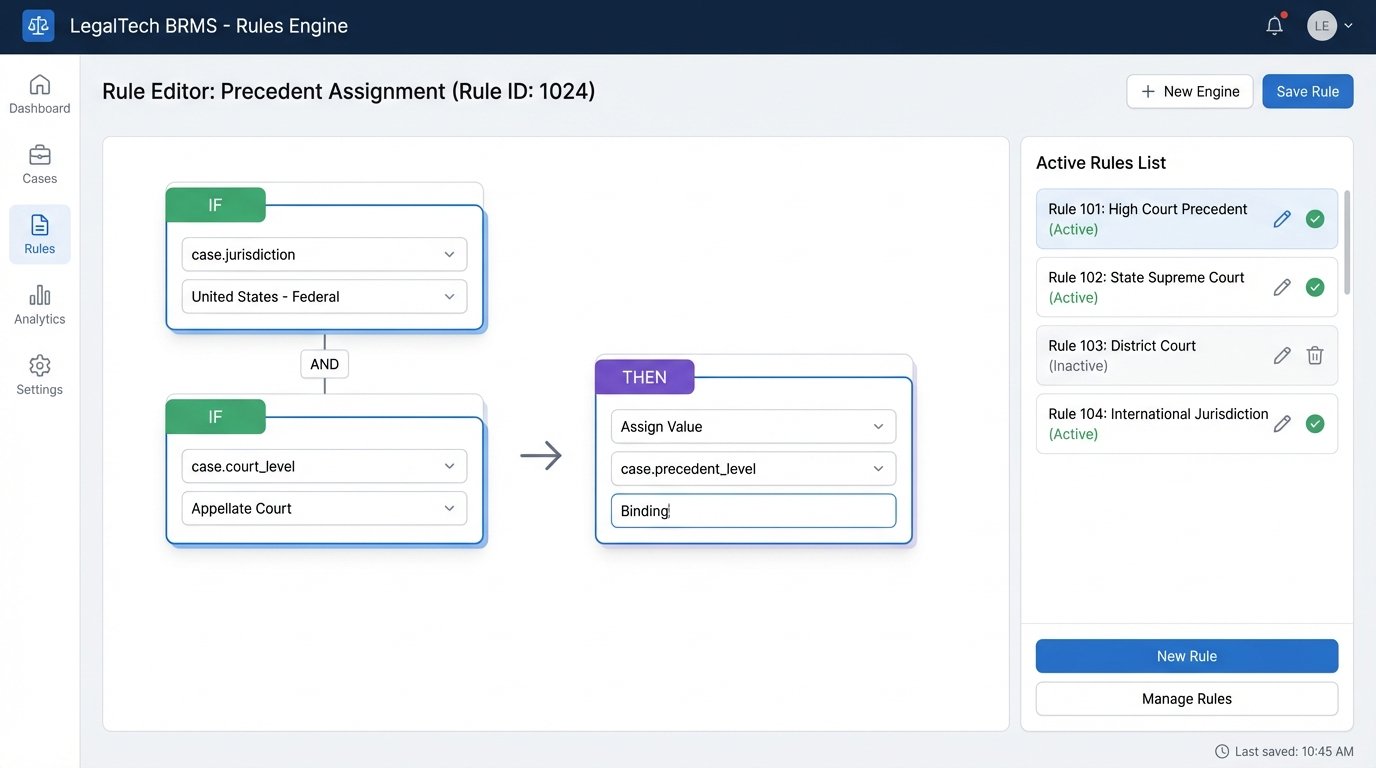
The Citation Validation Bottleneck
A case’s relevance is worthless if it has been overturned. Automating the process of checking a case’s citation history, often called Shepardizing or KeyCiting, is the most critical and fragile part of this workflow. API responses for this data are notoriously inconsistent. Some provide a simple flag like `is_good_law: true`, while others return a complex tree of citing decisions that requires further parsing and analysis.
Building a reliable citation validator requires a multi-step process. First, we must extract every citation from the case text. Then, for each extracted citation, we perform a secondary lookup against the data provider to check its status. This creates a recursive problem that can be slow and computationally expensive. We are essentially trying to shove a firehose of legal history through the needle of a REST API. The system must be built with aggressive caching strategies and asynchronous processing to avoid locking up the user interface while this deep validation occurs.
Architecting the Data Flow
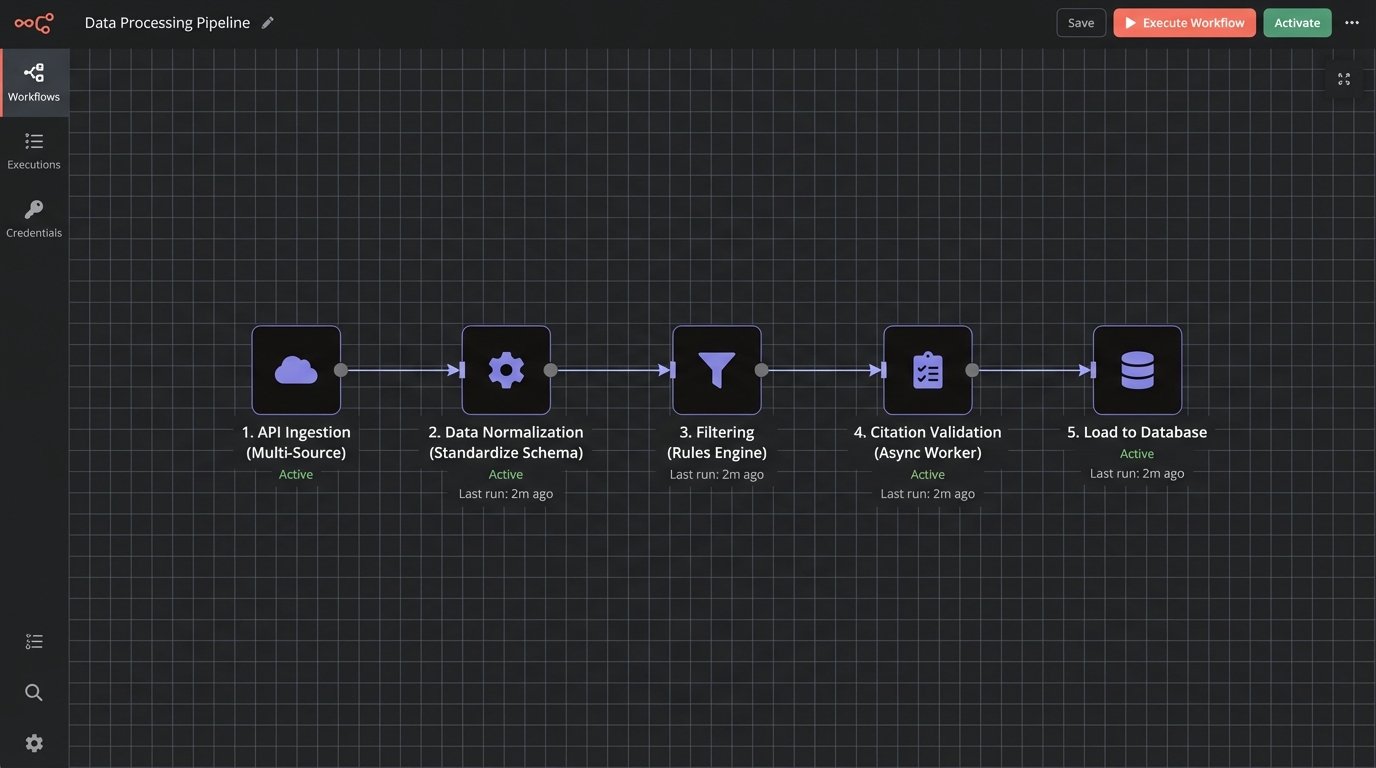
The flow of data from raw API response to a clean, validated report is a pipeline. Each stage has a specific job and must be decoupled from the others. A typical pipeline might look like this:
- Ingestion Layer: Manages API connections, authentication, and rate limiting. It fetches the raw data and dumps it into a message queue for processing.
- Normalization Layer: A worker process pulls raw data from the queue. Its only job is to gut the provider-specific formats and force the data into a standardized internal schema, perhaps a simple JSON object with fields for court, date, decision text, and a placeholder for citation status.
- Filtering Layer: The normalized data is passed to the rules engine. Cases that fail the rules are archived, while those that pass are sent to the next stage.
- Validation Layer: Another worker process picks up the filtered cases. It performs the slow, intensive citation check, updating the case record with a status: `valid`, `cautionary`, or `overturned`. This must run as a background task.
- Presentation Layer: The user interface queries the internal database, not the external APIs. It presents the validated, filtered cases to the user, clearly flagging any with negative treatment.
This decoupled architecture ensures that a failure in one part of the system, such as a third-party API going down, does not bring the entire platform to a halt. It also allows for individual components to be scaled independently.
The Unspoken Costs: Rate Limits and Data Integrity
Every API call to a legal data provider costs money. A single complex query that triggers a deep citation validation for hundreds of cases can become a significant operational expense. An automation system without strict cost-control mechanisms is a blank check written to the data vendors. We must implement throttling to control the rate of outgoing API requests and a circuit breaker pattern to halt requests to an endpoint that is failing or running up costs.
Caching is not optional. Query results and citation statuses must be cached aggressively. There is no reason to fetch the status of *Marbury v. Madison* more than once a day. A Redis or similar in-memory cache can serve these common requests instantly, reducing both latency and cost. The trade-off is cache invalidation logic, which adds complexity. The system must have a way to purge stale data, but this is a far more manageable problem than a massive monthly API bill.
A Code Example: Basic API Wrapper
Building a dedicated wrapper for each API is the first step. This isolates the provider-specific logic. For example, a simple Python function to query a hypothetical API might look like this. It handles authentication and basic error checking, returning a structured response or nothing.
import requests
import os
LEGAL_API_ENDPOINT = "https://api.lawprovider.com/v2/search"
API_KEY = os.environ.get("LEGAL_API_KEY")
def query_case_law(search_term, jurisdiction):
"""
Executes a query against the legal data provider API.
"""
if not API_KEY:
print("Error: API key is not configured.")
return None
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
payload = {
"query": search_term,
"filters": {
"jurisdiction": jurisdiction,
"max_results": 100
}
}
try:
response = requests.post(LEGAL_API_ENDPOINT, headers=headers, json=payload, timeout=30)
response.raise_for_status() # Raises an HTTPError for bad responses (4xx or 5xx)
return response.json()
except requests.exceptions.RequestException as e:
print(f"API request failed: {e}")
return None
# Example usage:
# results = query_case_law("contract interpretation", "New York")
# if results:
# # Begin normalization and filtering process
# pass
This snippet is deceptively simple. A production-ready version would include more robust error handling, retry logic with exponential backoff for transient network failures, and integration with the system’s central logging and monitoring tools. It is the first building block in a much larger structure.
Managing False Positives and Negatives
No automated system is perfect. The rules engine will occasionally filter out a relevant case, a false negative. More dangerously, it may fail to flag a case with negative treatment, a false positive. The architecture must account for this reality. We are not building a system that provides definitive legal answers. We are building a system that provides a high-confidence, pre-filtered dataset for human review.
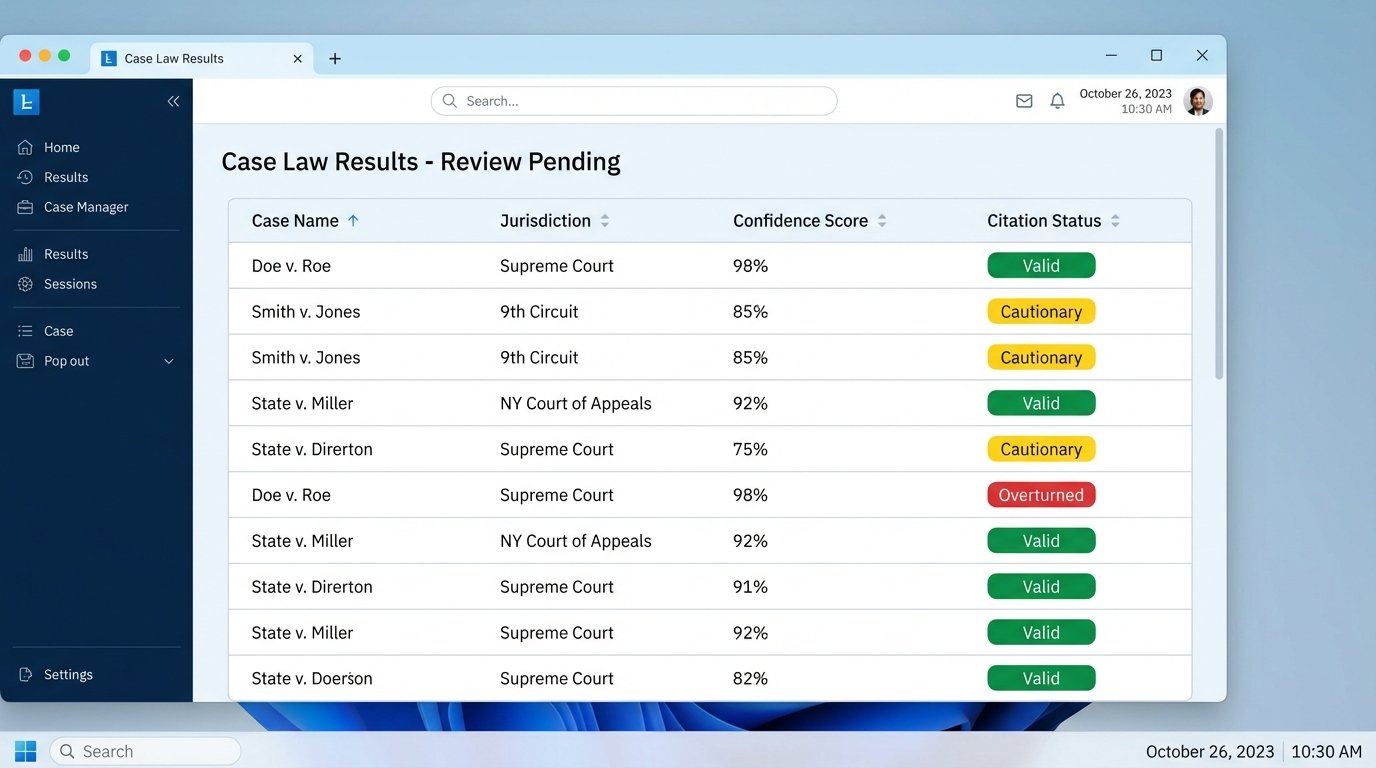
The user interface must reflect this. Every piece of data should have a clear audit trail, linking back to the original source document from the provider. If the system flags a case as “overturned,” that flag must be accompanied by a link to the specific citing case that overturned it. The lawyer must be able to verify the machine’s conclusion in seconds. The system’s credibility depends entirely on this transparency.
The Human-in-the-Loop Workflow
The ultimate output of this system is not a final legal memo but a prioritized work queue for a legal professional. The system should rank results based on a confidence score, which is a composite of precedent level, citation status, and relevance to the query terms. The cases with the highest confidence and binding precedent should be presented first. Cases with cautionary flags or from lower courts should be placed further down the list.
This approach allows the lawyer to focus their valuable time on the most promising material first. The automation has done the heavy lifting of clearing away the 95% of results that were obviously irrelevant or bad law. It transforms the research process from one of discovery in a vast, messy library to one of verification of a small, well-organized set of documents. This is the only realistic and defensible goal of legal research automation. The engineering effort should be focused entirely on building and maintaining the pipeline that enables this specific outcome.