
The current crop of AI-powered legal research tools are mostly just repackaged search indexes with a conversational UI bolted on top. They present a cleaner interface for querying the same databases we have had for decades. The foundational problem remains the same: the data is a mess, the APIs are brittle, and the integration points are nonexistent. The actual future of case law research is not about a better search box. It is about building the data plumbing necessary to make automated legal reasoning possible.
Deconstructing Predictive Analytics
Vendors love to throw around the term “predictive analytics.” They sell systems that supposedly predict case outcomes by analyzing past judicial decisions. In reality, these are just statistical models, often simple logistic regressions, running on top of poorly structured and incomplete court records. They identify correlations between a judge, a motion type, and a historical outcome. This is not intelligence. It is pattern matching against a noisy dataset.
The core engineering challenge is not the model itself, which is trivial to build. The problem is the data ingestion and cleaning pipeline. Court docket data is notoriously inconsistent. Different jurisdictions use different coding systems. Case dispositions are often entered as free-form text. Before any meaningful prediction can happen, you have to build a system that can ingest this chaos, normalize it, and structure it. This process, known as ETL (Extract, Transform, Load), accounts for 90% of the work and is a constant source of production failures.
Relying on these systems for high-stakes decisions is a liability. A model might tell you that Judge Smith has a 78% probability of granting a motion to dismiss in a specific type of case. This number is derived from a limited set of historical data points, none of which perfectly match the specific facts of your current case. It ignores the quality of the legal arguments, the specific nuances of the filings, and the mood of the judge that day. It is a data point, not a crystal ball.
The output is a probability vector, nothing more. A firm that builds its strategy around these predictions without a deep understanding of their limitations is just outsourcing its thinking to a black box. The real value is not in the prediction itself, but in using the underlying data to surface relevant prior cases that human lawyers can then analyze. The machine’s job is to find the needles in the haystack. The lawyer’s job is to decide which needle to use.
The Data Integrity Hurdle
Legacy case management systems are the primary source of internal data for any analytical model. These systems are often decades old, with rigid database schemas and no clean way to export data. Getting reliable data out of them requires direct database queries that can slow down the production system or custom-built connectors that are expensive and prone to breaking every time the vendor pushes an update. Trying to unify this internal data with external court records is like trying to shove a firehose of information through the eye of a needle. The formats are different, the identifiers do not match, and the timestamps are unreliable.
Building a “data lake” or a “data warehouse” is the standard enterprise solution, but this is a multi-year, multi-million dollar project. For most firms, the cost is prohibitive. A more practical approach involves building smaller, purpose-built data marts focused on specific analytical tasks, like analyzing judicial behavior in a single, high-volume jurisdiction. This approach contains the scope of the data cleaning problem and delivers value faster. It is less ambitious, but it actually works.
The Myth of the All-in-One Platform
The market is flooded with platforms that claim to be an all-in-one solution for legal research, analytics, and workflow automation. This is a marketing fiction. The legal tech landscape is composed of specialized tools that do one thing well. One vendor is good at parsing court dockets. Another has a superior database of case law. A third provides tools for analyzing contract language. The future is not a monolithic platform. It is a federated ecosystem of best-in-class services connected by APIs.
The real work of a legal automation architect is to build the connective tissue between these services. This means writing code that pulls data from the court docketing service, enriches it with case law from a research database, and then pushes it into the firm’s document management system with a summary. It is about orchestrating a workflow across multiple, independent systems.
This API-first approach requires a different skillset. It requires engineers who can read technical documentation, manage API keys, handle authentication protocols like OAuth 2.0, and write resilient code that can cope with network failures and unresponsive endpoints. A typical integration might involve a Python script running as an AWS Lambda function, triggered by a new filing event. The function calls the docketing API, then the research API, and finally the internal case management API.
Here is a conceptual example of what that orchestration logic might look like in Python, using placeholder libraries for clarity:
import docket_api
import research_api
import internal_cms_api
def process_new_filing(event):
# Step 1: Get the new filing data from the event trigger
docket_number = event[‘docket_number’]
jurisdiction = event[‘jurisdiction’]
# Step 2: Fetch detailed filing info from the specialized docket service
filing_details = docket_api.get_filing(docket_number, jurisdiction)
if not filing_details:
log_error(“Failed to fetch filing details.”)
return
# Step 3: Identify key legal issues from the filing text (placeholder logic)
legal_issues = extract_legal_issues(filing_details[‘text’])
# Step 4: Query the research API for relevant case law on those issues
relevant_cases = research_api.find_cases(jurisdiction, legal_issues)
# Step 5: Format the results and push them to the internal system
summary = format_summary(filing_details, relevant_cases)
result = internal_cms_api.add_research_memo(docket_number, summary)
if result.status_code == 200:
log_success(“Research memo created.”)
else:
log_error(“Failed to update internal CMS.”)
This code is simple, but the architecture behind it is not. Each of those API calls is a potential point of failure. The script needs robust error handling, retry logic, and monitoring to be production-ready. This is the unglamorous reality of legal automation.
Beyond Keywords: The Shift to Semantic Search
Traditional case law research is based on keyword search. You type in a few terms, and the system returns a list of documents containing those words. This is a primitive and often ineffective way to find relevant information. A judge might discuss the concept of “promissory estoppel” without ever using that exact phrase. Keyword search will miss that document completely.
The next generation of research tools is moving away from keyword matching to semantic search. This approach uses machine learning models to convert text into a numerical representation called a “vector embedding.” This vector captures the conceptual meaning of the text. When you search for “a promise that should be enforced,” a semantic search system will find documents about promissory estoppel, even if they do not contain your exact search terms. It searches for meaning, not just words.
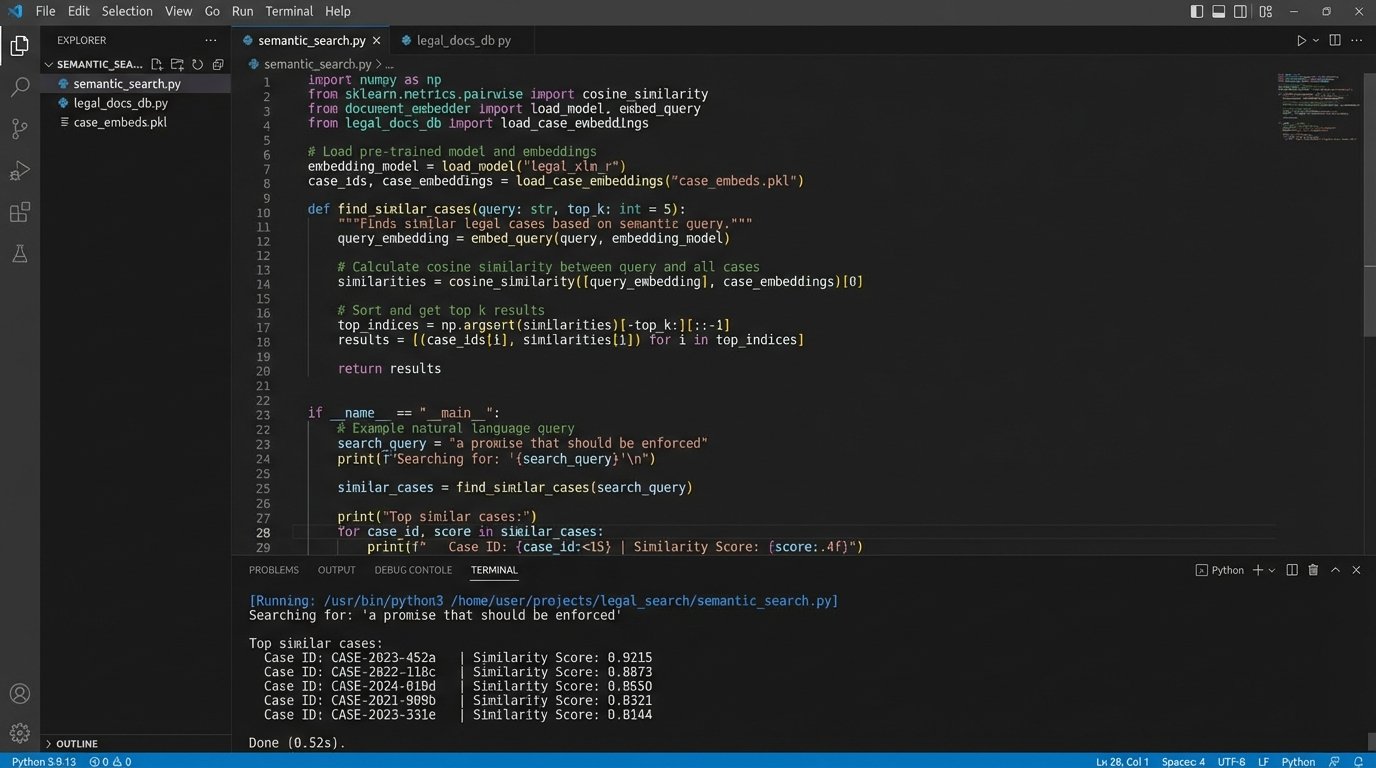
This is a powerful capability, but it comes with significant infrastructure costs. Implementing semantic search requires a specialized type of database called a vector database. These databases are designed to perform efficient similarity searches on millions or even billions of vectors. Running a self-hosted vector database is complex and resource-intensive. Using a managed service from a cloud provider is easier but can be a serious wallet-drainer, with costs scaling based on the amount of data and the query volume.
The process involves two main stages:
- Indexing: Every document in your case law database is passed through an embedding model to generate a vector. This vector is then stored in the vector database. This is a computationally expensive process that needs to be run for your entire corpus of documents.
- Querying: When a user enters a search query, the query text is also converted into a vector using the same model. The vector database then finds the vectors in its index that are closest to the query vector, using mathematical formulas like cosine similarity. These are your search results.
This technology is not magic. The quality of the search results depends entirely on the quality of the embedding model. A model trained on general web text might not understand the specific nuances of legal language. Fine-tuning these models on a corpus of legal documents is critical for achieving good performance, and it is a task that requires machine learning expertise.
The Integration Bottleneck is the Real Problem
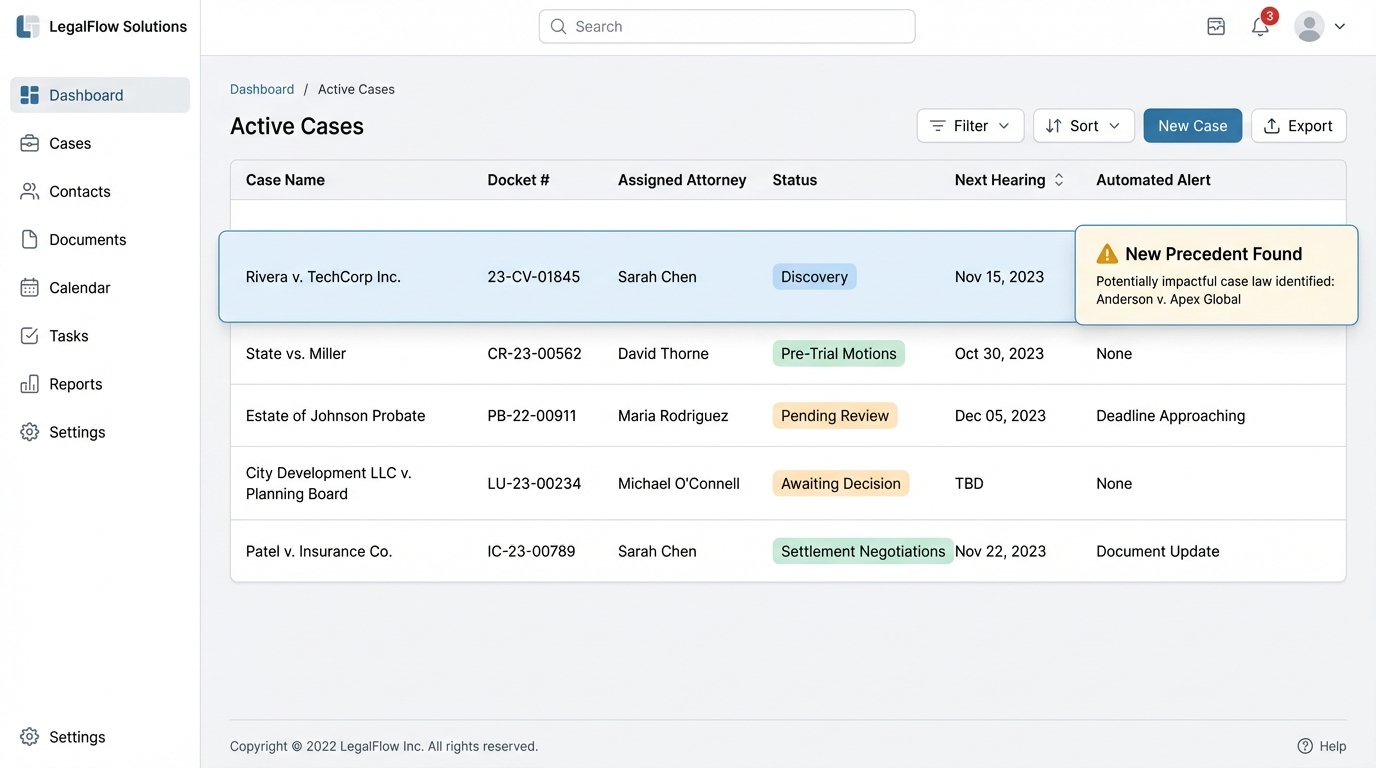
The biggest failure of most legal tech tools is their isolation. A lawyer finds a great case in a research platform, but then they have to manually copy and paste the citation and summary into their brief. A predictive model identifies a risk, but that alert lives in a separate dashboard and is never connected to the actual case file in the management system. This disconnect creates friction and kills efficiency.
The true future of legal research is not just about finding information faster. It is about seamlessly integrating that information into the lawyer’s actual workflow. When a new, potentially dispositive case is published, a system should be able to:
- Automatically identify which of the firm’s active cases are affected.
- Generate a summary of the new case and its potential impact.
- Create a task in the case management system for the responsible attorney to review the case.
- Link the new case directly to the relevant files in the document management system.
This level of integration is the holy grail. It transforms research from a standalone activity into an automated, proactive part of case management. Achieving this requires deep integration with a firm’s core systems: its case management system, its document management system, and its time and billing software. These systems, particularly older, on-premise solutions, often have limited, poorly documented, or nonexistent APIs. Building reliable integrations with them is a painful, time-consuming process of reverse-engineering and custom development.
The industry’s focus on flashy AI features is a distraction. The fundamental work ahead is to force vendors of core legal systems to adopt modern, open API standards. Without that foundation, all the advanced analytical tools in the world will remain isolated islands of data, providing insights that never translate into action.
Forget about sentient AI lawyers. The immediate future is about building robust data pipelines and forcing legacy systems to talk to each other. It is about writing the glue code that connects specialized services into a coherent workflow. This is difficult, often frustrating work, but it is the only path to building a truly automated and intelligent legal practice.