
Manual case law research is a data integrity liability. The process is fundamentally flawed, relying on the variable attention span and keyword guessing of a junior associate at 11 PM. It’s an unscalable, unrepeatable workflow that introduces unacceptable risk before a single argument is even formed. The romantic notion of a lawyer surrounded by books is a direct path to missing the one appellate decision that guts your entire case.
Automating this process is not about convenience. It’s a direct intervention to force consistency and expand the aperture of discovery beyond human limits.
Deconstructing the Manual Bottleneck
The core failure of manual research is its serial nature. A human operator formulates a query, executes it, scans a list of results, clicks a link, reads, and then decides whether to refine the query or investigate another result. Each step is a potential point of failure due to cognitive load, interruption, or simple fatigue. An automated system bypasses this linear dependency by treating research as a parallel data extraction problem.
Instead of one query, the system can fire off a hundred permutations simultaneously against a legal data API. It doesn’t get tired. It doesn’t get distracted by an incoming email. It hammers the endpoints with structured, logical variations of a core legal question, pulling down raw case data far faster than a human can click. This is about brute-forcing the initial data collection phase to build a more complete foundational dataset for analysis.
The speed isn’t just about saving time for the associate. It’s about building a more resilient case strategy. When you can analyze ten thousand potentially relevant cases instead of two hundred, you shift from finding supporting precedent to mapping the entire precedential universe for a given issue. You start to see patterns and outlier arguments that a narrow, manual search would have missed entirely.
This approach fundamentally changes the scope of what’s possible.
API-Driven Extraction vs. The UI Prison
Working through a vendor’s web interface is intentionally limiting. The UI is designed for single-operator use, with built-in friction to manage server load. Direct API access, where available, lets you gut that front-end control layer and talk directly to the data source. We can structure calls to pull specific fields, metadata, and full-text opinions without the overhead of rendering a graphical interface.
Consider a simple task: find all tort cases in the Ninth Circuit from the last five years that cite a specific Supreme Court decision. Manually, this is a tedious, multi-step process of applying filters. With API access, it’s a single, structured GET request. We can then chain these requests, programmatically iterating through every circuit or every key decision relevant to our matter.
The initial data pull from a system like this is a firehose of text. Trying to read it all would be like trying to drink from that same firehose. The real work, and where the automation architecture proves its worth, is in the subsequent filtering and analysis stages. But without that massive initial data dump, any analysis is premature and based on an incomplete picture.
You can’t analyze data you never collected.
Forcing Relevance with Natural Language Processing
Raw search results are mostly noise. Keyword matching is a primitive tool that generates a high volume of false positives. A case might contain the keyword “liability” a dozen times but in a completely irrelevant context. This is where we inject Natural Language Processing (NLP) models to perform the initial triage that an associate would, but with machine consistency.
First, we apply Named Entity Recognition (NER) to tag and extract key concepts: names of judges, specific statutes, jurisdictions, and corporate entities. This allows us to quickly bucket cases and check if they align with the core parameters of our matter. A case that matches our keywords but involves the wrong jurisdiction can be immediately flagged and deprioritized without a human ever reading a sentence.
Next, we can use topic modeling algorithms like Latent Dirichlet Allocation (LDA) to identify the primary legal themes within a judicial opinion. The system can learn to distinguish between a passing mention of a concept and a deep, substantive discussion. This moves beyond simple keyword presence to semantic relevance, effectively asking, “What is this case actually about?”
This level of filtering is impossible to do manually at scale. An associate might read the first few paragraphs and the conclusion. An NLP pipeline reads and categorizes the entire text, weighting different sections to build a relevance score based on predefined rules. It’s a ruthless, logical check that strips out the noise so human experts can focus on the signal.
A Conceptual Query Structure
The logic isn’t magic. It’s just a structured process. Think of it as a multi-layered filtering function. The initial API call returns a large list of case objects. We then pass this list through a series of validation functions.
A simplified Python representation might look something like this:
def run_automated_research(initial_query):
# Layer 1: Brute-force data extraction from API
raw_case_list = legal_api.search(query=initial_query, max_results=10000)
# Layer 2: Initial filtering based on hard metadata
filtered_by_meta = [case for case in raw_case_list if is_valid_jurisdiction(case, "Ninth Circuit")]
# Layer 3: NLP-based relevance check
relevance_checked = [case for case in filtered_by_meta if has_substantive_topic(case, "product_liability")]
# Layer 4: Find specific citations within the text
final_candidates = [case for case in relevance_checked if cites_precedent(case, "Specific v. Precedent")]
return final_candidates
This code is a gross oversimplification, but it demonstrates the pipeline. Each stage reduces the dataset, enriching it with more specific validation until you are left with a small, highly relevant list of cases for human review. We’ve automated the grunt work of finding the needles in the haystack.
Standardizing Research to Eliminate Analyst Drift
The biggest hidden variable in manual research is the researcher. Give the same assignment to three different people, and you will get three different sets of results. This “analyst drift” stems from differences in experience, search strategy, and even the time of day the research was conducted. This is an unacceptable data integrity risk for any high-stakes legal matter.
Automation forces a standardized, repeatable methodology. The research protocol is defined in code, not in a memo. The query structures, the relevance-scoring algorithms, and the filtering logic are identical every time the process is run. This transforms legal research from an art into an engineering discipline. The output is auditable and defensible. We can show exactly which queries were run and why certain cases were flagged as relevant while others were dismissed.
This also creates a feedback loop for improvement. If the automated process misses a key precedent that was found manually, we can analyze the failure. Was the initial query too narrow? Was the NLP model misinterpreting a key concept? We can then refine the code, patching the logical gap. This iterative improvement is impossible in a purely manual workflow, where mistakes are often invisible and unrecorded.
You are replacing subjective interpretation with a deterministic system.
The Inconvenient Realities: API Throttling and Compute Costs
This approach is not without its own set of problems. The primary constraint is not technology but access and cost. Legal data providers like Westlaw, LexisNexis, and Bloomberg Law do not provide unlimited, high-speed API access for free. Their systems are built to expect human-level interaction, not thousands of programmatic requests per minute.
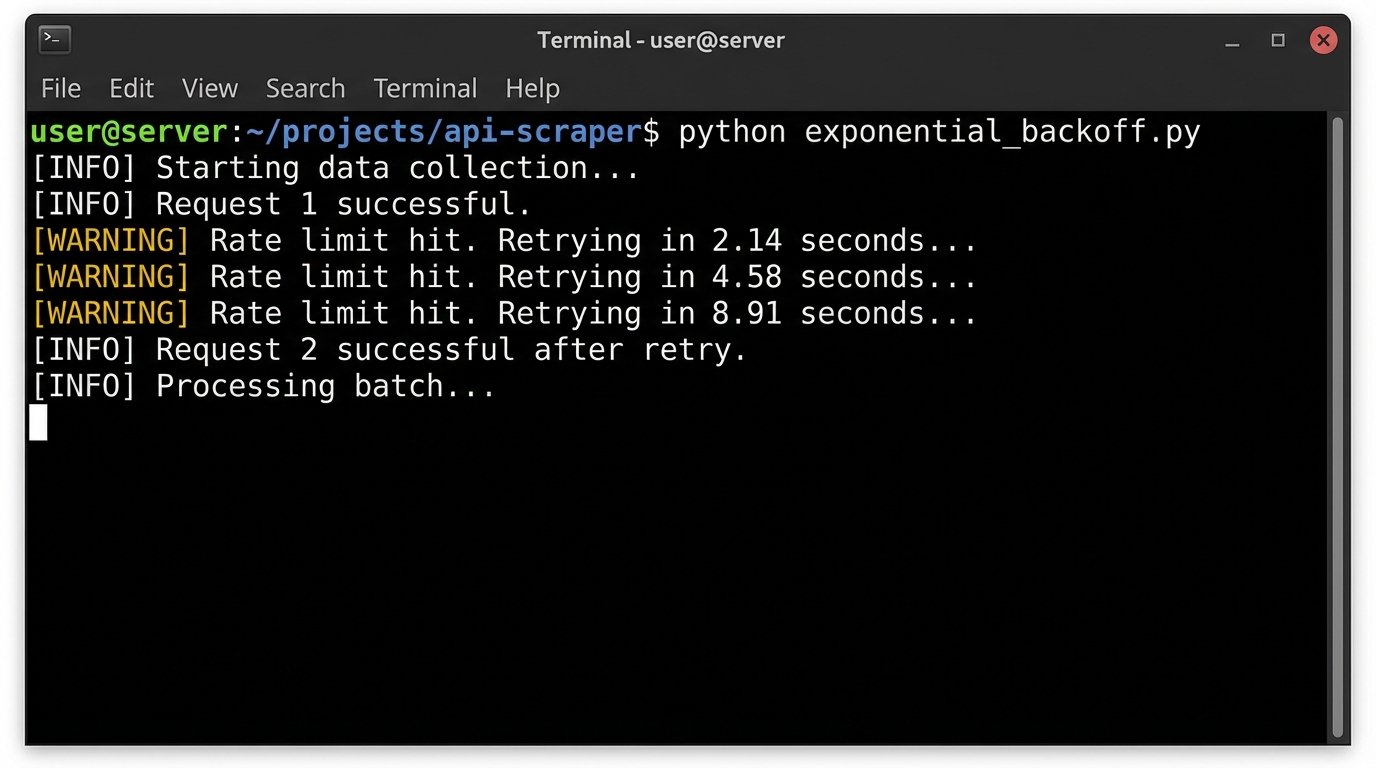
API rate limits are a constant battle. You will get hit with `429 Too Many Requests` errors. Your architecture must account for this. This means building in exponential backoff and retry logic, queuing systems, and intelligent schedulers to spread the load over time. Firing off 10,000 queries at once will just get your IP address temporarily blocked. A properly architected system feathers these requests in, respecting the provider’s limits while still maximizing throughput.
Handling Rate Limits
A naive implementation fails instantly in production. You have to anticipate API pushback.
import time
import random
def fetch_with_backoff(api_call_function, max_retries=5):
retries = 0
while retries < max_retries:
response = api_call_function()
if response.status_code == 200:
return response.data
elif response.status_code == 429:
retries += 1
# Exponential backoff with jitter
sleep_time = (2 ** retries) + random.uniform(0, 1)
print(f"Rate limit hit. Retrying in {sleep_time:.2f} seconds...")
time.sleep(sleep_time)
else:
# Handle other errors
raise Exception(f"API Error: {response.status_code}")
raise Exception("Max retries exceeded.")
Beyond throttling, there’s the direct cost. Each API call can have an associated cost, and running complex NLP models requires significant compute resources, either on-premise or in the cloud. This isn’t a cheap solution. It’s a wallet-drainer if implemented without careful resource management and optimization. The return on investment comes from efficiency gains and, more importantly, from de-risking the legal work product.
The budget conversation must happen before a single line of code is written.
Beyond Keywords: Finding Precedent with Vector Search
The most advanced systems move beyond keyword and topic analysis entirely into the realm of vector embeddings. This technique allows us to represent the semantic meaning of a document, a paragraph, or even a sentence as a mathematical vector, a series of numbers. By converting our entire library of case law into these vectors and storing them in a specialized vector database, we can perform searches based on conceptual similarity.
This means we can take the fact pattern from our current case, convert it into a vector, and then ask the database to find the top 100 most mathematically similar cases. The results are not based on shared keywords but on shared meaning. This is how you discover the non-obvious precedent, the case that uses entirely different language but addresses the exact same legal principle.
This method surfaces connections that are virtually impossible for a human to find. A human is limited by the vocabulary they can think to search for. A vector search bypasses vocabulary and operates on the underlying concepts. It’s the difference between searching for the word “car” and searching for the concept of a four-wheeled personal vehicle.
This is the current frontier of automated legal research. It’s computationally expensive and requires a high degree of technical skill to implement correctly. The models need to be fine-tuned on legal text, and the vector databases need to be managed and optimized. But for firms operating at the highest levels, it provides a significant analytical edge. It’s the closest we can get to a machine that can “understand” the law.
Failing to invest in these capabilities is not a strategic choice. It’s the slow accumulation of technical debt in the most critical function of a law firm: its ability to analyze the law.