
Statutory research has degenerated into a high-stakes data filtering problem. The firehose of legislative updates, regulatory amendments, and revised ordinances creates a signal-to-noise ratio that is operationally untenable for manual review. Attorneys are not data analysts, yet we force them to act as such, sifting through mountains of unstructured text to find the single clause that impacts a client’s compliance posture. This is a systemic failure of tooling, not a failure of legal expertise.
The current market of AI tools promises a quick fix. It is not. Most are thin wrappers around general-purpose language models, sold with a legal-themed interface and a hefty subscription fee. They treat statutes as generic text, ignorant of the structural and jurisdictional context that defines legal documents. To properly address the problem, we must stop thinking like lawyers buying a product and start thinking like engineers building a system. The core task is to build a processing pipeline that can ingest, analyze, and flag legislative changes with high fidelity, forcing the output into a structure a lawyer can actually use.
Deconstructing the AI Hype Cycle
Large language models (LLMs) do not understand law. They are masters of statistical pattern matching, predicting the next word in a sequence based on the terabytes of internet text they were trained on. This capability is powerful for summarization and rephrasing, but it is not legal reasoning. When a model interprets a statute, it is matching the patterns in the text to similar patterns it has seen before. It is not applying principles of statutory construction or considering legislative intent.
This distinction is critical. Believing the model “understands” leads to over-reliance and catastrophic errors. The output of an LLM is a high-probability suggestion, not a verified legal conclusion. Our entire architecture must be built around this fact, with checkpoints, validation layers, and direct source linking to fight the model’s tendency to hallucinate plausible but factually incorrect information. We are building a system to generate leads for human experts, not a system to replace them.
The First Hurdle: Garbage In, Garbage Statute
Before any analysis can occur, the raw text of statutes must be acquired and cleaned. This is the least glamorous and most critical step. Legislative sources are a chaotic mix of formats: badly structured HTML on government websites, scanned PDFs with OCR errors, and occasionally, a structured XML feed. Each source requires a custom parser to strip out the noise and isolate the core legal text. A failure here poisons the entire downstream process.
We cannot just dump the raw HTML or PDF text into a model. We must logic-check and normalize the content, stripping out page numbers, headers, footers, and legislative annotations that are not part of the statute’s operative text. These artifacts confuse the model, polluting the semantic context and leading to bizarre interpretations. This is a brute-force data hygiene task that determines the ultimate reliability of the system.
Normalizing Legislative Text
The goal of normalization is to produce a clean, consistent text file for each statutory section. This involves programmatic removal of non-operative content. For example, a common problem is identifying and excising section headers or amendment history notes that are embedded directly within the text block. A simple Python script using regular expressions can handle much of this grunt work, searching for patterns that denote junk data.
Consider a typical line from a state code website: “§ 101. Definitions. [Effective Jan 1, 2024]”. The model only needs “Definitions.” The rest is noise. A targeted cleaning function can isolate and remove the citation marker and the effective date annotation, feeding a cleaner signal to the next stage.
import re
def clean_statute_text(raw_text):
# Pattern to find section markers like § 101. or Article 5:
text = re.sub(r'^(§|Art\.|Article)\s*[\d\w\-\.]+\s*', '', raw_text)
# Pattern to remove bracketed annotations like [Effective...] or [Repealed]
text = re.sub(r'\[.*?\]', '', text)
# Strip leading/trailing whitespace
return text.strip()
# Example usage:
raw = "§ 101.1-A. Definitions. [Effective Jan 1, 2024]"
clean = clean_statute_text(raw)
# clean would be "Definitions."
This code is simplistic. A production environment requires a far more sophisticated chain of parsers and rules to handle the sheer variety of legislative formats. It is tedious but non-negotiable.
From Words to Vectors: The Core Mechanic
Once we have clean text, we need a way for a machine to compare the meaning of different clauses. This is done by converting text into a series of numbers called a vector embedding. Each statutory clause is fed through a model that maps it to a specific point in a high-dimensional space. Think of it like a coordinate system for meaning. Clauses with similar meanings, like “data privacy” and “information security,” will be mapped to points that are close to each other. Clauses with different meanings, like “tax liability” and “environmental protection,” will be far apart.
This process of converting text to coordinates is the engine of semantic search. It lets us find relevant statutes without relying on exact keyword matches. The quality of this engine depends entirely on the embedding model used. A cheap, generic model might not grasp the subtle distinctions in legal terminology, treating “liability” and “responsibility” as identical when they carry vastly different legal weight. Choosing the right model is a balancing act between cost, speed, and domain-specific accuracy.
Trying to run a high-fidelity legal analysis using a generic, off-the-shelf embedding model is like trying to shove a firehose through a needle. The pressure is immense, and the output is a useless, distorted spray.
Model Selection Is Not One-Size-Fits-All
The choice is typically between using a proprietary, closed-source API or running a self-hosted, open-source model. Using an API from a provider like OpenAI or Anthropic is fast to set up but creates a dependency. Your data is sent to a third party, performance is subject to their availability, and the costs can become a serious wallet-drainer at scale. It offers convenience at the price of control and long-term expense.
Self-hosting an open-source model like one from the Llama or Mistral families gives you full control over the data and the environment. There are no per-query fees. The trade-off is the significant upfront investment in hardware and the technical expertise required to deploy, fine-tune, and maintain the model. A sluggish, poorly configured local model can be worse than a paid API. The decision hinges on the firm’s scale, security posture, and in-house technical capability.
Querying Statutes: The Art of Asking the Right Question
With a vector database full of our statutes, the next challenge is user interaction. A lawyer does not think in keywords. They think in fact patterns and legal issues. The system’s interface must be able to translate a complex legal query into a format the vector database can understand. This is where prompt engineering becomes essential.
A poorly formed query like “recent changes to privacy law” is too broad and will return a flood of irrelevant results. A well-formed query is specific and context-rich: “Identify all sections in the California Consumer Privacy Act as amended by the CPRA that impose new obligations on businesses for processing employee data for workplace monitoring purposes.” The second query provides the jurisdiction, the specific act, and the precise legal issue, allowing the system to zero in on the most relevant vectors.
Beyond Keywords: Semantic Search in Action
The real power of this approach is its ability to find conceptually related text. A keyword search for “non-compete agreement” would miss a clause that says, “an employee shall not engage in any business that is in direct competition with the employer for a period of twelve months following termination.” The phrasing is different, but the legal concept is identical.
A semantic search system bridges this gap. Because the vector for “non-compete agreement” is located near the vector for the prohibitive clause, the system will return it as a relevant result. This surfaces critical information that would be invisible to traditional search methods. It finds the “unknown unknowns” by focusing on meaning rather than exact string matching.
Automating Legislative Tracking
The ultimate goal is to build a monitoring system that automatically alerts lawyers to relevant changes. This requires a workflow that periodically ingests new versions of statutes, compares them to the old versions, and flags significant differences. This is not simply running a `diff` command, which would create an unmanageable number of alerts for minor punctuation or formatting changes.
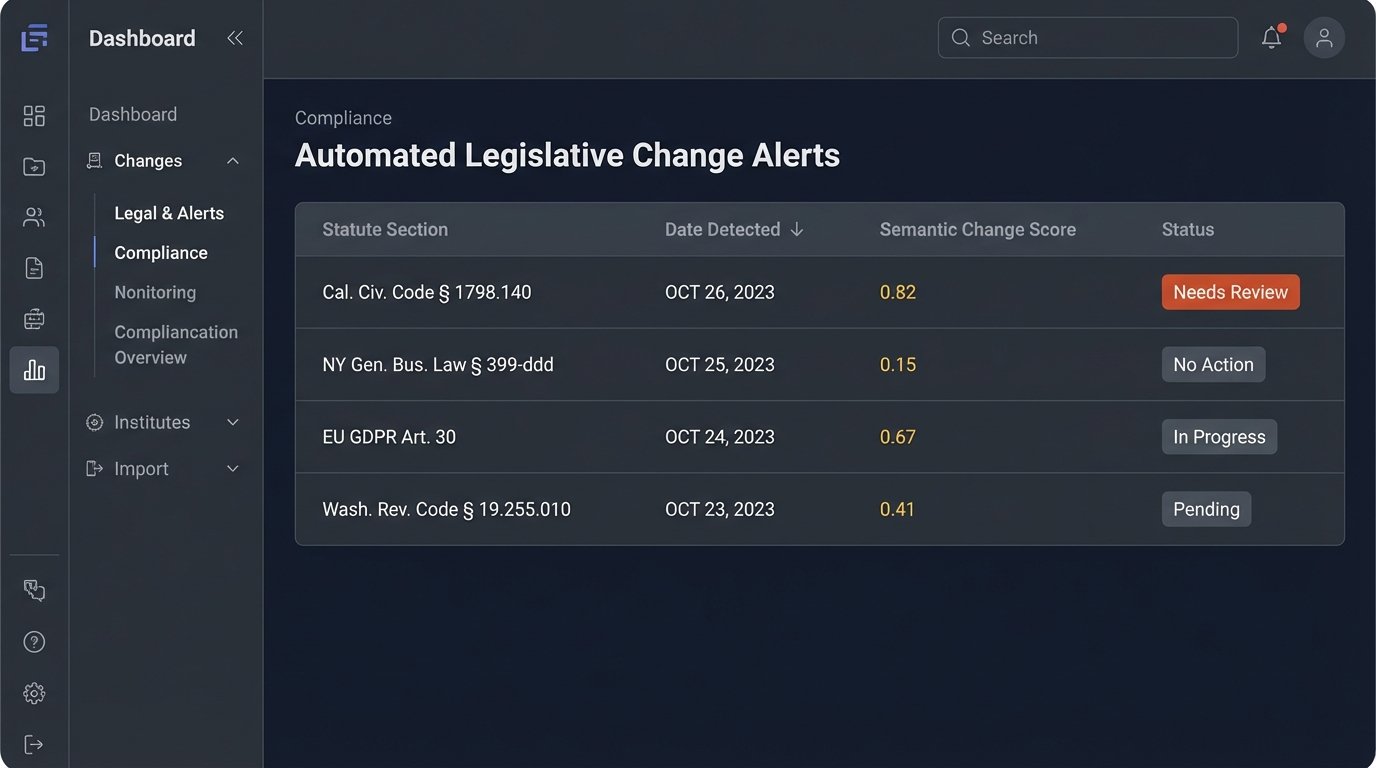
Change Detection: More Than a `diff` Command
A more intelligent approach uses vector comparisons. We generate embeddings for each section of the old statute and each section of the new one. Then, we compare the vectors. If a section is added or deleted, it is easy to spot. The interesting part is detecting modified sections. If the vector for a section in the new version has shifted significantly from its position in the old version, it indicates a semantic change. The meaning of the law has been altered.
We can calculate the cosine similarity or Euclidean distance between the old and new vectors for each section. If the distance exceeds a predetermined threshold, we flag the section for human review. This method ignores cosmetic changes and focuses exclusively on substantive modifications to the law’s meaning, drastically reducing false positives and saving attorney time.
Building the Alerting Logic
The final component is the delivery mechanism. Once a significant change is detected, the system must generate a structured alert. This should not be a simple notification. It should be a data package containing a link to the new statutory text, a redline comparison against the old version, and an AI-generated summary of the potential impact. This summary must be clearly labeled as a preliminary analysis and not legal advice.
This alert then needs to be injected into the firm’s existing workflow. This could mean creating a task in a case management system, posting a message to a specific team’s channel, or sending a formatted email to the head of a practice group. Bridging the gap to these legacy systems via their often-unreliable APIs is frequently the final, frustrating piece of the puzzle.
The Unavoidable Human Checkpoint
No part of this system eliminates the need for a qualified attorney. The entire pipeline, from ingestion to alerting, is designed to augment, not replace, human expertise. The model will make mistakes. It will misinterpret ambiguous language. It will occasionally hallucinate a connection that does not exist. The output is a highly qualified starting point for research, not the final answer.
The role of the lawyer shifts from low-level document discovery to high-level validation and analysis. The system surfaces the potential issues with speed and scale, but the lawyer must perform the final logic-check. Any firm implementing such a system must also implement a rigid quality control workflow. Trusting the output without verification is professional malpractice waiting to happen. The value is not in getting a perfect answer from a machine, but in getting a mostly-correct, fully-sourced brief in seconds instead of hours.