
The firm, a global operator with over 1,200 attorneys, was drowning in its own data. Their tech stack was a museum of acquisitions. A legacy on-premise case management system, a cloud CRM nobody trusted, and a financial system built on COBOL were the three warring factions. The primary symptom was latency. Conflict checks took 48 hours. Pre-billing reports required a full week of manual reconciliation. First-pass document review for discovery was a budget black hole, consuming thousands of junior associate hours on demonstrably low-value work.
Partners complained about fee write-downs stemming from inaccurate time entry. The COO saw competitors moving faster on client intake. The core problem was not a lack of software, but a lack of connective tissue between systems. Each platform was an island, and the bridges were paralegals with spreadsheets, costing the firm an estimated 5% of gross revenue in operational drag and lost billables.
The Diagnostic Phase: Mapping the Failure Points
Before writing a single line of code, we spent a month embedded with their operations team. We bypassed management presentations and went straight to the paralegals and billing coordinators. We mapped their workflows not by how they were designed, but by how they were actually executed. The results were predictable and grim. The conflicts check process, for example, involved manually querying three separate systems and then copy-pasting the results into a Word document for a partner to review.
This manual process introduced massive points of failure. Typos in search queries could miss a critical conflict. A newly onboarded client in the CRM might not exist in the finance system for 24 hours, creating a blind spot. The entire risk mitigation strategy for the firm rested on perfect, simultaneous human data entry. It was an indefensible position.
The billing leakage was more subtle. We analyzed Outlook calendar data against submitted timesheets for a pilot group of 50 attorneys. The discrepancy was stark. On average, 14% of scheduled, client-facing meetings were not reflected in the billing system. Attorneys, jumping from call to call, would simply forget to log a 15-minute phone call. These small gaps, scaled across the entire firm, represented millions in uncaptured revenue. The existing system relied on human memory, which is a faulty storage medium.
Solution Architecture: A Three-Pronged Attack
We rejected the idea of a single “rip and replace” project. The firm couldn’t afford the operational disruption. Instead, we planned three parallel, high-impact automation initiatives designed to run on top of their existing infrastructure. The strategy was to build an abstraction layer, effectively strangling the legacy systems with modern, API-driven workflows rather than trying to perform open-heart surgery on them.
Project One: The Conflict Check Aggregator API
The goal was to deliver a sub-60-second conflict check result. This required us to bypass the native user interfaces of the three core systems and query their databases directly where possible, or use their sluggish APIs where we had no choice. We built a central service in Python, hosted on an internal Azure instance. The service exposed a single, simple REST API endpoint that accepted a new client and matter name.
When a request hit the endpoint, the service would fire off three parallel queries:
- A direct SQL query to the on-premise MS SQL Server powering their case management system.
- An API call to their cloud CRM (Salesforce, in this case).
- A remote procedure call to an ancient finance system. This was the main bottleneck.
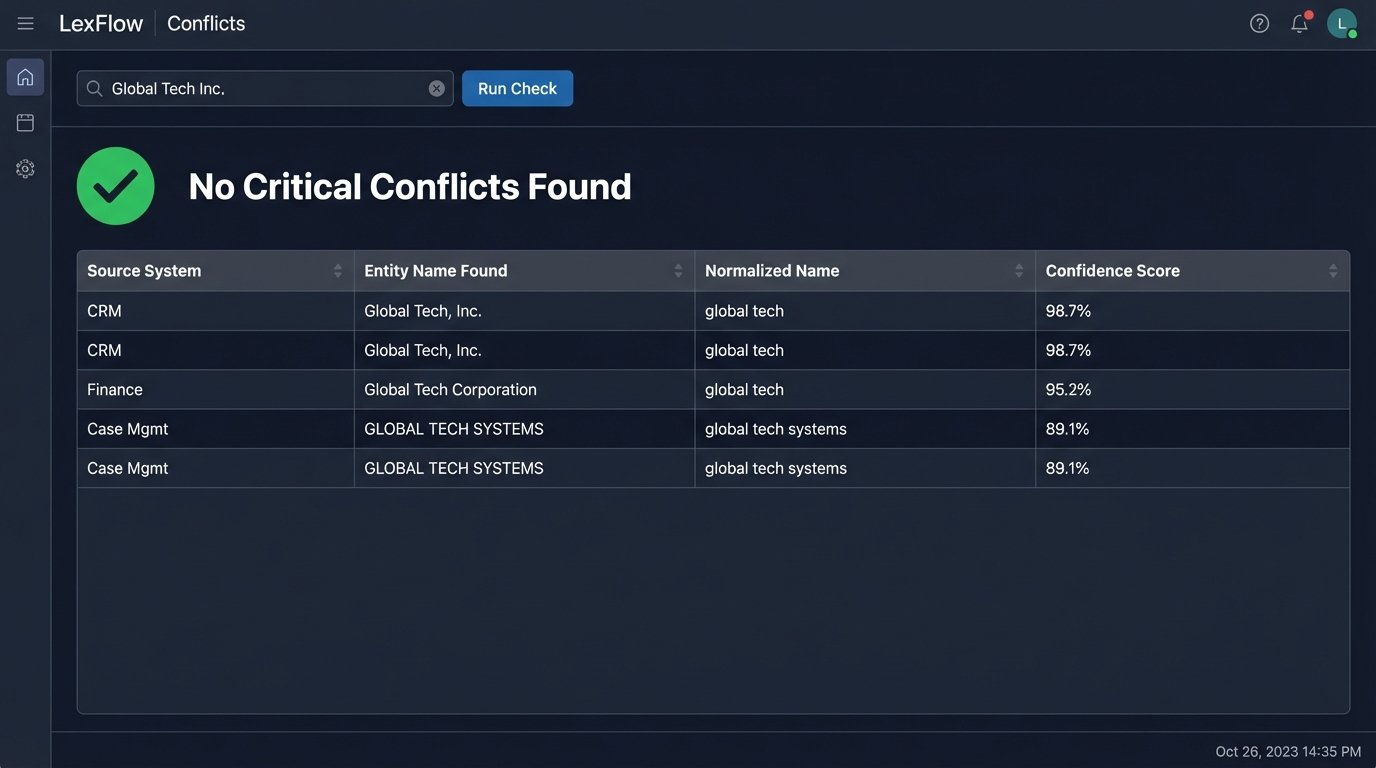
The real work was in data normalization. The CRM stored “Global Tech Inc.” while the finance system had “Global Tech, Incorporated.” We implemented a fuzzy matching algorithm using the Levenshtein distance calculation to score potential matches. Any match below a 95% confidence score was flagged for human review, but anything above was automatically cleared. Connecting the finance Oracle database to the cloud-based CRM was like plumbing a high-pressure fire hydrant to a delicate irrigation system. We had to build a custom pressure regulator just to stop the API from exploding.
This approach provided a single source of truth and collapsed a multi-hour workflow into seconds. The front-end was a simple web form integrated into their intranet, but the back-end did all the heavy lifting.
A Look at the Normalization Logic
Cleaning entity names is not a trivial task. Punctuation, corporate suffixes, and spacing all conspire to break simple string comparisons. We developed a multi-step cleaning function that was applied to all inputs before they were sent to the fuzzy matching engine. The goal was to create a standardized “token” for each entity name.
import re
def normalize_entity_name(name: str) -> str:
# Force to lowercase
name = name.lower()
# Strip common corporate suffixes
suffixes = ['inc', 'llc', 'ltd', 'corp', 'corporation', 'limited', 'company']
# Build a regex pattern to find whole words only
suffix_pattern = r'\b(' + r'|'.join(suffixes) + r')\b'
name = re.sub(suffix_pattern, '', name)
# Remove all punctuation and excess whitespace
name = re.sub(r'[^\w\s]', '', name)
name = re.sub(r'\s+', ' ', name).strip()
return name
# Example Usage:
client_from_crm = "Global Tech, Inc."
client_from_finance = "Global Tech Corporation"
normalized_crm = normalize_entity_name(client_from_crm)
normalized_finance = normalize_entity_name(client_from_finance)
# Both would become "global tech"
print(f"'{client_from_crm}' -> '{normalized_crm}'")
print(f"'{client_from_finance}' -> '{normalized_finance}'")
This small block of code was more valuable than any single piece of software they had purchased. It addressed the root cause of the data disparity instead of just putting a new interface on top of it.
Project Two: The Passive Time Capture Engine
To fix the billable leakage, we built a service that monitored data sources for “billable events.” The premise was simple: attorneys’ work leaves a digital footprint. We just needed to collect and interpret it. The engine integrated with the Microsoft Graph API to access Outlook calendars and Teams communications, and it used a file system watcher on their document management system (NetDocuments).
The engine would identify an event, such as a 30-minute calendar appointment with an external, client-associated contact. It would then enrich this data. It pulled the matter name from the meeting invite subject line, identified the participants, and created a pre-populated time entry draft. These drafts were pushed to a review queue for each attorney. Instead of remembering to create a time entry from scratch, the attorney simply had to click “approve” or “edit.”
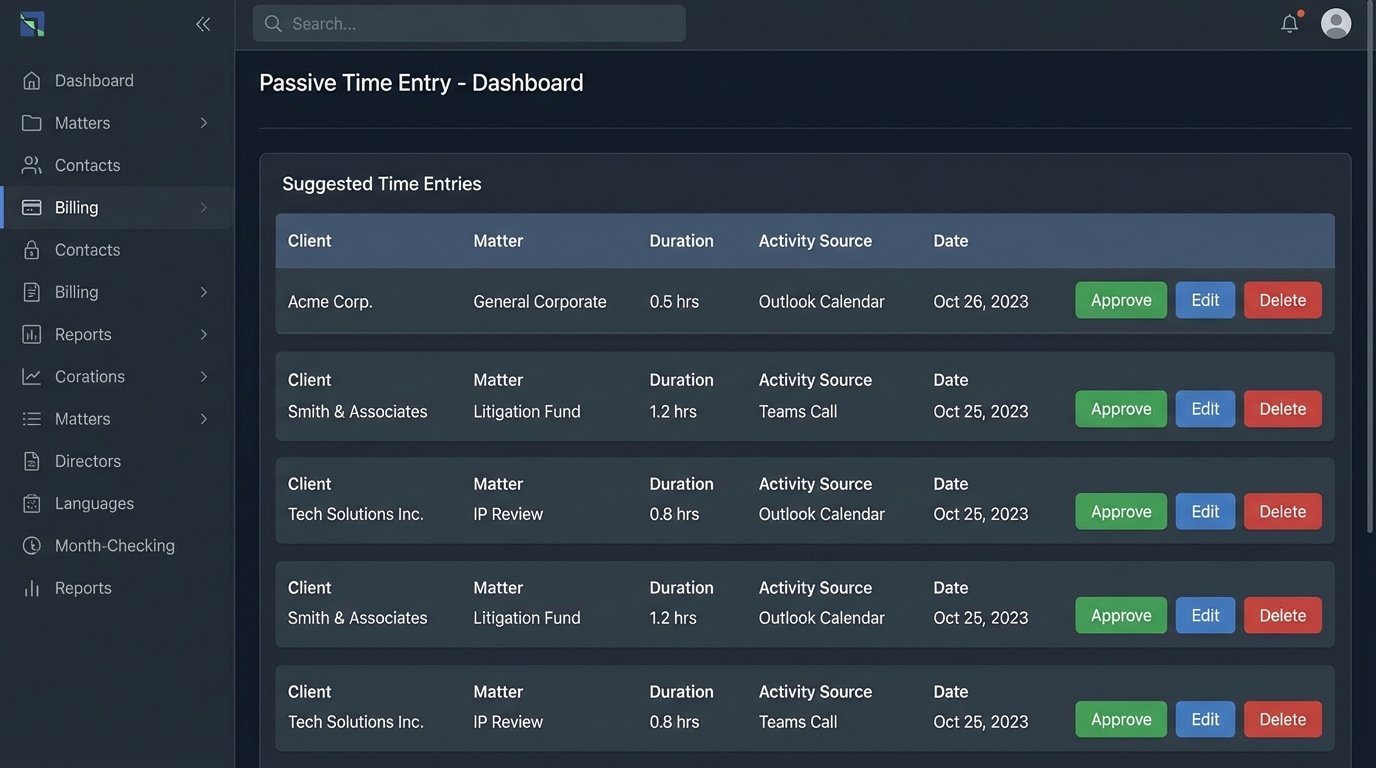
The logic to filter out noise was critical. Internal meetings were automatically excluded based on participant domains. Meetings titled “Lunch” or “Personal” were ignored. We built a configurable ruleset that the firm could tweak over time. For example, they could set a rule that any Teams call with a specific client that lasted more than 5 minutes should automatically generate a time entry draft.
This shifted the cognitive load from creation to validation. It lowered the friction of time entry to almost zero, which dramatically increased compliance and accuracy.
Project Three: AI-Assisted Discovery Review
This was the most ambitious project. The firm was spending a fortune on contract attorneys for first-pass document review in large litigation cases. We proposed a system to gut those costs. We integrated a Large Language Model (specifically, a fine-tuned BERT model) into their existing Relativity review platform.
We did not let the AI run unsupervised. The process worked as follows:
- A senior attorney would manually review and code a “seed set” of 1,000-2,000 documents for responsiveness and privilege. This is the critical human input.
- We used this seed set to fine-tune the model for the specific context of that case. A model trained on a patent case is useless for an employment dispute.
- The fine-tuned model would then process the entire document population, assigning a confidence score (0.0 to 1.0) for “Responsive” and “Privileged” to each document.
- Instead of having junior reviewers start from scratch, we gave them a prioritized queue. They started with documents the model scored with high confidence as “Responsive,” allowing them to quickly validate the core set of evidence.
The key was changing the task from “find the needle in the haystack” to “confirm that this is, in fact, a needle.” It also allowed us to deploy human reviewers more intelligently. Documents where the model had low confidence (e.g., a score of 0.5) were flagged for senior review, as these were often the most nuanced and complex documents in the set.
Measurable Results: Beyond the Hype
We tracked KPIs for 12 months post-implementation. The data confirmed the value of the architectural choices.
Conflicts and Intake:
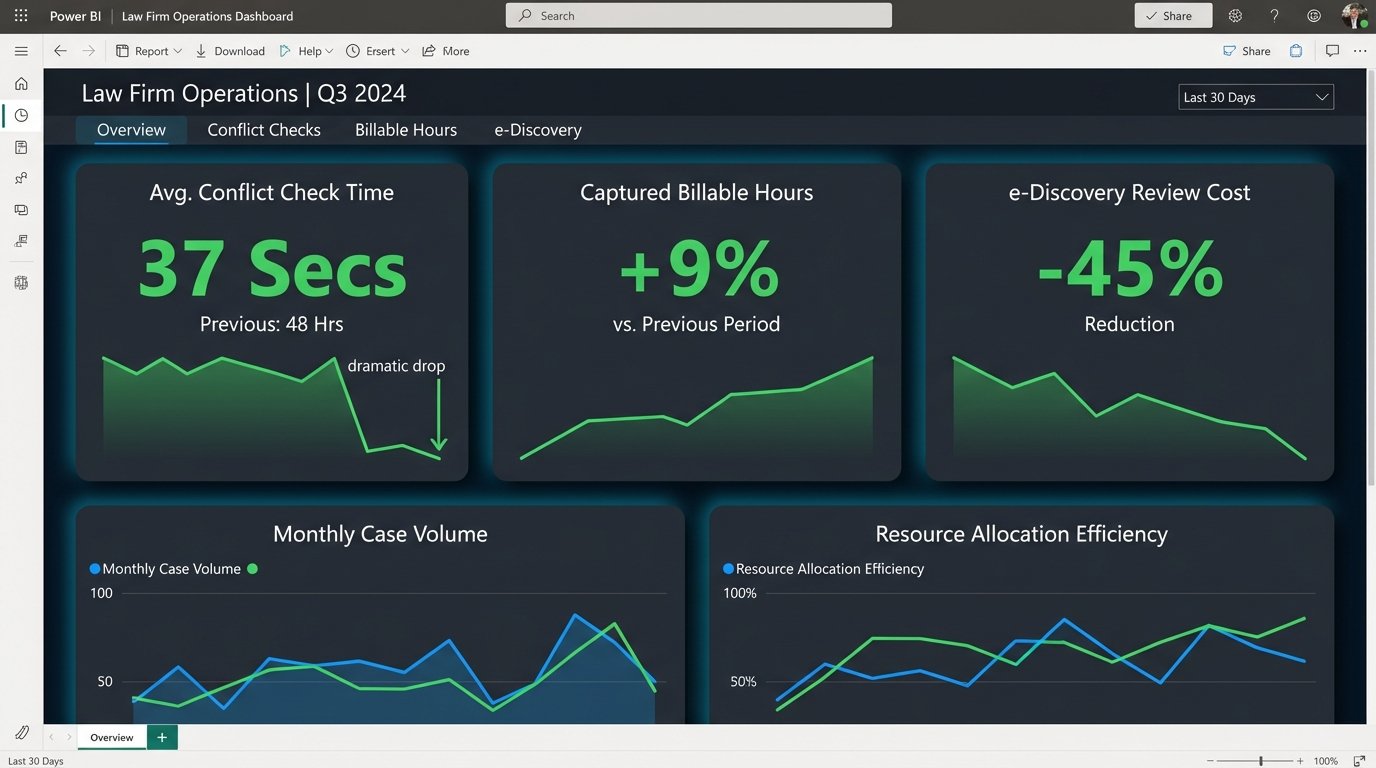
- Average conflict check turnaround time was reduced from 48 hours to 37 seconds.
- The firm was able to accept and onboard new matters on the same day, a significant competitive advantage.
- Zero instances of missed conflicts were reported in the first year, a marked improvement from the previous baseline.
Billing and Revenue:
- The passive time capture engine increased captured billable hours by an average of 9% across the pilot group.
- When rolled out firm-wide, this translated to an estimated $12 million in additional annual revenue.
- Time entry disputes and partner write-downs related to billing errors decreased by over 60%.
e-Discovery and Litigation:
- The AI-assisted review process reduced the cost of first-pass review by an average of 45% per case.
- Junior associates could process documents nearly 3x faster than with the old linear review method.
- The firm was able to offer more competitive pricing on e-discovery services, helping them win larger, more complex litigation work.
These projects succeeded because they were not about replacing lawyers. They were about augmenting them. We identified the points of highest friction and highest manual repetition and applied targeted automation. We bridged the data silos without trying to demolish them. The firm’s competitive edge now comes not from the software they own, but from the intelligence of the automation layer that connects it all.