
Most conversations about document automation start and end with “time savings.” This is a shallow analysis pushed by vendors. The real value isn’t saving a paralegal ten minutes. The core technical benefit is forcing standardization on a system that actively resists it. We are not just making a process faster. We are fundamentally changing the data structure of the firm’s work product from unstructured text to a queryable, machine-readable format.
The default state of any legal document is entropy. A senior partner’s preferred M&A template from 2008 gets copied, modified, and saved as `MSA_final_v3_final_JDS-edits.docx`. This file’s metadata is a lie, its clauses are a patchwork of conflicting logic, and its data points are untethered from any central client record. Automation forces you to gut this process, not just accelerate it.
Data Integrity Through a Single Source of Truth
The primary engineering challenge in a law firm is not complexity, it is inconsistency. Automating document drafting forces the creation of a canonical data model. Instead of an attorney manually typing a client’s name and address into a template, the system pulls that data from a single, verified source, typically the firm’s CRM or practice management system. This is not about convenience. It is about injecting data integrity at the point of creation.
Every manual data entry point is a potential failure. A typo in a client’s name can invalidate a filing. A wrong address can delay service. An automated system fetches this data via an API call. The data is structured, predictable, and sourced from a system of record. The document becomes a validated representation of the firm’s core data, not a standalone artifact with a high probability of error.
Mapping Data to Document Fields
The technical work involves mapping structured data fields to placeholders in a template. This is the grunt work of automation. We define a schema for each document type, specifying what data points are required. For example, a simple engagement letter might require client name, address, matter ID, and billing rate. The data source, like a firm’s SQL database or a JSON object from a REST API, provides these values. The automation engine injects them into the correct locations.
Consider a simple client data object in JSON format:
{
"client_id": "C-98177",
"client_name": "Apex Innovations Corp.",
"primary_contact": {
"name": "Jane Doe",
"email": "j.doe@apexinnovations.com"
},
"address": {
"street": "123 Technology Drive",
"city": "Silicon Valley",
"state": "CA",
"zip": "94025"
},
"matter_id": "M-2024-045"
}
An automation template would contain placeholders like `{{client_name}}` or `{{address.street}}`. The engine reads the JSON, finds the matching key, and replaces the placeholder with the value. This process eliminates transposition errors and ensures the data in the document perfectly mirrors the system of record at the moment of generation. The document is no longer a static file. It is a dynamic, data-driven output.
This sounds simple. It is not. The initial data cleanup project to get your CRM to a state where it can be trusted as the single source of truth is often a six-month political and technical battle. You will discover data fields that have been used incorrectly for years.
Risk Reduction via Embedded Conditional Logic
A properly architected automation system is a risk management tool. It moves compliance from a manual checklist in a lawyer’s head to a series of logic gates built directly into the template. This prevents attorneys, especially junior ones, from making unapproved modifications or using incorrect clauses for a specific situation.
Conditional logic allows a single master template to adapt to different scenarios. An `IF/THEN/ELSE` statement can be used to include or exclude entire paragraphs based on input data. For example, if a real estate deal is in California, the template can automatically inject the state-specific disclosure clauses. If the deal value is over a certain threshold, it can force the inclusion of a higher-level indemnity clause.
Building the Decision Trees
This is where the subject matter experts, the senior lawyers, must be roped into the technical design. We sit with them and map out their decision-making process. What triggers the need for a specific clause? What data points change the language of the contract?
This process results in a decision tree that gets hard-coded into the template’s logic.
- Jurisdiction Check: `IF client.state == ‘NY’ THEN insert_ny_liability_waiver.txt`
- Value Threshold: `IF deal.value > 1000000 THEN set interest_rate = ‘PRIME + 2’`
- Party Type: `IF counterparty.type == ‘Corporation’ THEN insert_corporate_signature_block.docx`
This logic acts as a guardrail. It stops an associate in the Chicago office from accidentally using a Texas-specific provision. It ensures that the firm’s best practices are not just suggestions in a binder but are programmatically enforced at the moment of creation. The document generates itself in a pre-approved, compliant state.
The maintenance of these rules is the real long-term cost. Laws change. Firm policies evolve. Someone has to own the logic, and that person needs to be both legally and technically literate.
Decoupling Drafting from Human Availability
Manual document drafting creates a direct, linear relationship between headcount and output. To double the number of NDAs your firm can process, you have to double the number of paralegals or associates working on them. This is a fragile, unscalable model. Automation decouples this relationship by enabling systems to trigger document creation on demand, without direct human intervention.
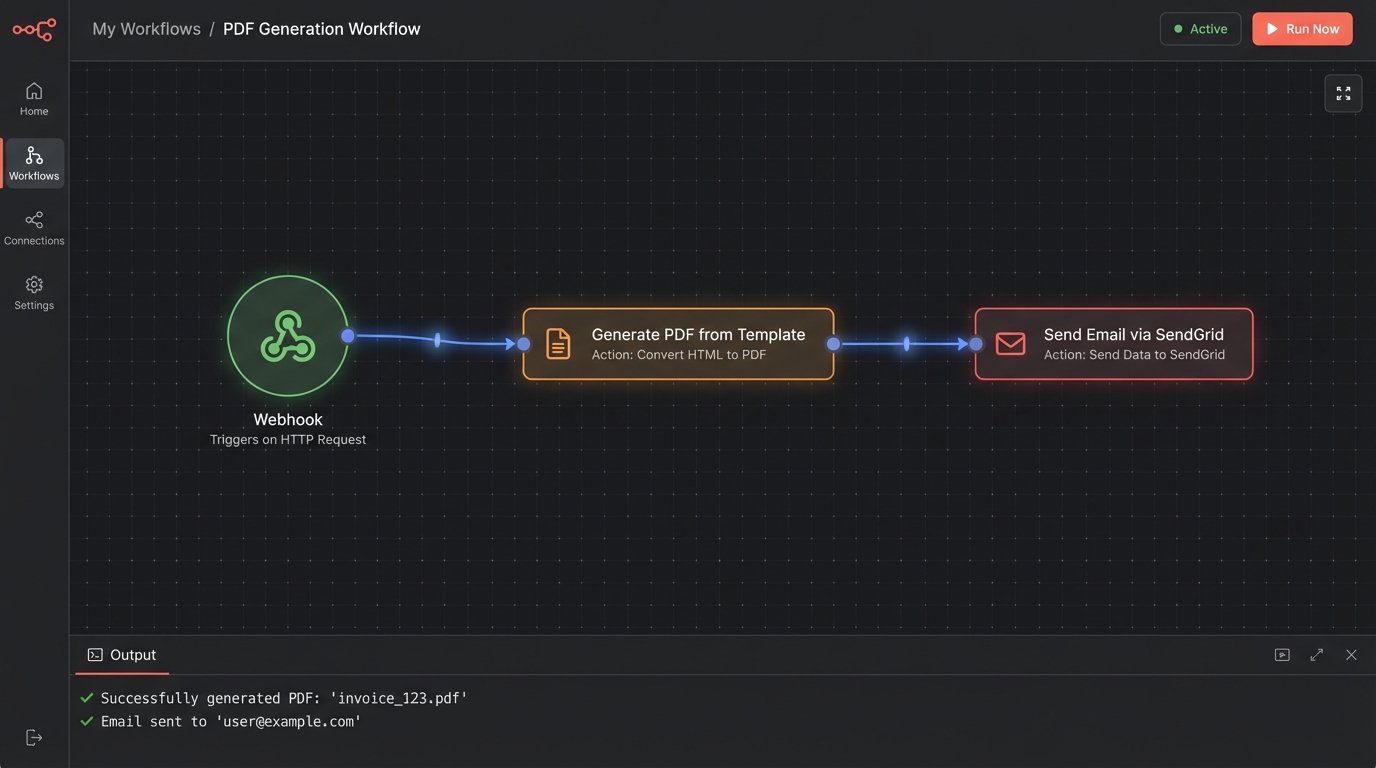
A well-built system can be exposed via an API endpoint. This means other firm systems, like a client intake portal or a case management platform, can programmatically request a document. A client fills out a web form, the data is validated, and an API call is made to the document automation engine. The engine generates the engagement letter and emails it to the client for e-signature within seconds. No human was involved.
Trying to handle this volume manually is like trying to shove a firehose of data through a needle. The manual process becomes the bottleneck, choking the entire workflow. The API-driven approach allows for massive parallel processing. The system can generate one document or ten thousand. Its capacity is limited by server resources, not by the number of available staff. This is how you handle high-volume work like class action notices or routine corporate filings.
Creating Machine-Readable Work Product
The benefit of automation extends beyond generation. Because the documents are created from structured data, they become structured assets themselves. The final output, even if it’s a PDF, has a known data schema. This transforms a firm’s document repository from a digital filing cabinet into a queryable database.
We can now run analytics against the entire body of work. How many NDAs executed this quarter had a non-standard liability clause? What is the average contract value for clients in the manufacturing sector? Answering these questions without automation requires a team of humans to manually open, read, and interpret thousands of files. It is slow, expensive, and riddled with errors.
Enabling Portfolio Analysis
With a repository of structured documents, we can build dashboards that provide near real-time insight into the firm’s legal exposure and business operations. We can track clause usage, identify negotiation trends, and flag outlier agreements that deviate from firm standards. This is critical for portfolio-level risk management, especially in areas like M&A due diligence or real estate lease abstraction.
Instead of paying a third party to review 5,000 leases to find all the force majeure clauses, a script can be run against the document database. The data was structured on creation, so extraction is a simple query, not a complex natural language processing problem. The firm is no longer just producing legal work. It is producing legal data.
The front-end dashboards are easy to sell to management. The back-end work of enforcing the metadata tagging and schema discipline to make it all possible is a constant, thankless job.
The Hidden Costs and Necessary Fights
Implementing a document automation system is not a plug-and-play solution. The technology is the easy part. The hard part is the operational and cultural change required to make it work. Vendors will not tell you about the brutal realities of a real-world implementation.
First, there is the template rationalization problem. Your firm does not have one NDA template. It has 50. Every senior partner has their own version they believe is superior. The first step is a political process to force consensus and create a single, master template for each document type. This can take months of painful meetings.

Second, there is the data quality issue. The promise of a single source of truth is powerful, but most firms’ CRMs are a mess. You will need a dedicated data hygiene project to clean and validate the source data before you can even think about connecting it to an automation engine. Garbage in, garbage out. An automation system will just produce garbage faster and at a greater scale.
Finally, there is the maintenance overhead. The rules, logic, and templates are not static. They must be updated to reflect changes in the law and firm strategy. This requires a dedicated owner or a small team with a hybrid legal-technical skillset. Without clear ownership, the system’s logic will slowly decay, becoming outdated and generating non-compliant documents. The beautiful automation engine you built becomes another piece of unmanaged and dangerous legacy tech.