
The conversation around the future of legal client communication is polluted with marketing nonsense. We are sold visions of empathetic AI avatars and clairvoyant virtual assistants that anticipate a client’s every need. This is a fantasy. The reality is a brutal plumbing job. The next generation of communication tools are not plug-and-play accessories. They are applications that will expose the structural rot in your firm’s data architecture.
Before any AI can generate a “personalized update,” it needs clean, structured data. Without it, you are just bolting a V8 engine onto a wooden cart. The project will fail, and it will fail expensively.
Deconstructing the AI-Powered Update
Vendors promise systems that automatically draft and send case status updates. The pitch is simple. Reduce the non-billable time attorneys spend answering “what’s happening with my case?” questions. The technical reality, however, is not about the AI’s language generation capability. It is about the data you feed it. Most firms operate on case management systems that are, functionally, digital filing cabinets with terrible search functions. Critical case information is often buried in unstructured free-text fields labeled “notes.”
An AI cannot parse a partner’s cryptic sentence fragments. It needs discrete data points. Think `case_status: ‘discovery_pending’`, `next_court_date: ‘2024-11-05’`, or `discovery_requests_outstanding: 4`. Your current system likely stores this information in a PDF or a text blob that a paralegal last updated three weeks ago.
The Data Integrity Hurdle
To make automated updates work, you must first force a data discipline that most firms lack. This involves modifying your case management system or procedures to capture key milestones as structured data, not narrative prose. Every single case event, from filing a motion to receiving a discovery response, must become a machine-readable entry. This is a process change, which is a polite way of saying it’s a political battle with your own attorneys.
They will resist. They will claim structured entry is too slow and rigid. They are partially right. It is a fundamental shift from storytelling to data logging.
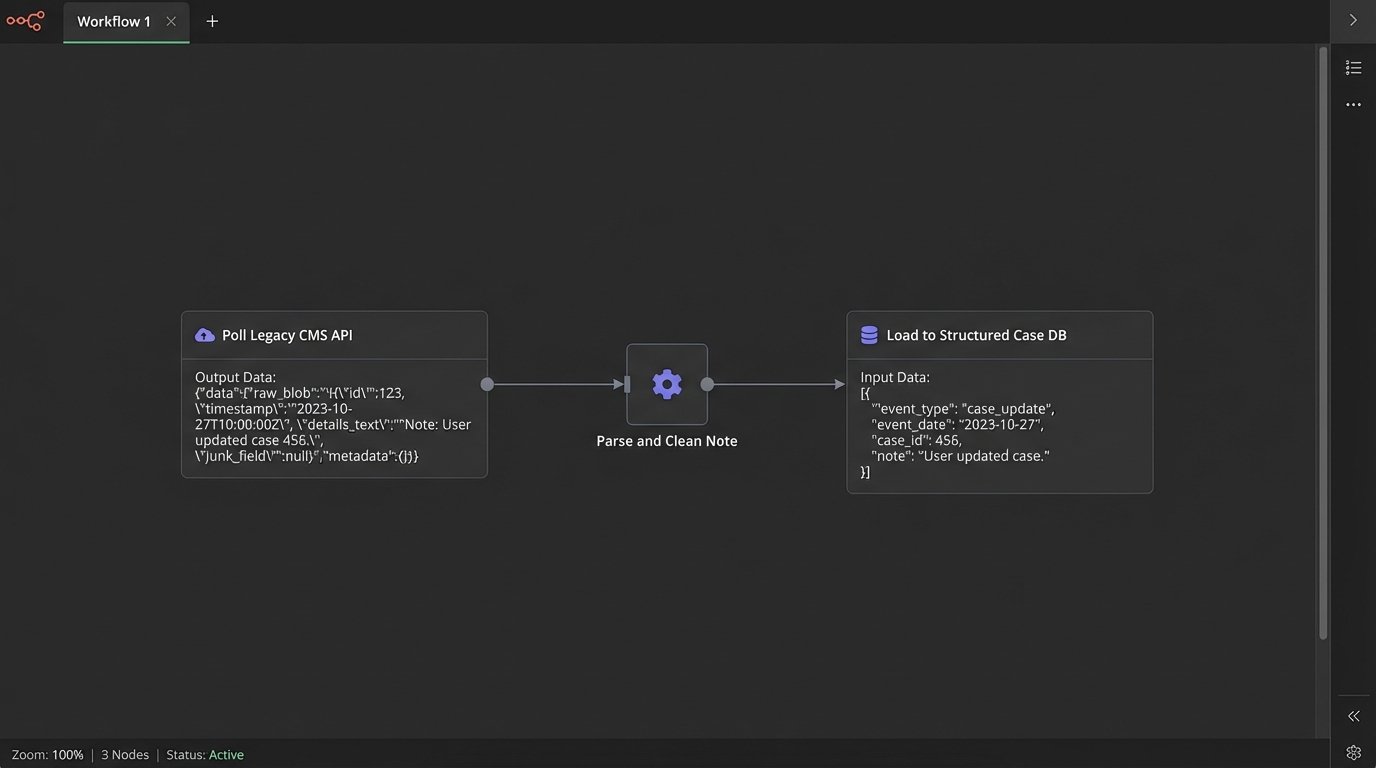
The technical task is to build a translation layer. This service continuously polls your case management API, pulls the raw, messy records, and attempts to map them to a clean, predictable schema. You will spend months writing custom logic to handle edge cases, typos, and the dozen different ways attorneys refer to the same legal event. This is not AI. This is data janitor work, and it is the absolute foundation for everything else.
Here is a simplified look at the problem. Your legacy CMS API might return a note like this:
{
"matter_id": "MAT-2023-0114",
"last_update_note": "Spoke w/ opposing counsel, J. Smith. Depo for M. Davis tentatively set for early next month, maybe the 6th? Waiting for confirmation. Also sent them the revised docs."
}
An AI has no reliable way to process this. Your translation layer needs to force this into a structured format before anything can happen. The target is to create a clean object for other services to consume.
{
"matter_id": "MAT-2023-0114",
"events": [
{
"event_type": "DEPOSITION_SCHEDULED",
"event_date": "2024-07-06",
"event_status": "TENTATIVE",
"parties_involved": ["M. Davis", "J. Smith"],
"notes": "Awaiting confirmation from opposing counsel."
},
{
"event_type": "DOCUMENT_SENT",
"document_name": "Revised Production Set",
"recipient": "Opposing Counsel",
"delivery_status": "CONFIRMED"
}
]
}
The work is not in buying the AI tool. The work is in architecting the system that generates the second code block from the first. Anyone who tells you otherwise is selling you a license, not a solution.
Virtual Assistants Are Glorified API Routers
The hype around legal virtual assistants or chatbots follows the same deceptive pattern. The demos show a slick interface on the firm’s website where a client can ask a question and get an instant, accurate answer. This demonstration is a lie. The chatbot itself is the cheapest, least complex part of the entire system. A functional chatbot is nothing more than a router for API calls.
Consider the client query: “Did you receive the documents I uploaded yesterday?” For a bot to answer this, it must execute a precise sequence of technical operations.
- Authentication: The bot must first verify the client’s identity. This requires an integration with your client portal or identity management system.
- Entity Extraction: It needs to identify the key entities in the question, specifically “documents” and “yesterday.”
- API Call to DMS: It must then construct an API call to your Document Management System, filtering for that specific client’s matter ID and a date range covering the last 24 hours.
- Response Parsing: The bot receives a response from the DMS API, which is likely a complex object or array of objects. It has to parse this response to confirm if any documents match the criteria.
- Language Generation: Only after all of that does it generate a human-readable sentence like, “Yes, we received the ‘Financial Statements 2023.pdf’ document yesterday at 3:15 PM.”
The weak link is never the bot. It is the DMS API, which is probably poorly documented, has strict rate limits, and returns inconsistent data formats. The entire process is like trying to shove a firehose of user queries through the tiny, corroded needle of a legacy API.
The Real Work Is Backend Integration
Building a useful virtual assistant is a backend integration project. You need engineers who can read years-old API documentation and write resilient code that can handle unexpected API failures. They will spend their time mapping data fields, handling authentication protocols like OAuth 2.0, and writing logic to gracefully manage API timeouts and errors. The part of the project where you “design the conversation flow” for the bot is trivial by comparison.
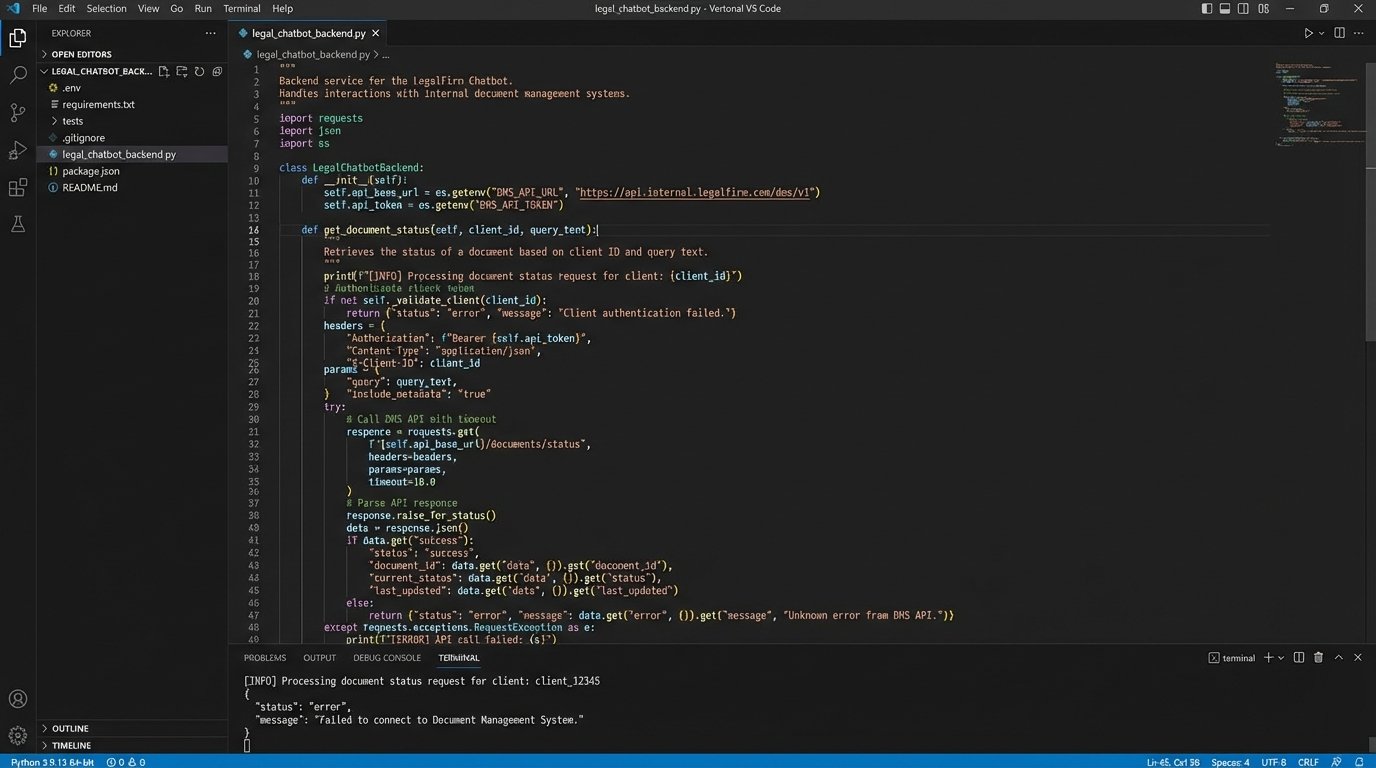
The illusion is that you are buying an AI. What you are actually funding is the creation of a middleware layer that bridges your ancient, siloed systems with a modern web interface. The chatbot is just the user-facing terminal for this much larger, more complex machine you must build and maintain yourself.
A More Realistic Architecture: The Internal Data Bus
Firms should abandon the idea of buying a single “AI solution.” This path leads to vendor lock-in and brittle, single-purpose integrations. The more durable, long-term strategy is to build an internal data bus or a centralized API layer. This is an internal service, managed by your tech team, that has one job. It connects to all of your core systems like the CMS, DMS, and billing software, and exposes a single, clean, consistent API for the rest of the firm to use.
This internal API becomes the single source of truth for case data. It smooths over the quirks and deficiencies of each underlying system. Your CMS has a bizarre date format? The internal API fixes it. Your billing system has a ten-second response time? The internal API caches the data intelligently.
Building for Modularity, Not for a Vendor
Once this data bus is in place, you gain immense leverage. Want to test a new AI-powered email tool? You connect it to your internal API, not directly to your fragile CMS. The tool fails to deliver? You unplug it without breaking five other critical workflows. Want to build a new client portal dashboard? Your developers query your clean internal API, not the swamp of the DMS backend.
This approach transforms the problem. You are no longer searching for the perfect all-in-one vendor. You are building a stable data foundation upon which you can experiment with many different tools, chatbots, and communication platforms. You can swap them out as better technology becomes available. You control your data and your destiny, not the vendor.

The cost profile also changes. The initial investment in building the data bus is higher. It requires real software engineering talent, not just a subscription fee. The long-term cost, however, is much lower. You stop paying for redundant, overpriced integration work every time you adopt a new tool. You build the connections once, and you build them correctly.
The Skillset Required Is Not What You Think
Preparing for this future has nothing to do with attending seminars on “AI in Law.” It has everything to do with hiring or training engineers who understand API design, data modeling, and cloud infrastructure. Your most valuable player will not be the person who can configure a chatbot. It will be the person who can write a Python script to clean and normalize a decade of inconsistent data from your billing system.
Firms must start thinking of their data as a product. The operations and IT departments must be restructured to support the development and maintenance of this internal product. The goal is to make your firm’s data easily and reliably consumable by other applications. If you achieve this, integrating AI-driven communication tools becomes a straightforward application development task, not a multi-year archeological dig through your legacy systems.
Stop asking which AI chatbot to buy. Start asking how you are going to build a stable API for your own case data. The first question leads to a dead end. The second question leads to a future where you can actually use the tools everyone is talking about.