
The marketing pitch for AI in e-discovery is a fantasy. It sells a magic box that ingests terabytes of unstructured data and spits out a tidy, privilege-logged production set. The reality is a brutal exercise in data engineering, model validation, and wrestling with APIs that were never designed for the granular demands of litigation. The core problem is not just analyzing the data, but forcing heterogeneous electronic stored information (ESI) into a format that a machine learning model can actually process without corrupting the output.
Forget the idea of a single AI. A functional system is a brittle, multi-stage pipeline. Each stage introduces potential for error, data loss, or misinterpretation that must be aggressively logged and audited. The goal isn’t to replace human review. It is to build a system that fails gracefully and transparently, allowing reviewers to focus on documents that a machine has already flagged as computationally interesting.
Deconstructing the “AI” Label in TAR
Most platforms selling “AI-powered” e-discovery are just rebranding older Technology Assisted Review (TAR) methodologies. They primarily use a predictive coding model, often a variation of Continuous Active Learning (CAL). A senior reviewer seeds the system by coding a small set of documents as responsive or non-responsive. The model, typically a simple logistic regression or support vector machine, then scores the rest of the population based on its initial training.
This approach is fundamentally limited. The model’s entire worldview is shaped by the seed set. If the initial documents fail to capture a specific legal issue or a unique data pattern, the model will be blind to it across the entire dataset. This seed set bias is a well-documented point of failure. The model becomes very good at finding more documents exactly like the ones it was already shown, but it cannot discover novel concepts. It’s an echo chamber, not an investigation tool.
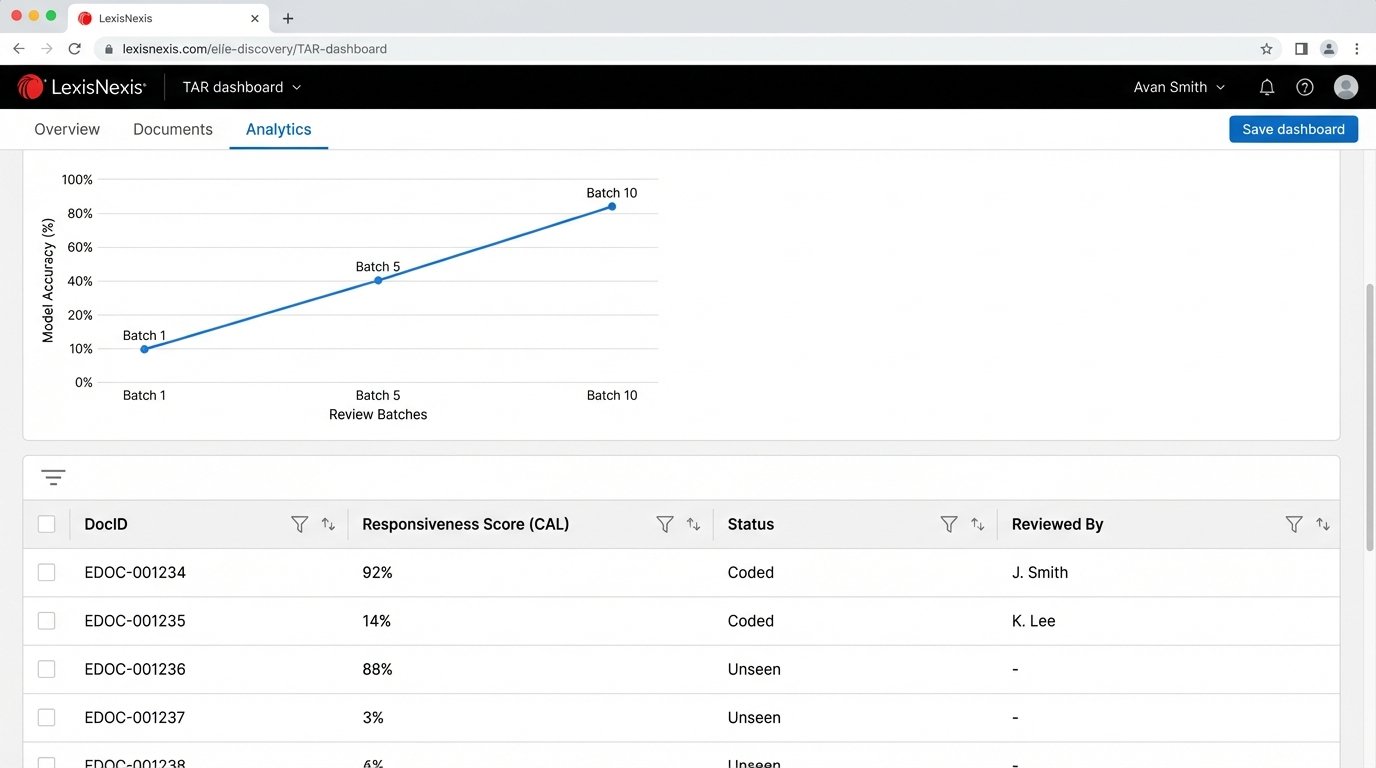
Concept drift further degrades model performance over time. As reviewers code more documents, the understanding of what constitutes “responsive” can shift. The CAL model struggles to adapt, especially if the new concepts contradict its initial training. The result is a sluggish model that requires constant, manual retraining cycles to remain even marginally effective. It is not an intelligent agent adapting to a case. It is a statistical calculator running on a fixed instruction set.
Building a Defensible Processing Pipeline
A true AI-driven workflow begins long before any predictive coding. It starts at the ingestion and processing layer. Standard e-discovery processing tools strip text and basic metadata, but this is insufficient. A modern pipeline must deconstruct every piece of ESI into its constituent parts, preparing it for multiple, specialized AI models downstream.
The first step is deep content extraction. For a PDF, this means not just running Optical Character Recognition (OCR), but running multiple OCR engines and comparing the outputs to generate a confidence score for the extracted text. For an audio file, it involves feeding it through a speech-to-text model to get a raw transcript, which is then processed for speaker diarization to identify who said what. For image files, an object detection model can identify logos, products, or specific settings relevant to the case.
This process is computationally expensive and generates a massive amount of new metadata. Each extracted piece of data, whether it is a transcribed sentence or a recognized object, must be linked back to the parent document with an audit trail. Without this, the evidence is useless and its derivation indefensible in court.
From Keywords to Knowledge Graphs
Keyword searching is a blunt instrument. It finds documents containing a word, not documents discussing a concept. To move past this, we use Named Entity Recognition (NER) models. These models are trained to identify and categorize entities like people, organizations, locations, dates, and monetary values within unstructured text. Instead of searching for “Acme Corp,” you can query for all documents mentioning any organization that communicated with a person named “John Doe” in the second quarter of 2022.
We can demonstrate a basic version of this using a library like spaCy in Python. This is not production-ready code, but it shows the core logic of extracting structured entities from a block of text.
import spacy
# Load a pre-trained English model
nlp = spacy.load("en_core_web_sm")
document_text = """
On May 1, 2023, Jane Smith from ExampleCorp sent an email to Bob Johnson
of Innovate LLC regarding the Project Alpha invoice for $50,000.
"""
# Process the text with the NER model
doc = nlp(document_text)
# Iterate through the detected entities and print them
print("Detected Entities:")
for ent in doc.ents:
print(f"- Text: {ent.text}, Label: {ent.label_}")
Executing this script would identify “May 1, 2023” as a DATE, “Jane Smith” and “Bob Johnson” as PERSON, “ExampleCorp” and “Innovate LLC” as ORG (organization), and “$50,000” as MONEY. This structured output is far more valuable than the raw text. Storing these entities allows for powerful, relational queries that are impossible with simple keyword search.
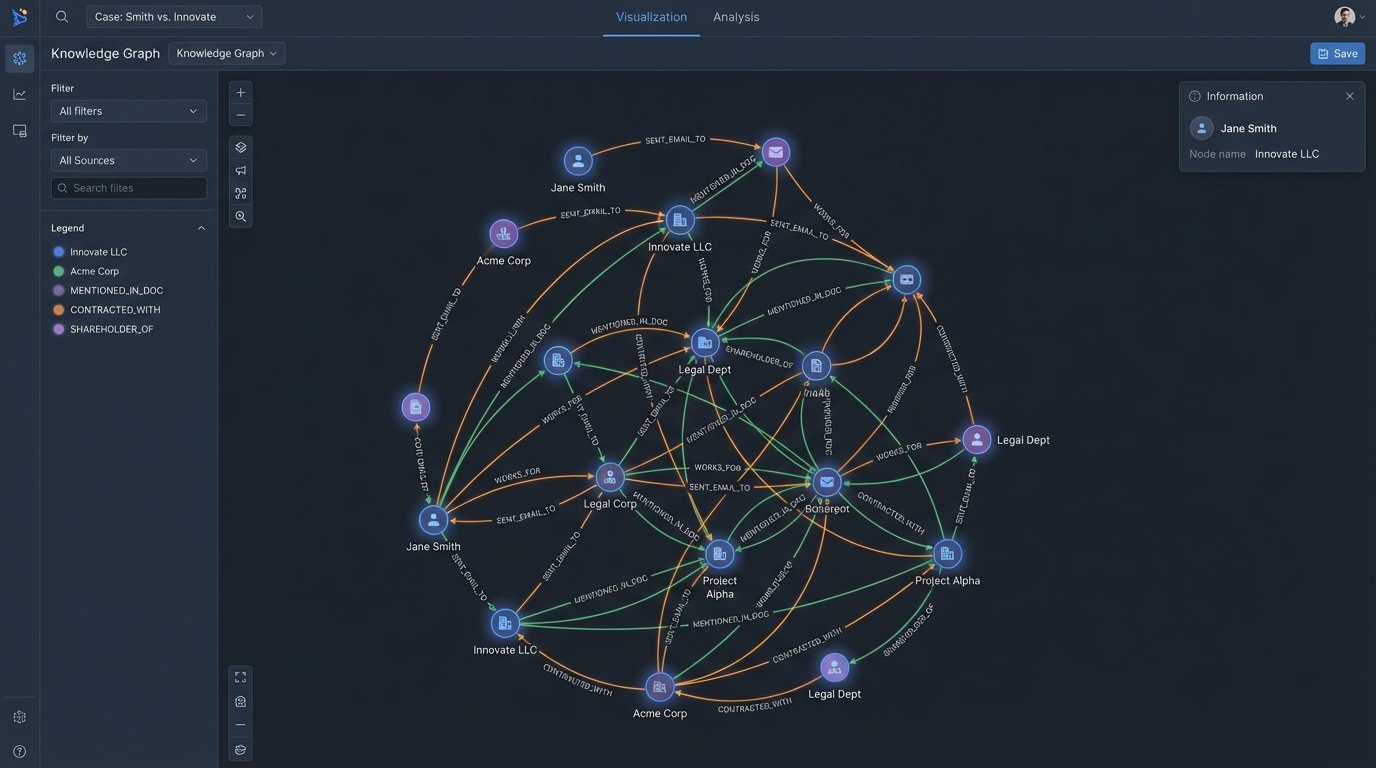
The next logical step is to build a knowledge graph. Each extracted entity becomes a node in the graph, and the relationships between them become edges. For example, an email creates an edge between the “sender” node and the “recipient” node. This visualizes the communication network, immediately showing who the key players are and how they are connected. It surfaces the “unknown unknowns” by revealing communication patterns the legal team was not aware of.
Injecting Generative Models into the Review Workflow
The recent explosion of Large Language Models (LLMs) provides new tools to accelerate review, but they also introduce new risks. These models are not databases. They are probabilistic text generators that can and do “hallucinate” or invent facts. Deploying them requires a workflow built around verification and human oversight.
One of the most practical applications is document summarization. A reviewer facing a 200-page report can use an LLM to generate a concise summary in seconds. This allows for rapid triage. The reviewer can quickly decide if the document warrants a full manual read-through. The key here is prompt engineering. A generic prompt like “summarize this document” is useless. A precise legal prompt is required, such as: “Summarize this engineering report, focusing on any mention of material stress tests, component failures, or communication with the quality assurance department.”
Another powerful use case is sentiment analysis. While not a direct indicator of relevance, a document with strongly negative or emotionally charged language is often more likely to be important. We can fine-tune a classification model to analyze the text and assign a sentiment score. This score becomes another metadata field that can be used to prioritize documents for human review. It is a crude filter, but it can effectively bubble up “hot” documents from a large population.
These generative tools are not cheap. Every API call to a provider like OpenAI or Anthropic costs money. For a multi-terabyte case, these costs can quickly spiral into the tens of thousands of dollars. The alternative, hosting and fine-tuning an open-source model in-house, trades API fees for massive infrastructure and personnel costs. There is no inexpensive option.
The Operational Burdens of Defensibility
Using any AI model in a legal context requires absolute defensibility. You must be able to stand up in court and explain exactly how a document was identified, processed, and categorized. This is impossible with a “black box” model.
Your process must be meticulously documented. For every model used, you need to record the model version, its training data, its core parameters, and its performance metrics (precision, recall, F1 score) on a validation dataset. Every single AI-driven decision, from an entity extraction to a responsiveness score, must be logged and tied to a specific document ID and a timestamp. This audit trail is non-negotiable.
The validation process itself is a major undertaking. Before deploying a model on case data, it must be tested against a “golden set” of documents that have been manually coded by senior attorneys. This establishes a baseline for the model’s accuracy. If the model’s recall for privileged documents is only 75%, it is not a defensible tool for privilege review. It might, however, be acceptable for a first-pass relevance screening where some under-inclusion is tolerated.

Trying to force unstructured ESI into a rigid AI model without this kind of granular pre-processing and validation is like trying to shove a live octopus through a mail slot. You will eventually get something through, but it will not be in one piece, you will destroy the integrity of the original item, and the result will be a mess that is unusable for any serious purpose.
The infrastructure to support this is also a wallet-drainer. Training and running modern AI models requires access to high-end GPUs. A single server with the necessary hardware can cost more than a new car. Cloud-based GPU instances mitigate the upfront capital expense but replace it with staggering hourly operational costs. Data transfer fees alone can become a significant line item on the bill.
Ultimately, AI does not simplify e-discovery. It transforms it from a human-driven process of reading documents into an engineering-driven process of building, validating, and maintaining a complex data pipeline. The firms that succeed will not be the ones that buy the most impressive-sounding “AI platform.” They will be the ones that invest in the in-house legal engineering talent required to chain these tools together in a way that is effective, auditable, and defensible.