
The marketing slide decks promise a future of push-button e-discovery, where artificial intelligence handles everything from collection to production. This is a fantasy. The actual future of electronic discovery is less about magical algorithms and more about sound data engineering. It’s about treating the Electronically Stored Information (ESI) lifecycle as a distributed system, complete with brittle endpoints, data integrity checks, and the ever-present specter of silent data corruption. The core challenge isn’t finding a smarter AI, it’s building a resilient pipeline that doesn’t buckle under the weight of petabytes of unstructured, messy, human-generated data.
Forget the hype. We are building plumbing, not sentient machines.
Deconstructing the TAR 2.0 Myth
Technology Assisted Review (TAR) has been stuck in a procedural rut for a decade. The standard workflow involves a static training round, a control set, and a one-time application of a predictive model to the entire document universe. This batch-processing model is fundamentally broken for modern litigation, which involves rolling productions and a constant influx of new data. The model you trained in month one is effectively stale by month three, yet review platforms encourage you to trust it implicitly.
This approach is slow, expensive, and generates a false sense of statistical security.
The necessary evolution is Continuous Active Learning (CAL). Instead of a single training event, CAL treats every single coding decision by a human reviewer as a potential training input. The model is retrained in near real-time, constantly reprioritizing the document queue to surface the most likely relevant material next. It transforms review from a linear slog into a dynamic feedback loop, where the system gets smarter with every click.
The trade-off is volatility. A CAL system is highly sensitive to the quality of its inputs. One confused reviewer consistently miscoding documents can poison the model and send the entire review down a rabbit hole. It forces a higher standard of discipline on the review team and requires project managers who can interpret the model’s behavior, not just read a recall report. We move from managing a static project to managing a dynamic learning system.
Vector Search: Moving Beyond Brute Force Keywords
Keyword searching is a relic. It’s a brute-force text-matching tool that is completely ignorant of context, intent, or semantic meaning. It finds strings, not ideas. Relying on Boolean logic to navigate a complex case is like performing surgery with a sledgehammer. You will hit the target, but you will also cause an incredible amount of collateral damage in the form of false positives and, more dangerously, false negatives.
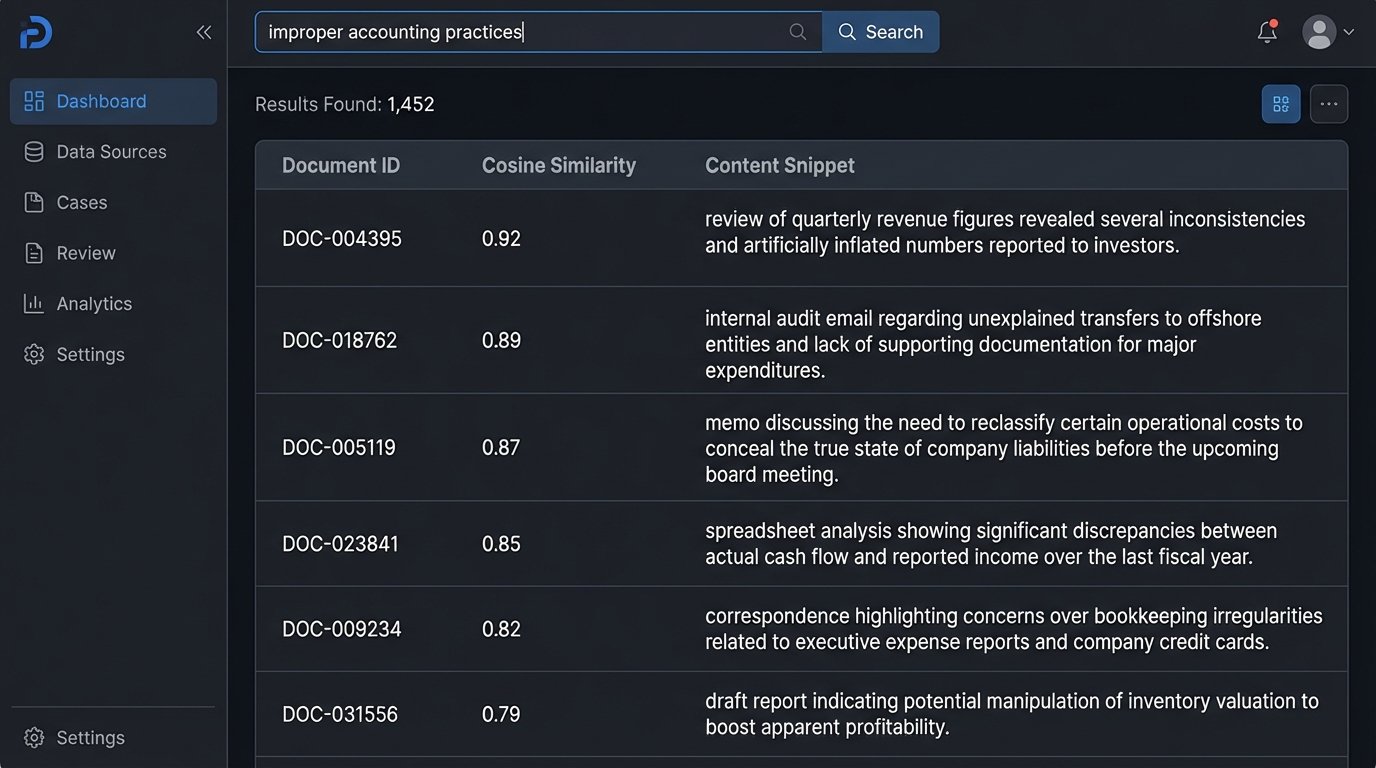
The future here is semantic search, powered by text embeddings and vector databases. Instead of indexing keywords, this approach uses a deep learning model to convert each document into a high-dimensional vector, a series of numbers that represents its conceptual meaning. The system then finds documents that are close to each other in this vector space, a concept called cosine similarity. This allows you to find documents about “financial mismanagement” even if they never use that exact phrase, but instead discuss “improper accounting,” “off-book ledgers,” or “channel stuffing.”
Implementing this is not a simple software upgrade. Trying to implement vector search on top of a legacy SQL-based review platform is like bolting a jet engine to a horse-drawn carriage. The frame will shatter. It requires a different class of infrastructure, often involving specialized vector databases like Pinecone, Weaviate, or Milvus, and the computational overhead for generating embeddings across millions of documents is significant. It’s a wallet-drainer if you don’t architect the pipeline correctly.
The Monolith Must Die: The API-First Stack
The all-in-one e-discovery platform is a prison. These monolithic systems lock your data into a proprietary ecosystem, making it difficult to integrate with other tools or build custom workflows. Exporting data is often a slow, manual process that requires babysitting a queue, and the built-in reporting tools are typically rigid and insufficient for any real analysis. You are forced to operate within the vendor’s limited imagination.
A modular, API-first architecture is the only logical path forward. The goal is to break the e-discovery lifecycle into its component parts and use best-in-class tools for each stage, connected by a fabric of well-documented APIs. Use one service for processing, another for review hosting, and a third for production analytics, all orchestrated by your own scripts. This gives you control and flexibility that is impossible within a single, closed system.
For example, instead of relying on a platform’s clunky front-end reports, you can hit its REST API to pull document metadata and coding information directly into a Power BI or Tableau dashboard. This allows for the creation of truly custom, near real-time reports for case teams. The key is to demand event-driven webhooks instead of relying on inefficient polling. Your system should be notified when a batch is done reviewing, not have to ask the server every five minutes.
Example: Basic API Data Extraction
A simple Python script can bypass a user interface entirely. The following shows a conceptual example of how to pull information about a batch of reviewed documents from a hypothetical discovery platform’s API endpoint. This logic is the foundation for building custom reporting and quality control workflows that the platform itself cannot support.
import requests
import json
API_KEY = 'YOUR_API_KEY'
API_ENDPOINT = 'https://api.ediscovery-platform.com/v1/workspaces/123/documents'
HEADERS = {
'Authorization': f'Bearer {API_KEY}',
'Content-Type': 'application/json'
}
# Query for documents coded as Responsive in the last 24 hours
query_payload = {
"query": {
"bool": {
"must": [
{"term": {"coding.is_responsive": True}},
{"range": {"coded_at": {"gte": "now-1d/d"}}}
]
}
},
"fields": ["control_number", "coded_by", "coded_at"],
"size": 1000
}
try:
response = requests.post(API_ENDPOINT, headers=HEADERS, data=json.dumps(query_payload))
response.raise_for_status() # Force an exception for bad status codes (4xx or 5xx)
documents = response.json().get('documents', [])
for doc in documents:
print(f"Control: {doc['control_number']}, Coded by: {doc['coded_by']}, Timestamp: {doc['coded_at']}")
except requests.exceptions.HTTPError as http_err:
print(f"HTTP error occurred: {http_err}")
except Exception as err:
print(f"An error occurred: {err}")
This approach gives you raw access to the underlying data, letting you build what you need instead of begging a vendor for a new feature.
Surgical Collection from Cloud Sources
Forensic collection is still dominated by an outdated paradigm: the full physical image. For on-premise servers and local hard drives, this made sense. For cloud-native applications like Microsoft Teams, Slack, or Google Workspace, it’s a completely invalid approach. You cannot “image” a Slack channel. Attempting to apply old methods results in massive over-collection of useless data or, worse, missing the relevant data entirely because it only exists via an API call.
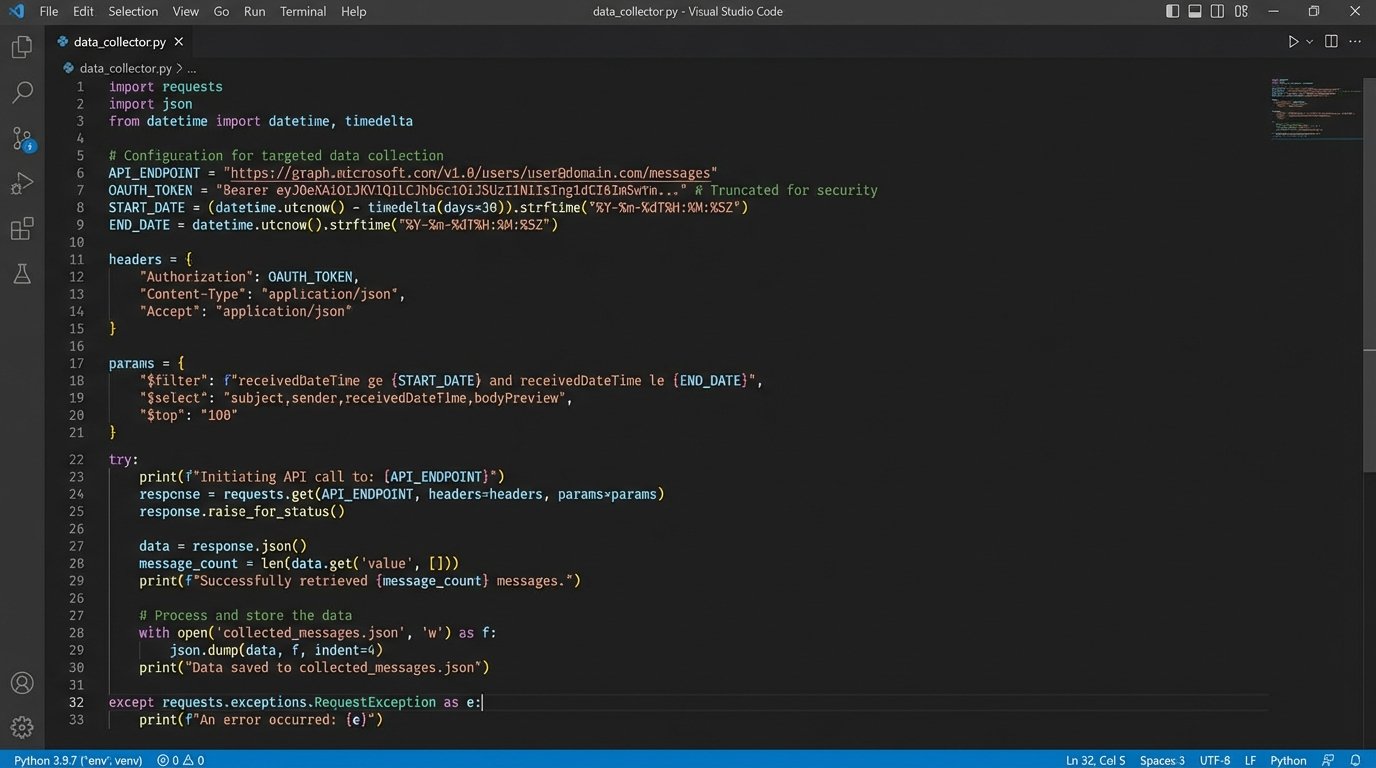
Future-state collection is surgical and API-driven. Instead of grabbing an entire MBOX file, you write a script to hit the Google Workspace API to pull emails for specific users within a narrow date range that also contain specific attachments. Instead of exporting an entire Slack channel’s history, you target the `conversations.history` endpoint for a specific thread involving key custodians. This requires a deep understanding of each application’s data structure and, critically, its authentication model, which is almost always OAuth 2.0.
The consequence is that collection moves from a forensic analyst’s job to a developer’s. Your collection tools are no longer off-the-shelf software with a GUI, but a repository of Python and PowerShell scripts. The challenge becomes maintenance. When Microsoft changes an endpoint in the Graph API, your scripts break. This is a constant, ongoing engineering effort, not a one-time purchase.
Programmatic Enforcement with Production Data Contracts
The exchange of productions between parties is a technical disaster. It relies on vague agreements documented in ESI protocols that are manually checked, if they are checked at all. This leads to endless, costly disputes over malformed load files, incorrect metadata mappings, and missing text. We argue about delimiters and date formats because the entire process is built on human trust and manual verification, both of which fail at scale.
The solution is to treat productions as a data exchange problem and solve it with data contracts. A data contract is a machine-readable definition of a production’s structure and content. It specifies the exact load file format, the required metadata fields, their data types (e.g., date must be `YYYY-MM-DD`), and the naming conventions for native and text files. This contract, perhaps a YAML or JSON file, becomes the single source of truth.
A Simple Data Contract Snippet (YAML)
Imagine a simple contract defining the structure of a standard .DAT load file. This file would be exchanged between parties before any production occurs.
# Production Specification v1.1
spec_version: 1.1
case_name: 'Acme Corp v. Widget Inc.'
loadfile_options:
delimiter: 'Concordance' # Specifies ASCII characters 20, 174, 254
encoding: 'UTF-8'
metadata_fields:
- name: 'BEGBATES'
type: 'string'
required: true
description: 'Begin Bates number.'
- name: 'ENDBATES'
type: 'string'
required: true
description: 'End Bates number.'
- name: 'CUSTODIAN'
type: 'string'
required: true
description: 'Full name of the document custodian.'
- name: 'DATE'
type: 'iso_8601_date'
required: false
description: 'Document date, formatted as YYYY-MM-DD.'
- name: 'NATIVE_LINK'
type: 'relative_path'
required: true
description: 'Relative path to the native file.'
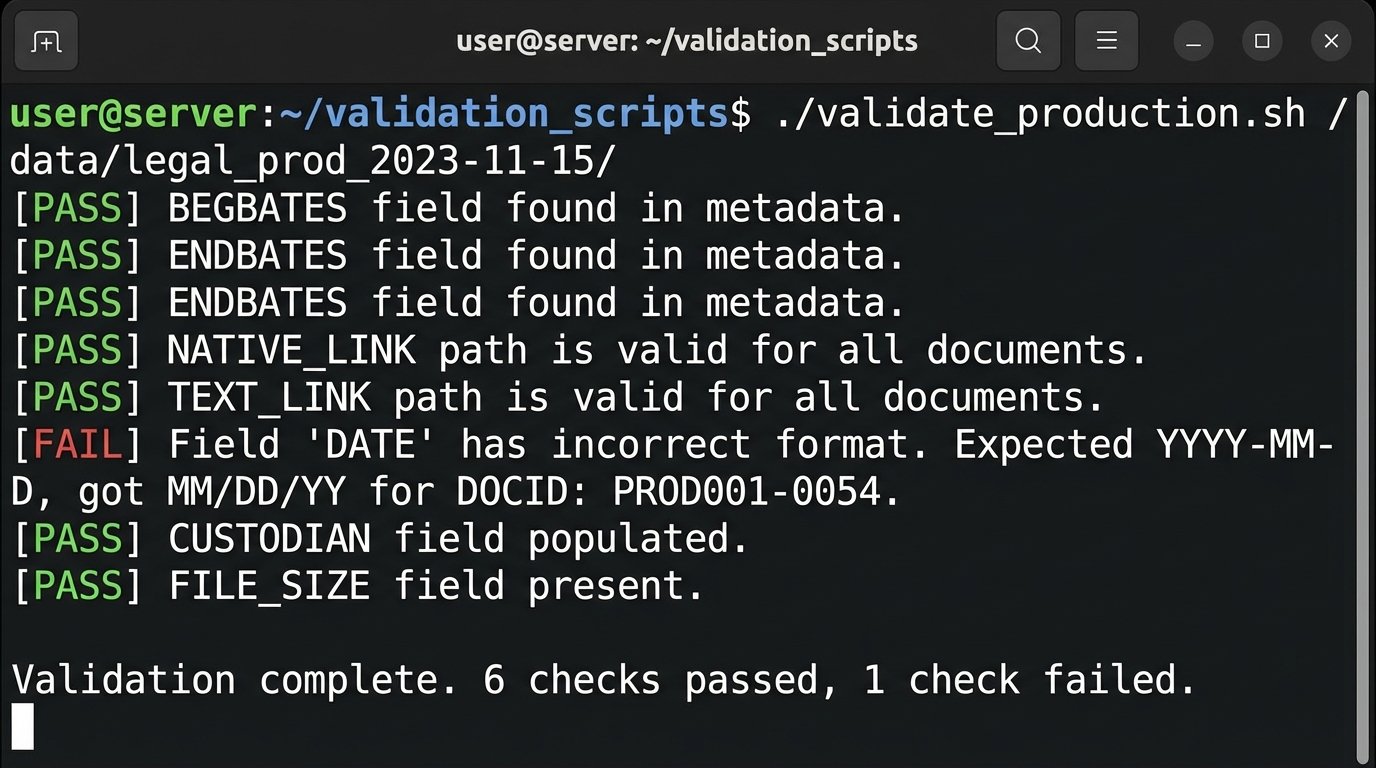
Before sending a production, the producing party runs a validation script that checks their export package against this contract. The script logic-checks for missing fields, incorrect data types, and broken file paths. The receiving party does the same upon ingestion. The conversation shifts from subjective arguments about “what we agreed to” to a simple pass or fail validation report.
The barrier is adoption. This requires bilateral agreement from opposing counsel, many of whom lack the technical staff to even understand the proposal. It represents a cultural shift from legal argument to technical verification.
Ultimately, the future of e-discovery will be defined by the firms that invest in engineering talent. The winning teams will be those who can build and maintain these complex data pipelines, who own their technology stack instead of renting a black box, and who treat ESI not as a legal document problem but as a distributed systems challenge. The rest will be left behind, buried in terabytes of unmanageable data and arguing about load file delimiters.