
Manual legal research is a data retrieval process throttled by human bandwidth. The core operational drag is not the intellect required but the physical limitation of reading speed and the cognitive load of holding multiple case precedents in active memory. Automation is not about replacing judgment. It is about augmenting throughput to a scale that is mechanically impossible for a team of associates to achieve.
The objective is to shift the primary activity from search and discovery to analysis and application. A machine can brute-force the discovery process, sifting through millions of documents for a specific citation pattern or judicial phrase. This frees up the lawyer to work with a pre-filtered, highly relevant dataset. The alternative is paying a high-priced associate to perform a function that is, at its core, a complex string search.
Deconstructing the Speed Fallacy
Vendors sell speed as the primary benefit. It is a simple metric to market, but it is also the most misleading. Querying a database and returning a thousand results in two seconds is functionally useless if the 998 of those results are noise. The real engineering challenge is not query velocity but result precision. Raw speed without relevance is just a faster way to get the wrong answer.
We achieve precision by layering filters and analytical models on top of the initial data pull. A keyword search is the bluntest instrument available. A more refined approach uses semantic search capabilities, often built on vector embeddings. This technique moves beyond matching exact words to matching conceptual meaning. The system can identify a precedent about “corporate liability in infrastructure failure” even if the source document uses the phrase “a bridge collapse caused by poor maintenance.”
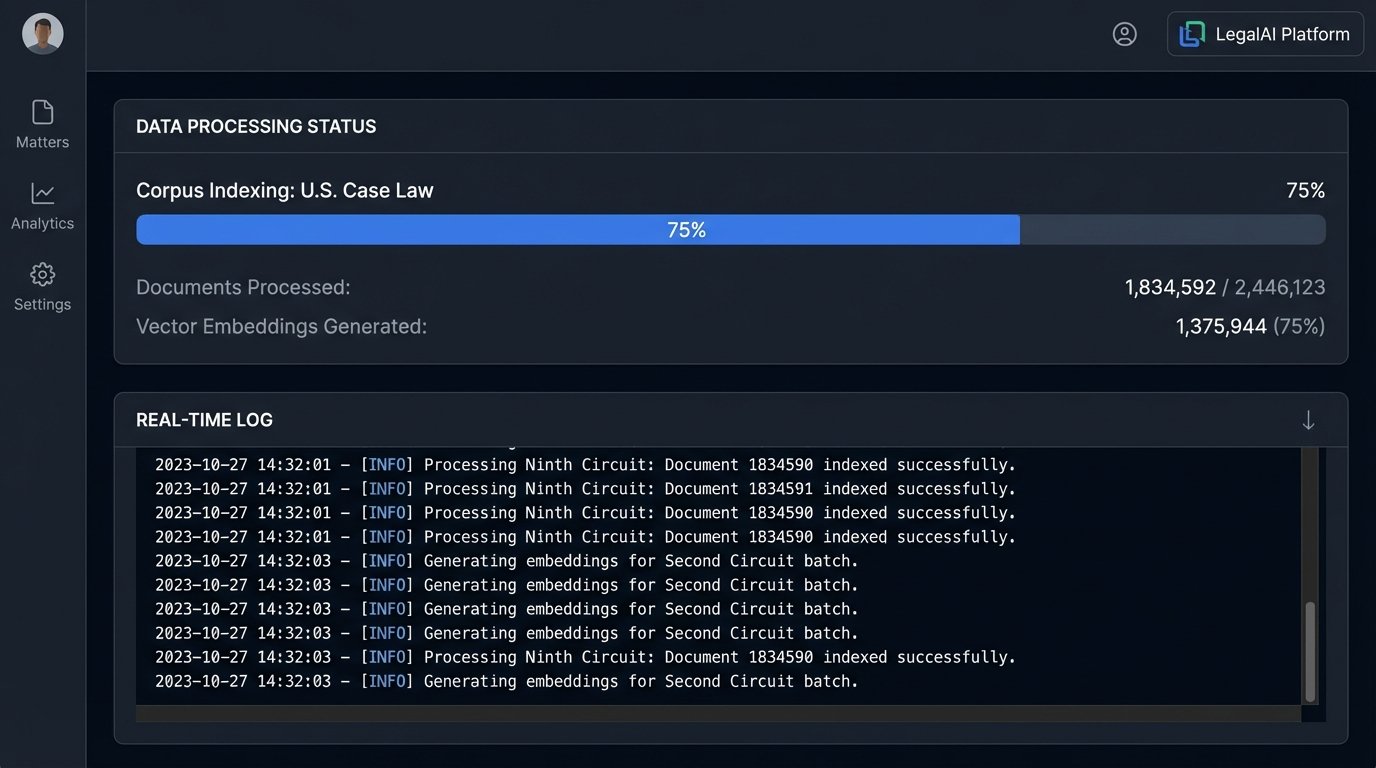
Executing this requires significant upfront data processing. You must first run the entire corpus of case law through a language model to generate these vector embeddings. It is computationally expensive. Storing and indexing these vectors demands a specialized database, not your standard SQL server. This is the hidden cost behind the sub-second search promise. Attempting to run vector searches on a conventional database is like trying to tow a freight train with a pickup truck; the architecture is mismatched for the workload.
API Integration: The Necessary Evil
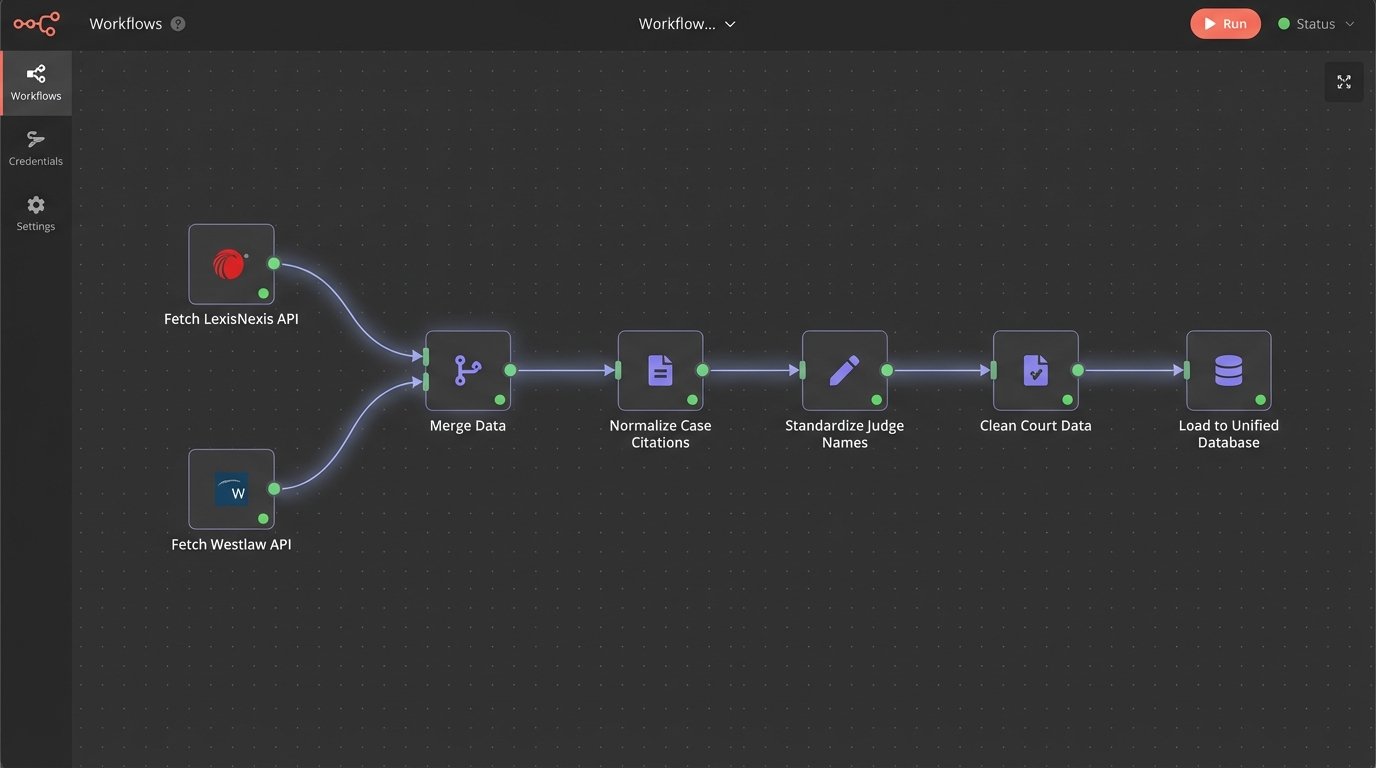
A comprehensive research platform cannot exist in a vacuum. Its value is directly proportional to the breadth of its data sources. This means bridging your internal document management system (DMS) with external APIs from providers like Westlaw, LexisNexis, and CourtListener. The goal is a single interface that can query multiple, disparate systems simultaneously and normalize the results.
The reality of this process is a mess of inconsistent API protocols, draconian rate limits, and authentication token management. One provider might use a modern RESTful API returning clean JSON, while a legacy court filing system might offer a SOAP API that spits out convoluted XML. Your job is to build an abstraction layer that shields the end-user from this backend chaos. You have to write specific connectors for each data source to strip the incoming data and force it into a unified schema.
Here is a simplified Python example of what a request to a hypothetical legal API might look like, using a common library to handle the HTTP request. Notice the need to manage an API key and structure the query parameters precisely.
import requests
import json
API_ENDPOINT = "https://api.legalsource.com/v2/cases/search"
API_KEY = "YOUR_SECRET_API_KEY_HERE"
def fetch_precedents(query_text, jurisdiction):
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
payload = {
"query": {
"bool": {
"must": [
{"match": {"text_content": query_text}},
{"match": {"jurisdiction": jurisdiction}}
]
}
},
"size": 25,
"sort": ["relevance"]
}
try:
response = requests.post(API_ENDPOINT, headers=headers, data=json.dumps(payload), timeout=10)
response.raise_for_status() # Raises an exception for bad status codes (4xx or 5xx)
return response.json()['hits']
except requests.exceptions.RequestException as e:
print(f"API request failed: {e}")
return None
# Example usage
# relevant_cases = fetch_precedents("negligence in medical device manufacturing", "CA-9")
# if relevant_cases:
# for case in relevant_cases:
# print(f"Case: {case['case_name']}, Citation: {case['citation']}")
This code does not even touch the parsing and normalization logic required to make the output from this API match the output from another. That part is ninety percent of the work.
The Data Normalization Bottleneck
Once you pull data from multiple sources, you are left with a data consistency problem. One API might format citations as “123 F. Supp. 2d 456,” while another uses “123 F.Supp.2d 456.” One system might identify a judge as “J. Smith,” another as “John P. Smith.” These small differences will break any downstream analysis if not resolved.
You must build a rigid data cleansing and normalization pipeline. This typically involves a series of regular expressions, lookup tables, and sometimes simple machine learning models to standardize entities like judge names, court names, and case citations. This is not glamorous work. It is painstaking, error-prone, and requires constant maintenance as the source APIs change without notice. Failing to do this means your unified database is just a collection of poorly organized, conflicting records.
Uncovering Patterns Humans Cannot See
The true power of automated research emerges when you move beyond simple document retrieval into large-scale pattern analysis. By structuring the unstructured text of millions of documents, you can begin to execute queries that a human researcher could not even conceive of. This is about transforming a library of books into a queryable database of legal concepts.
This process starts with Named Entity Recognition (NER). We configure models to identify and tag specific entities within the text: names of judges, law firms, expert witnesses, specific statutes, and motion types. Once these entities are tagged and indexed, you can run powerful analytical queries.
- Judicial Analytics: What is a specific judge’s reversal rate on appeals originating from a certain lower court? How often do they grant motions for summary judgment in patent infringement cases?
- Argument Strategy: Which legal arguments are most frequently successful when appearing before a particular appellate panel? Which precedents do winning parties cite most often for a specific cause of action?
- Expert Witness Vetting: How many times has a specific expert witness been disqualified under Daubert standard? Which law firms use them most frequently, and what are the outcomes of those cases?
Answering these questions manually would take months of work. A well-architected system can provide an answer in seconds. The system connects these disparate data points into a vast graph database, where cases, judges, firms, and outcomes are all nodes with defined relationships. Querying this graph reveals the hidden infrastructure of legal precedent and strategy. It is like having a blueprint of the entire legal battlefield.
Architectural Choices: Build vs. Buy and the Data Backbone
Firms face a classic engineering dilemma: build a custom solution or buy an off-the-shelf platform. Buying is faster to implement but locks you into a vendor’s ecosystem, data models, and feature roadmap. You get functionality on day one, but customization is limited, and data integration with your other internal systems can be a nightmare of closed-off APIs and proprietary formats.
Building a custom solution offers total control but requires a significant investment in engineering talent and infrastructure. You need engineers who understand both legal data and distributed systems. You will be responsible for provisioning servers, managing databases, and securing the entire application stack. This path is not for firms that view technology as a cost center.
The Central Role of the Data Store
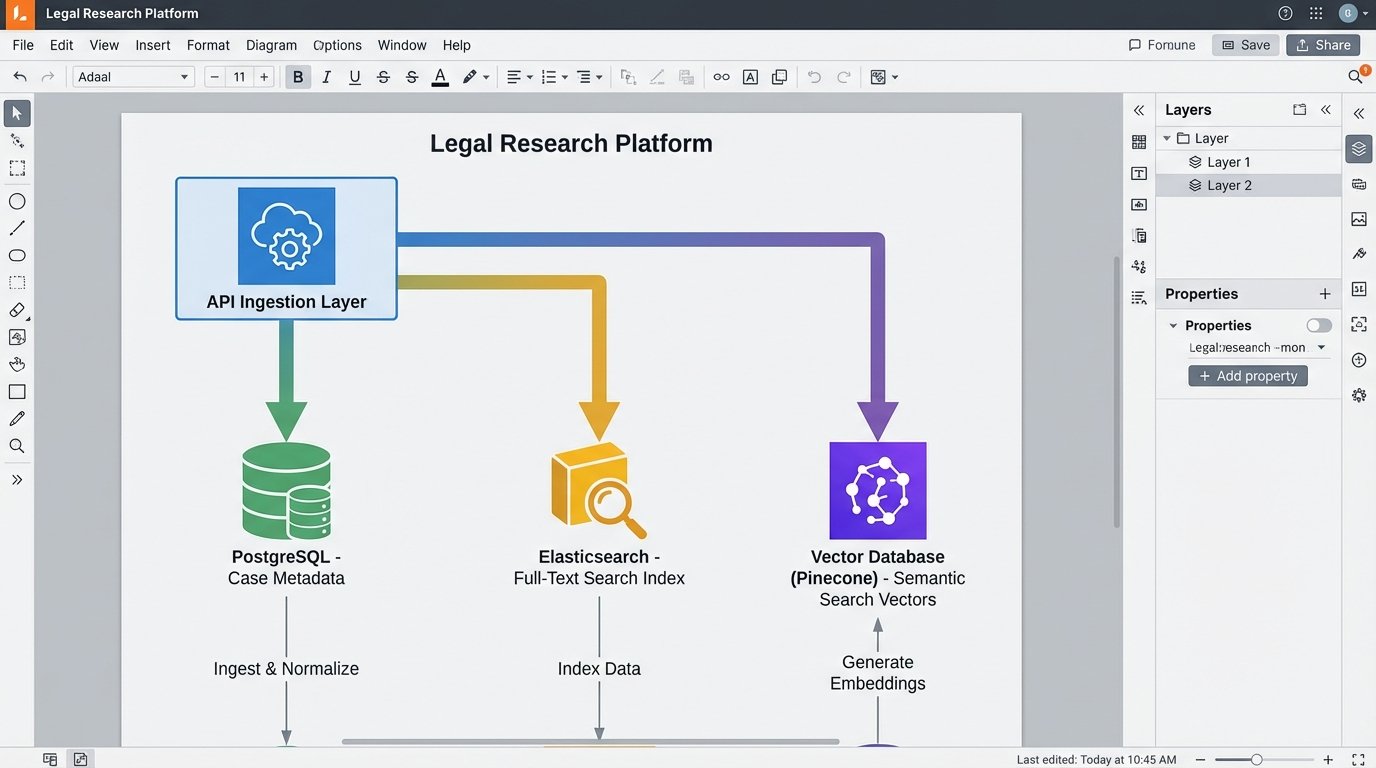
Your choice of database technology is critical. A traditional relational database (like PostgreSQL) is excellent for storing structured metadata about cases, but it is inefficient for full-text search across millions of documents. For that, you need a dedicated search engine like Elasticsearch or OpenSearch. These tools are built specifically for indexing and querying large volumes of text data at high speed.
If you are implementing semantic search with vector embeddings, you need a third type of database. A vector database, such as Pinecone, Milvus, or Weaviate, is purpose-built to perform similarity searches on high-dimensional vectors. Shoving vectors into a standard database and trying to find the nearest neighbors using SQL is a recipe for slow, non-scalable queries. Each tool has a specific job. The architecture of a robust research platform is a hybrid, using the right database for the right task.
The Human-in-the-Loop Imperative
No automated system is infallible. Language models can hallucinate, OCR can misread text, and data feeds can be corrupted. Presenting the raw output of an automated research tool to a client or a court without human validation is malpractice waiting to happen. The system is a powerful associate, not a replacement for a partner’s final judgment.
An effective workflow must include a human validation step. The system should not provide “the answer.” It should provide a ranked list of candidate answers, each with supporting evidence, confidence scores, and direct links to the source documents. The role of the attorney is to perform the final logic-check, to evaluate the nuance and context that a machine cannot grasp. The automation does the heavy lifting of finding the 10 most relevant cases out of 10 million. The human decides which 3 of those 10 actually support the legal argument.
Ignoring this final step converts a powerful analytical tool into a high-speed liability generator. The goal is to reduce error and increase efficiency, not to blindly trust an algorithm. Any firm that fails to build this validation checkpoint into their process is taking an unacceptable risk.