
The conversation around the future of legal research is broken. Vendors push natural language processing and machine learning as if they are magic wands waved over a chaotic mess of case law. They are not. The core problem is not search recall or precision. The core problem is that legal data exists as a disconnected swamp of unstructured text, and current tools are just better ways to wade through it.
Most “AI-powered” legal research platforms are fundamentally just vector search engines with a legalistic skin. They take a document or a query, convert it into a high-dimensional vector, and then find other vectors that are mathematically close in that space. This finds documents that are semantically *similar*, which is a marginal improvement over boolean keyword hunting. It is still a document retrieval system.
The real shift is not in finding documents faster. It is in ceasing to think in terms of documents at all.
Deconstructing the NLP Promise
Natural Language Processing is not a monolithic entity. In the context of legal tech, it typically refers to a stack of specific technologies. At the bottom layer, you have tokenization and sentence boundary detection, which is rudimentary. The next layer involves Named Entity Recognition (NER) to identify and tag entities like judge names, courts, corporations, and statutory citations. This part is functional, but often brittle when faced with inconsistent citation formats.
The top layer, where most of the marketing lives, is semantic search and question-answering. This is where large language models (LLMs) are bolted on. The system takes your plain-english question, searches its vector index for relevant text chunks, and then feeds those chunks to an LLM to generate a summary. This process is opaque and introduces a significant risk of hallucination, where the model fabricates case names or misinterprets holdings to fit the query.
This entire stack is built to answer a simple question: “Which document contains text that sounds like my query?” It cannot answer the more important question: “What is the relationship between Judge Smith, the Daubert standard, and patent cases in the Eastern District of Texas?” Answering that requires a structural understanding of the data, not just semantic similarity.
From Document Lists to Knowledge Graphs
The architectural alternative is a knowledge graph. Instead of storing documents, you extract and store the entities and their relationships. A case is not a block of text. A case is a node in a graph. That node is connected to other nodes representing judges, lawyers, parties, cited statutes, and other cited cases. The connection itself, the edge in the graph, is typed. It is not just “connected,” it is “affirmed,” “overturned,” “cited by,” or “presided over by.”
This model converts a library of books into a relational database of legal concepts. Searching this structure is no longer about finding keywords. It is about traversing a graph. You can execute queries that are impossible in a document-centric world. For example, a graph query can identify the single appellate judge most frequently overturned by the Supreme Court on a specific area of law over the last ten years.
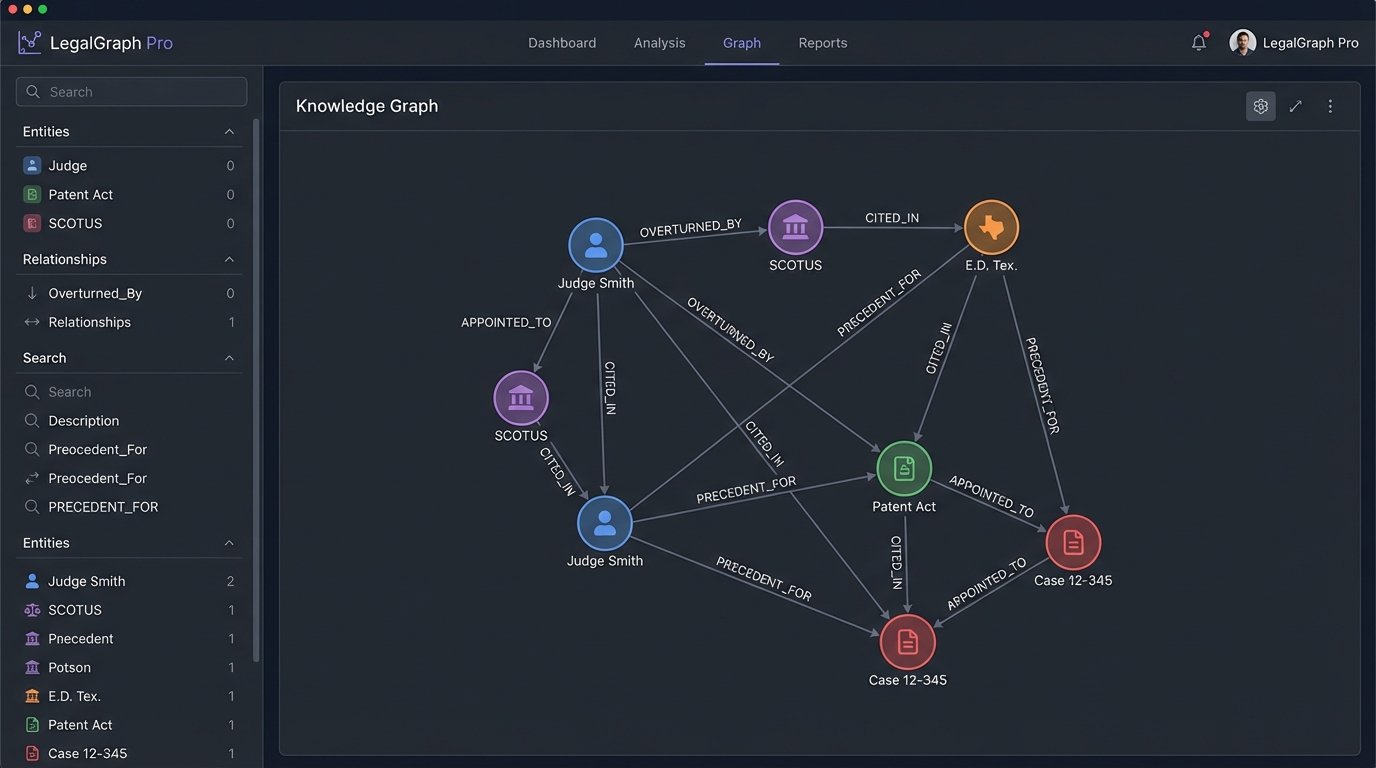
A document retrieval system could never answer that directly. You would have to run dozens of searches and manually assemble the answer from a mountain of text. The graph gives you the answer because the relationships are first-class citizens in the data model.
The Ingestion and Structuring Barrier
Building this is not a software subscription problem. It is a brutal data engineering problem. The raw material is a firehose of inconsistent, dirty data from PACER, state court e-filing systems, and internal document management systems. These sources provide PDFs and poorly structured docket entries, not clean, relational data. The work is not in the fancy AI model. The work is in the pipeline that can gut a 100-page PDF opinion, reliably extract every entity and citation, and map them into the graph structure.
This ETL (Extract, Transform, Load) process is the unglamorous 90% of the effort. You need custom parsers for dozens of different court document formats. You need robust regex for citation extraction that accounts for endless variations. You need a human-in-the-loop validation stage to correct the inevitable errors made by the NER models. Forgetting this is like designing a race car engine without considering how you will get the fuel out of the ground and into the tank.
A simplified Python snippet using a library like spaCy might start the process of identifying entities, but this is just the first step in a very long road.
import spacy
# Load a pre-trained model
nlp = spacy.load("en_core_web_sm")
# Assume 'case_text' contains the full text of a judicial opinion
doc = nlp(case_text)
for ent in doc.ents:
# This just identifies, it does not normalize or link entities
if ent.label_ in ["PERSON", "ORG", "GPE"]:
print(f"Entity: {ent.text}, Type: {ent.label_}")
This code only gets you a list of potential entities. It does not tell you if “Judge Smith” is the same person as “J. Smith” in another document. It does not link the citation “42 U.S.C. § 1983” to the actual text of the statute. That requires another layer of logic to normalize and resolve these entities against a canonical source, a process called entity linking.
The Real Cost: Talent and Infrastructure
Vendors sell a clean interface that hides the messy reality. To build a proprietary legal knowledge graph, you bypass the vendor and confront that mess directly. This is a wallet-drainer, but it is an investment in a strategic asset instead of a recurring operational expense. The cost is not in software licenses for graph databases like Neo4j or ArangoDB. Those are relatively cheap or even open source.
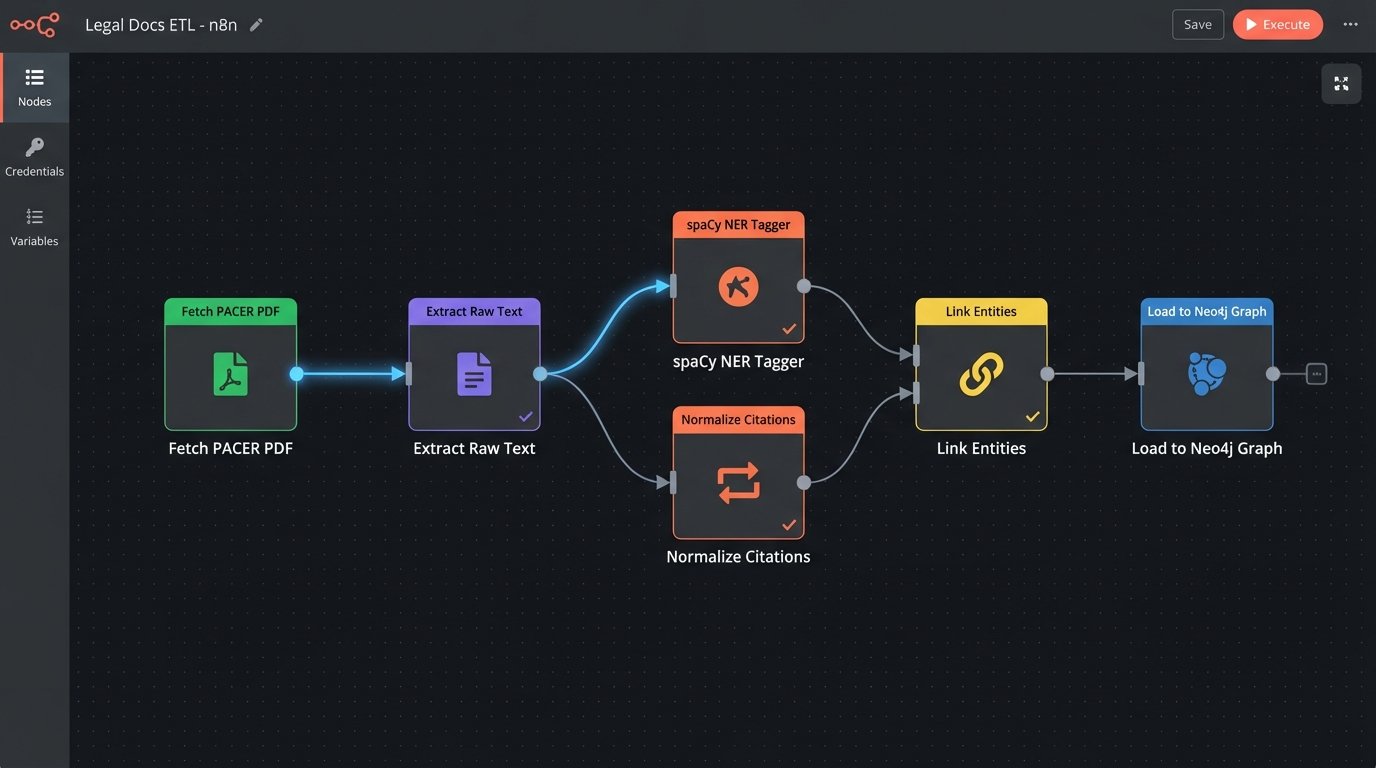
The primary cost is talent. You need data engineers who can build and maintain resilient data pipelines. You need machine learning engineers who can fine-tune NER models on your specific legal document types, not just generic web text. These are not roles you can fill with a paralegal who knows Excel macros. This is a different class of technical expertise that most firms lack.
The secondary cost is infrastructure. Processing millions of documents requires significant compute power. Storing the resulting graph and its indexes requires a robust database server. This can be run in the cloud, but it is not a trivial monthly bill from AWS or Azure. You are building a data-centric application from the ground up.
Strategic Implications of Owning Your Data Model
Why incur this cost? Because owning your knowledge graph gives you an intelligence asset no competitor can buy. A firm specializing in M&A can build a graph that maps every deal, every involved party, every material adverse change clause, and the litigation outcomes associated with them. This allows the firm to price risk and advise clients with a level of data-backed precision that is impossible with standard research tools.
A litigation firm can map the behavior of specific judges, identifying their citation patterns and the arguments they find most persuasive from specific law firms. This is not about finding a single on-point case. It is about building a quantitative, predictive model of the legal battlefield. This is the difference between having a map and having satellite reconnaissance.
This approach also frees you from vendor dependency. When a new research tool comes out, you are not evaluating a new search box. You are evaluating a new data source to feed into your existing graph. You can plug in Westlaw’s API, Lexis’s API, or any other data feed, extract the structured knowledge, and integrate it into your central intelligence engine. The vendor becomes a commodity data provider, not the gatekeeper of legal knowledge.
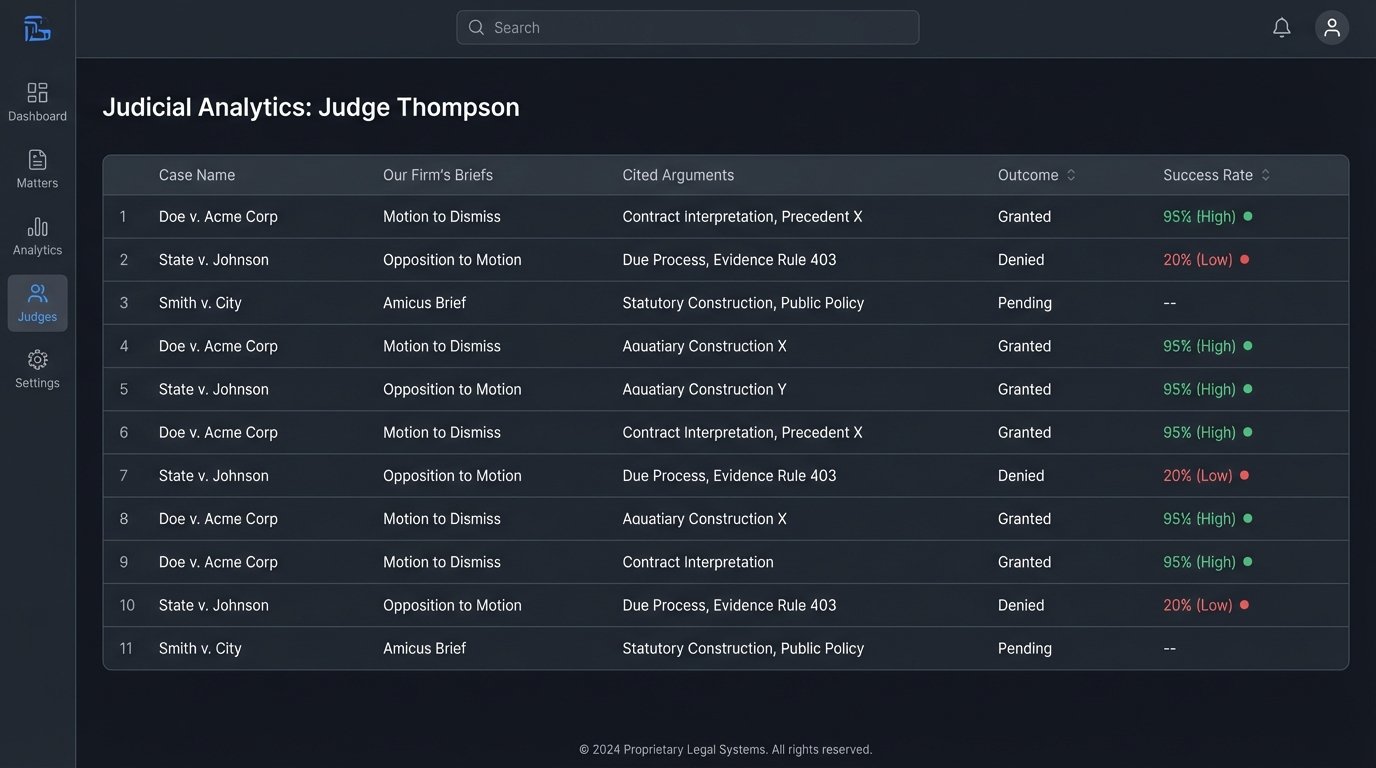
The internal system becomes the firm’s true brain. It combines public legal data with the firm’s own private work product: internal memos, briefs, and case outcomes. By mapping this internal data, you can see which of your own prior arguments were successful before a particular judge. The value of this institutional knowledge, made searchable and analyzable, is immense.
The future of legal research is not a subscription service. It is a private, firm-specific data asset. It is about transforming legal information from a collection of static documents into a dynamic, queryable network of interconnected entities. The firms that understand this and are willing to make the investment in data engineering will build an analytical advantage that the rest of the market will not be able to replicate by simply paying for a better search engine.